From zero to hero
How long does it take to go from 0 to 20,000,000?
Let's check how fast we can resync and replay, because that shows how fast our system can reach the head block.
Of course, that’s not something that measures overall steemd performance. For example, a system that replays faster is not necessarily faster when it comes to serving rpc requests.
The runtime performance of API endpoints is a good topic for another episode.
Video created for Steem Pressure series.
As you may remember from episode #3, I used an entry-level dedicated machine for the purpose of my presentation:
Intel(R) Xeon(R) CPU E3-1245 V2 @ 3.40GHz on an Ivy Bridge with 32GB DDR3 1333MHz RAM and 3x 120GB SSD
Here’s the reference config file that we used back then. We will also use it now (with slight modifications depending on our needs):
p2p-endpoint = 0.0.0.0:2001
seed-node = gtg.steem.house:2001
public-api =
enable-plugin = witness
[log.console_appender.stderr]
stream=std_error
[logger.default]
level=info
appenders=stderr
That’s all that is needed to run a seed node or a witness node.
In this presentation, I continue to use v0.19.2 (with some minor patches, basically something that you will get by checking out stable)
In the previous episode, you saw the --resync process:

I was able to sync 20M blocks in slightly less than 9 hours.
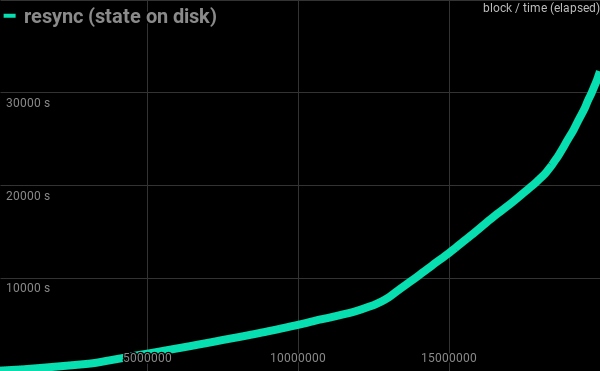
Resync of 20M blocks with state file located on disk: 539 minutes
Currently, block_log takes 110GB, so it’s quite a lot of data to process (and this amount continues to grow).
For the purpose of most of our comparisons, we will use the 20M block as a reference point, because it’s nice and round and, unlike 10M, it contains all HARDFORKs.
Once we have our block_log file, either from a previous resync operation, or we’ve downloaded it from a different instance or public source, we can save some time we would otherwise spend on --resync and perform --replay.
What’s the difference?
Resync connects to various p2p nodes in the Steem network and requests blocks from 0 to the head block. It stores them in your block_log file and builds up the current state in the shared memory file. The content of the latter depends on the plugins you use, so for example if you add the account history plugin, you will have to reindex aka replay.
Replay uses the existing block_log to build up the shared memory file up to the highest block stored there, and then it continues with sync, up to the head block.
That’s much faster, but operations on both your block_log and your shared_memory.bin without network latency in the meantime cause very intensive I/O workload for your storage.
By default, both files reside in the blockchain directory just below --data-dir, but the shared memory file can be placed elsewhere if you use the shared-file-dir option, preferably on a fast local storage device (low latency is the key) but also on a ramdisk or tmpfs.
Putting it all in RAM is the fastest solution, and you might be tempted to do so, but that’s not a viable option in the long run. Eventually, you will run out of RAM, and that will happen sooner than you think.
Fast local storage
In our setup, we are using Intel 320 Series SSDs
root@pressure:~# hdparm -t /dev/sda
/dev/sda:
Timing buffered disk reads: 750 MB in 3.00 seconds = 249.74 MB/sec
It’s not a speed monster - on the contrary, that’s a pretty old and slow SSD drive.
It was introduced in early 2011.
According to Intel:
| Sequential Read (up to) | 270 MB/s |
| Sequential Write (up to) | 130 MB/s |
| Random Read (8GB Span) (up to) | 38000 IOPS |
| Random Read (100% Span) | 38000 IOPS |
| Random Write (8GB Span) (up to) | 14000 IOPS |
| Random Write (100% Span) | 400 IOPS |
| Latency - Read | 75 µs |
| Latency - Write | 90 µs |
It looks poor compared to devices available nowadays, but I have three of them, so let’s make use of what we have
/dev/md3: 273.86GiB raid0 3 devices
root@pressure:~# hdparm -t /dev/md3
/dev/md3:
Timing buffered disk reads: 2442 MB in 3.00 seconds = 813.81 MB/sec
That’s much better.
We can now check how fast we can --replay, but to do so we need to get a block_log from somewhere, remember?
As a witness, you should have plenty of these (I have one in my pocket).
If you don’t, you have a few other options.
Each of them has its pros and cons and largely depends on your infrastructure.
Here, we test two of them:
First, download my “always up to date” file
It’s publicly available at: https://gtg.steem.house/get/blockchain/
That took 31m51s and the file is ready to use.
To get to the head block, I will have to replay it and then sync the remaining time that passed during the replay.
