I'm comparing some results from the dall-e mini model with others that I made with the VQGAN/CLIP combination back in November 2021.
Today let's look at "Satan by John Constable"

this is how it showed up last time. I actually quite like it. It's got a Turner meets William Blake feel to it for me but it's also got a bit of Constable's rural lanscapery to it too.
This on the other hand has much less imagination:
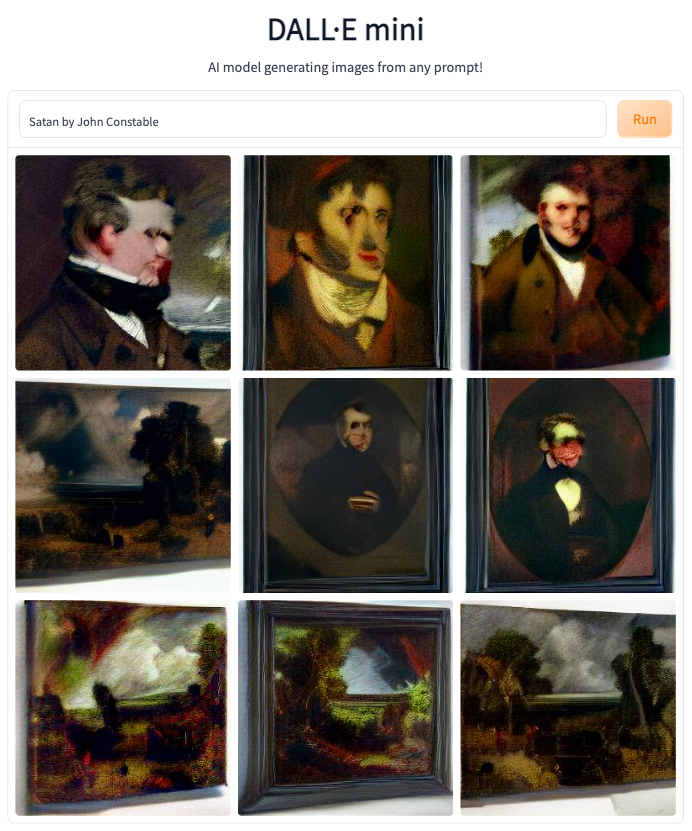
I mean they have that kind of dark Regency look, but where is Satan in all this? More deeply hidden than in the previous version, that's for sure.
Does this make it a bad model? that is the big question - what does make a good model good - how do you judge the outputs? And how do you know what has influenced the outputs without having a thorough understanding of the code in the model and the full image set on which it has been trained? For now we just have to say, these are pretty poor. I mean, if you set yourself up on something like fiverr and charged people for an image that represented a piece of text that they submitted, I think using this latest batch would get you into trouble. Customers may or may not have liked the earlier output, but it looks more like real art to me.
The Hellwain?
I’m fascinated by Dall-e ever since I heard about it on the Future of Photography podcast.
Congratulations @lloyddavis! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 73000 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!