Repository
https://github.com/pandas-dev/pandas
New Default & Bug Fix
Pandas is a data analysis library in Python. It excels at handling tabular data... sort of like Excel for programmers. It's in the top three most popular data science packages for Python, currently with 15,000 stars and 17,500 commits.
One common task in Pandas is saving dataframes (i.e. tables) as files. There are a variety of formats that can be used to serialize tables such as CSV, TSV, JSON, and pickle. Oftentimes, the files can be quite large (if they contain lots of data). Hence, users often want to compress output files for storage on disk. Pandas supports the Big Four compression protocols: gzip, xz, bzip2, and zip.
Recently, another contributor added a compression='infer' to several of the write methods, which infers compression from filename extensions. This enabled the following:
# path-to-file.csv.xz will be xz compressed
dataframe.to_csv('path-to-file.csv.xz', compression='infer')
# Previously, one had to explicitly specify the compression
dataframe.to_csv('path-to-file.csv.xz', compression='xz')
However, much of the convenience of inferring compression is lost if the user has to go out of their way to specify inference. Therefore, I opened the issue pandas-dev/pandas#22004 proposing to change the default for the compression argument from None to 'infer'. I was expecting my proposal to be a bit controversial, because it broke backwards compatibility. However, a maintainer quickly seconded the proposal:
Reveal spoiler

So I opened the pull request pandas-dev/pandas#22011 to switch the default value for compression to infer, which I titled "Default to_* methods to compression='infer'". The first commit, which implemented the bulk of the enhancement, was simple:
Reveal spoiler
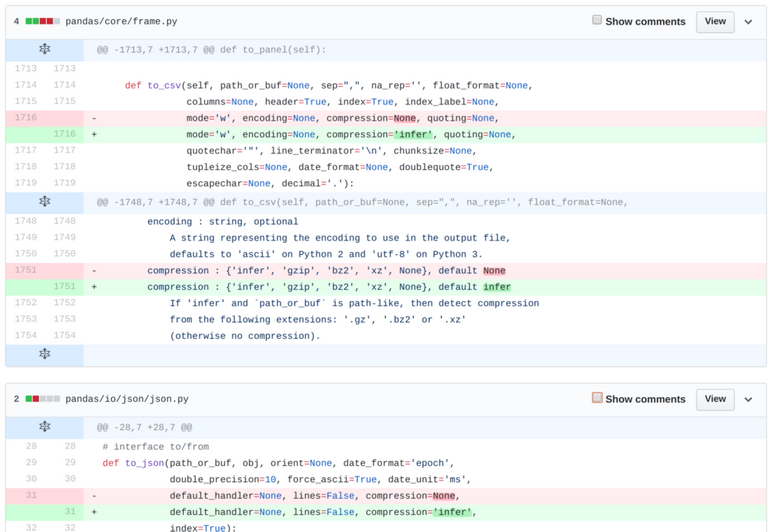
Deceptively simple in fact. One reviewer requested tests, which I thought was a bit excessive since I was just changing the default value for methods where all the possible values should already be tested. The tests ended up coming in handy however since they caught that I hadn't changed the default for Series.to_csv.
A less straightforward issue occurred where one of the Python 2.7 builds was failing, for a reason that made no sense. The test was expecting a RuntimeWarning, which should not have been affected by updating the default. More confusingly, the test picked up the expected warning in Python 3 but not 2! With help from another contributor, we tracked the issue back to a pytest bug where a prior warning elsewhere in a build causes with pytest.warns to fail to detect subsequent warnings. It turned out there was both a pytest bug and a Pandas bug, which began causing warnings in previous tests due to my PR. Once I fixed the Pandas bug, the pytest bug was no longer triggered:
Reveal spoiler
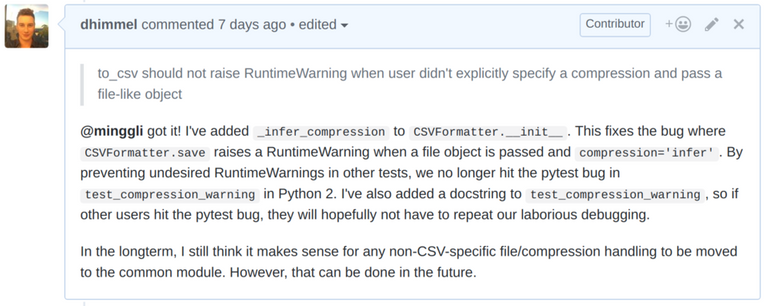
However, the PR did not end here. Various maintainers made additional requests only tangentially related to the specific scope of the PR. For example, I was instructed to move several tests to a more appropriate directory. I also took the opportunity to touch up some aspects of the codebase that could use improvement. Since Pandas has had such a long history with so many contributors, much of the code is less than ideal. Therefore, if I see an easy way to improve code that I'm touching, I think it makes sense to take the opportunity.