Then, download a highly compressed file
It’s publicly available at https://gtg.steem.house/get/blockchain.xz
That took 11m53s, but the file needs to be decompressed. Unfortunately, due to xz limitations, the can’t be done on the fly (one of the reasons I’m going to abandon it). The good thing is that it was compressed by pixz, so we can now use it with support for parallel decompression.
That took a total of 7m13s so 19m6s.
Was it worth it?
Sure!
We have saved over 10 minutes of time and 60GB of transfer.
That’s fine for our needs, but if I wanted to go to the head block, I would need to sync a few additional days that are missing from the compressed file, so in my case the break-even point is when the compressed file is two days old.
In your case, the result may vary.
But think about a situation in which your transfer speed is 5MB/s or less - you can then save 3 or 4 hours.
That, however, is a completely different story about block_log and state providers.
You need to get used to handling big files, and that takes time even when you make a local copy.
(In our case, a simple local copy within the same device took 5m49s)
Replay locally
20M blocks completed in 202 minutes.
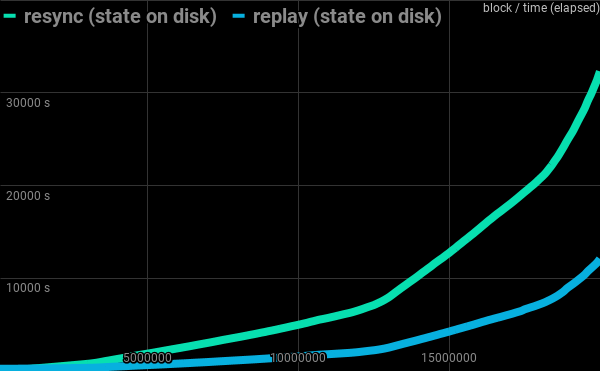
Resync vs replay of 20M blocks with state file located on disk: 539 vs 202 minutes
Important factors:
Storage latency
Low latency is the key. My rough benchmark:
steem@pressure:~$ time dd if=/dev/zero of=tst.tmp bs=4k count=10k oflag=dsync
10240+0 records in
10240+0 records out
41943040 bytes (42 MB, 40 MiB) copied, 5.11719 s, 8.2 MB/s
real 0m5.118s
user 0m0.012s
sys 0m0.544s
Size and speed of RAM
It’s not only storage that is used intensively. The size and speed of RAM also matter.
As long as your OS has plenty of RAM , it can use it effectively to optimize reads/writes.
When you are low on RAM, expect things to slow down significantly .
CPU
Due to the nature of the blockchain, steemd can’t easily make effective use of extra cores, so the faster the performance of a single core, the better.
Intel(R) Xeon(R) E3-1245 V2 @ 3.40GHz does the trick in our case.
SWAP space
If you have plenty of RAM, you don’t need it, but when you do, make sure that it’s located on a fast storage device. That will be extremely important if you decide to keep your shared memory file on a tmpfs device.
Replay using tmpfs
This is my preferred way of storing the shared memory file. It works pretty much as an oldschool ramdisk with the difference that the swap space is used as backing store in case of low memory situations.
Make sure your tmpfs device is big enough to hold your shared memory file.
I’m using /run/steem for that, so I’m resizing the underlying filesystem:
mount -o remount ,size=48G /run
Also, make sure that your shared memory file is big enough to store your state.
Currently, for a low memory node running only the witness plugin, it can be something around 40GB, so defining it for 42G in config.ini will be sufficient for now.
shared-file-size = 42G
shared-file-dir = /run/steem
The result?
20M blocks completed in 145 minutes.
Compared with 202 minutes while doing replay with the shared memory file residing on a disk and 539 minutes when doing resync.
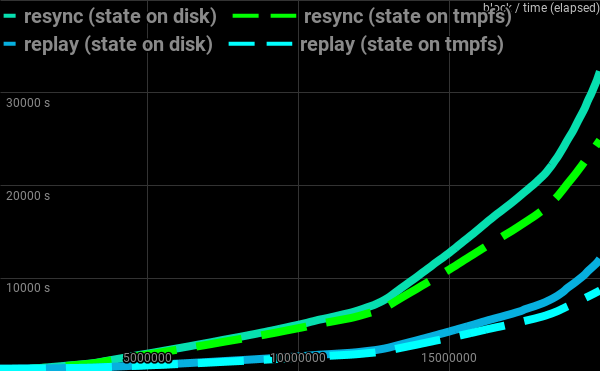
Comparison of all methods, fastest is replay with state file on tmpfs: 145 minutes
| 20 M blocks via: | resync | replay |
|---|---|---|
| with state on disk | 539 min | 202 min |
| with state on tmpfs | 415 min | 145 min |
Even looking at such simple case as a seed/witness node you can see significant difference in time needed to reach the head block, thus having fully operational node. It gets even more tricky for more complex types of nodes, running various resource hungry plugins. For example exchanges needs to run account_history plugin to track transactions to/from their account. Do they have to run Steem on a more powerful node? Is using VPS viable to run exchange node? Why it is a really good idea to pay attention to track-account-range while configuring node for exchange?
Stay tuned for next episodes :-)
If you believe I can be of value to Steem, please vote for me (gtg) as a witness on Steemit's Witnesses List or set (gtg) as a proxy that will vote for witnesses for you.
Your vote does matter!
You can contact me directly on steem.chat, as Gandalf

Steem On
Interesting. I've been dreaming of running seed node for Steemit. Your posts are certainly helpful.
Boy, am I glad we have smart peeps like you running the network! I know this will help other witnesses since saves time. Resteemed. :)
It's like magic for me... but you are my witness and proxy @gtg, I trust you :)
Thank you! :-)
Wow, was going through this post and it felt like I was going through my high school science text book . Damn , it would take a programmer to understand what's really going on in this post coz I think I am lost. Any ways I must say big ups for keeping us updated atleast .
Crazy stats!! 10 minutes time, 60GB of transfer, that's a good start?!
Although I'm not a technical guy, it really is interesting to read about it and the more I read the more I understand, but most probably I will stick to flying my drone and taking some photos and leave the smart stuff to you guys ;)
For full nodes it looks even crazier ;-)
Thanks for sharing @gtg
Amazing speed, seems you are doing great on your witness journey!
the subject is very extensive and interesting, but I do not unfortunately understand any of this nor do I have the necessary equipment!
I see why the witnesses are so important here! You will know all these things and devote most of your time to making our network better.
deserves a congratulation! @gtg
You are a great IT... nothing to say more abou your brain!!! (^_^)
Smart!
Thank you, more episodes soon :-)
Very interesting post. I like it. Good work friends.
Thanks for sharing this with the community. It always nice to read something that is done with passion.
Great idea@gtg .
I proud you are here and going such a great job .
The whole post is amazing . keep it up you have a bright mind and it will help you and help us too like this .
Excellent, this sure seems like fun😊😊😊
I want to see steem to $100 usd
Nice and tough vision there...
thanks
Upvoted and resteemed. It's a good post @gtg .
Looks pretty technical, thank you to all the witnesses for all the wonderful support you all give to make this place run as smoothly and efficiently as it does!
Can you help me to collect some money in steemit? Thaks
Sure.
Here's how: Create and curate original, high quality content.
Also, please avoid spamming, that is for example posting irrelevant comments like you just did.
Thanks for sharing @gtg, you are my witness, you are still second order as a witness in steemit. Steem On😍
now I am more motivated, thanks to this article
@gtg sir, i have vote my witness for you, even my vote means nothing,,,
i hope steemit become better and better with someone like you
Hey! I've seen some computing thing over here! I made this image with the 3D steemit logo so you can use it in your cryptocurrency posts! here's the link to my post images are clean and completely free! just make sure to upvote! have a nice one!
Interesting. Sounds very cool indeed.
Hello. The social media part is just so spot on.
Really nice read! Please check out my page and support my music guys!
Thank you for visiting.
vote for vote
No. That doesn't bring any value for the platform.
Neither low-effort generic comments such as "nice", "nice post", "i like it".
I even went to your blog to see if by any chacnce there's anything worth upvoting. No. Copied content.
I'm not flagging you this time but I strongly encourage you to re-think your activity on Steem.
Caramba, que buen Analisis..Interesante publicacion..
Thank you. Follow
The wizardry of technology knows no bounds in the hands of @gtg.
I am dumbfounded and amazed as well, wish I was close enough to you to learn directly from a master such as yourself. 1 day I know i might just get the opportunity. Cheers
Congratulations @gtg! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your Board of Honor.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last announcement from @steemitboard!
I'm happy to have you I have give you my vote
ZERO TO HERO
impressive title as well as the post is
cheerssssssssssssssss !!!
Witnessing, odd as it might be (who even admits that😁), is somewhat of a long term goal of mine. Still a ton of way to go but its great that we have guys like you that share info like this which lets anyone know whos interested in things like this, what the requirements are.
@gtg hello mr gtg how to valuefor steem.
What do you mean?
@gtg,
So, if I read that correctly it is better to have a single core that can pull its own weight rather than several that loaf about doing hardly a thing? Can't the work be delegated to specific parts of RAM?
Why not just one huge SSD instead of 3 smaller ones?
The problem is that in current blockchain architecrure you don't have much to run in parallel, so it utilize mostly single core.
I just have those good, old machines with good, old (small and slow) SSD drives. Sure, if you have bigger and faster (than those three in RAID0) use it instead.
As you explain in details it seems to good but I'm not getting how to use it for me. Actually I'm not getting a single word to use for me but as you explain it looks important. I want to know how I can use this for me. It looks littlebit technical that's why I want to know about this because if it is technical then deffinatlly it will give me something good if I'll learn how to use this for me. Please guide me. I want to know more about technology .
Hello my dear friend,I really enjoy from your blog. I recently joined to steem and saw your posts. i like art, science, adventure and photography. I upvoted and follow you, If you like, please see my posts to support each other because i need to your help for being successful for even once. have good time.
What's the point of spamming with those comments and lying?