When all was said and done, my PR changed 10 files, added 180 lines while deleting 125, and consisted of 40 commits. It was squash merged into pandas-dev/pandas@93f154c. At times it was frustrating how long the pull request dragged on, especially since I went into it thinking it'd be as simple as flipping a switch. However, knowing that soon (as of version 0.24.0) automatic compression will be saving thousands of users time every day provided motivation to continue!
In conclusion, the following is now possible:
# path-to-file.csv.xz will be xz compressed
dataframe.to_csv('path-to-file.csv.xz')
# path-to-file.json.gz will be gz compressed
dataframe.to_json('path-to-file.json.gz')
Congratulations! I read this a few days ago and I didn't realize the significance of it until I saw on Utopian.io (which I don't often follow and it's by coincidence another fellow Vietnamese Steemian got voted for the same reason) that it was voted as one of the most significant contributions from last week. @trang has talked about you quite a bit....
Bwahaha what I never talk about @dhimmel.
Thank you for your contribution. Awesome contribution, I really liked the way you have explained the whole issue and the fix.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Write a ticket on https://support.utopian.io/.
Chat with us on Discord.
[utopian-moderator]
Thanks @codingdefined for you review! This is my first @utopian-io post to get approved. Very exciting. 🎆
Is receiving a Utopian upvote separate from getting a post approved? The interface seems to have changed since I last tried using it (now you just have to use the two leading tags) and https://utopian.io doesn't show any posts.
Check out the Bot Queue: https://utopian.rocks/queue "In Queue" means "just waiting for the Bot to upvote. :)
Thanks, that's very helpful and reassuring to know that my submission did not get lost in the void. Looks like I'm currently tenth in the queue:
Reveal spoiler
Yup, i believe the bot did not miss any article so far, even though some of them have been upvoted after 5 days. So that´s pretty close to the 7 days window - It already happened for your article :)
Interesting. I wonder if the @utopian-io voting bot software is configured to reduce the voting-power threshold should the backlog start nearing 7 days.
I could imagine an algorithm where the oldest post in the backlog determines at what power to vote. For example, if max_age < 3 days, vote at 100%. If 3 < max_age < 4 vote at 90%, etcetera. Even better could be a continuous function (rather than a step function).
Yeah, but wouldn´t that be unfair? If your post gets to the upvote bot later (because sometimes it´s just pretty full) then you get less - even though your post may be worth more in general...
@kirkins do you use @utopian-io? I was under the impression that getting your post approved would result in some sort of upvote to reward the contribution. Doesn't seem to have happened yet.
I think they have it so it waits till 100% voting power and then votes a bunch of posts all at once.
Currently the bot for Utopian contributions waits until 99.75% and then upvotes the oldest contribution in the queue. Those votes in the screenshot are for paying the moderation team and others that you will mostly see are for the innovation trail.
Great review, @dhimmel! Congrats!
Still impressed you're one of Pandas' contributors! Interesting how such an initially simple commit led to identification of weird bug. Kudos on the bug fix and other code improvement!
And what about backward compatibility?
Hey @dhimmel
Thanks for contributing on Utopian.
Congratulations! Your contribution was Staff Picked to receive a maximum vote for the development category on Utopian for being of significant value to the project and the open source community.
We’re already looking forward to your next contribution!
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!
Thanks @utopian-io! This is truly a fantastic feeling to have my open source contribution financially rewarded on the blockchain. I'm an academic scientist at the University of Pennsylvania and one issue we grapple with is how to fund open source contributions. Most traditional funding agencies like the National Institutes of Health do not yet have appropriate grant programs for sustaining open source. This is super exciting to take part in a new model for software sustainability and freedom!
A great contribution deserves to be rewarded - we are really glad to have contributors like yourself!
Congratulations on getting @utopian-io's upvote! All your hard work paid off!
This is pretty cool. I ran into issues like this before at work coding. The smallest changes can have big issues down the line, especially if there is no regression testing in place. On a similar note, one of my biggest pet peeves loosely typed languages. In the javascript example the dreaded var seems to be the cause of many bugs for lazy programmers.
IMO the ideal is optional typing. Allow the user to specify variable as desired. Therefore, you can use it for bug prevention or runtime efficiency when necessary, but avoid the overhead when its not. I hear Julia does a good job in this regard.
You are doing well. I also want to learn the Python programming language. It is very difficult? And for how long did you learn ???
I've been coding Python for 8 years. Only in the last couple years have I reached a level where I can make a substantive contribution to a large open source project like Pandas. However, contributing to OSS requires not only knowing the language, but also the open source workflow including git, testing, continuous integration, semantic versioning, documentation, etcetera.
I'd recommend Python. It's general purpose, but also a leading language for data science applications, making it a timely choice.
Thank you for the information. Good luck!
Hi @dhimmel, you have received an upvote from
trang. I'm the Vietnamese Community bot developed by witness @quochuy and powered by community SP delegations.Congratulations @dhimmel! You have completed the following achievement on Steemit and have been rewarded with new badge(s) :
Click on the badge to view your Board of Honor.
If you no longer want to receive notifications, reply to this comment with the word
STOPI like your post because you clearly explain the bugs and fix. now it's awesome.