
LBRY and the Web of Trust: A Speculative Exploration
LBRY is an interesting platform. It is not wholly one thing or another. It isn't strictly a content distribution platform nor is it specifically a social media outlet. It combines portions of both in a work which is clearly very early days in terms of where the creators want it to be.
One of the problems prevalent on the platform is an inherent tension between a top-down requirement for control of content visibility (to comply with legal requirements) and the stated (and partially implemented) desire to be a system without censorship, without central authority, and without an imposed structure.
Obviously, these two things don't really travel in the same cart – without a central authority making decisions, how can you do things like filter bad actors, whether they be spammers or people simply exploiting the system? How do you decide what content should be visible before what other content?
Why isn't that easy?
We have most of the tools necessary to attack the problem from a different direction right now.
Parts of the LBRY architecture could be repurposed or leveraged in order to begin to assemble a user-centric view of content and fellow users, and from that information to derive a "web of trust" -- a machine-understandable view of users and content which represent what a given user considers important, trustworthy, and desirable.
I've written about web of trust systems and social media networks before, but the best ones for this discussion are three articles on the subject of the Steem blockchain.
- Steemit and the Web of Trust: A Potential Love Story
- Steemit and The Dynamic of the Authoritarian in Assumption
- Steemit and the Ultimate Recourse: Blockchains For Everyone!
The first two are interesting because I go into some depth about what web of trust systems are, how they're implemented, what they look like from the inside, and the history of web of trust systems online. I'll touch on some of that content in this article, but if you want a more in-depth discussion with diagrams and step-by-step breakdowns, go check out those articles.
The third represents a radical departure in terms of systemic design from web of trust systems as they have been implemented in the past and only has limited application to the environment which LBRY provides. Not "no application," because we do have a distributed ledger system underlying part of LBRY, but it's not used in the same way as other social media blockchains. Looking at what might be done in other environments can be very useful for understanding what might be done in the current environment.
Touching Base

Everything works better defining your terms and your motivations.
Because this article is going to go out on multiple blogging platforms (the @LexTenebris channel on LBRY, @LexTenebris on the Steem blockchain, @LexTenebris on the Hive blockchain, and SquidLord on Facebook, at the very minimum), if you're interested in having an ongoing conversation about the content I strongly suggest that you create an account on Hypothes.is and create annotations regarding specific parts of the article. It is platform agnostic, runs in pretty much every browser, and allows discussion no matter where you happen to be.
If you're interested in being part of a group which discusses and is involved with annotating LBRY references across the Net, please join my Hypothes.is LBRY Annotate group and help out.
https://hypothes.is/groups/4nGxM5oz/lbry-annotate
What is LBRY?
Let's start with the basics: What is LBRY?
It's not unusual even for experienced users of LBRY not to be able to articulate exactly what LBRY is. It is so common and that the question is the absolute first thing in the FAQ.
Let's take the first few paragraphs of that answer and break it down a little bit.
For most users, LBRY will be a place where they can find great videos, music, ebooks, and more: imagine a vast digital library that is available on all of your devices. But under the hood, LBRY is many components working together.
First and foremost, LBRY is a new protocol that allows anyone to build apps that interact with digital content on the LBRY network. Apps built using the protocol allow creators to upload their work to the LBRY network of hosts (like BitTorrent), to set a price per stream or download (like iTunes) or give it away for free (like YouTube without ads). The work you publish could be videos, audio files, documents, or any other type of file.
Traditional video (or other content) sites such as YouTube, Instagram, and Spotify store your uploads on their servers and allow viewers to download them. They also allow creators to make some money through advertising or other mechanisms. However, there are some well-known drawbacks, especially for people whose material is perceived as not being advertiser-friendly.
LBRY aims to be an alternative to these sites, allowing publishers and their fans to interact directly without the risk of demonetization or other meddling.
That's a lot of words. Let's cut to the core.
First, LBRY is a Protocol – not strictly a platform. There are three platforms which are developed simultaneously which make use of the LBRY Protocol, LBRY.tv, the LBRY desktop app, and the LBRY Android app. All of those platforms are developed by and supported by the same community and organization, providing financial and management support to the developers. LBRY.tv and the LBRY apps are all different projects, all open source, and all usable by organizations interested in building their own applications which work with the LBRY Protocol.
(I absolutely agree that the naming of everything, while great for branding, is terrible for trying to make sense of who is responsible for what and why. Maybe one day in the future this will change but for now – this is what we have.)
The LBRY Protocol is two different things.
It is a distributed ledger blockchain, tasked with tracking the amount of LBC transacted by any wallet account and associated with any given piece of content which it knows how to look up. That LBC is primarily used in order to sort content when people search for it, to rank content on the front page of the website or the application, and to prioritize name claims for specific vanity names which can be followed directly from the top level namespace.
It is a content delivery system very much like other CDNs (particularly BitTorrent), capable of leveraging individual hosting by an interested third party. LBRY.tv only speaks to the content reflectors owned by LBRY Inc. for a handful of technical reasons. If you upload content through the website, it goes directly to a reflector and only to a reflector run by LBRY Inc. If you upload it through an application, you will host it yourself while it transfers to a reflector and it might be replicated more widely (by people who view your content in the application).
So when we talk about "the LBRY protocol," we are really talking about two different functional systems, one of which uses a blockchain in order to track naming and surface search content by weighting and the other which actually moves the blocks of data (referred to in the documentation as "blobs") from hosts to consumers and which does not itself use blockchain technology. The blockchain portion can be thought of as an index of addresses to content which can be looked up and consumed from the distribution portion.
All of which begs the question, "what does any of this have to do with web of trust systems?" This has the surprising answer, "nothing at all directly but it provides us a set of verbs to work with later."
We'll get into it.
What is a web of trust?
A web of trust system is a means by which a user can express their trust as regards other users and content in a given domain. Classically, it refers to a cryptographic expression of literal trust of identity keys associated with an individual or organization.
If you trust an individual key, keys in turn trusted by them have a higher level of inherited trust from you than keys which are unrelated. Keys which are trusted by two keys who you trust are considered to be more trusted than a key which is trusted by only one of the keys which you trust.
Cryptographically, this is pretty useful. It doesn't require a global knowledge of an entire network in order to determine what level of trust you should put into whether a key is associated with a trustworthy entity. When you're talking about a distributed network of private keys and public keys, it provides a straightforward way of being able to determine if you believe someone is associated with a given key.
For a much longer discussion of where this actually came from historically and why it was useful, please refer to the first article above, "Steemit and the Web of Trust: A Potential Love Story."
This is not limited to key trust. It can be generalized into a broader set of beliefs which we can assign as heritable. We will refer to those beliefs as "trust" because we trust a certain entity to represent the belief in question.
For example, let's say that I trust you to have the same tastes in content that I do. I can assign you a level of trust. That level of trust might be binary (that is, I either trust you or I don't trust you) or it could be scaler (I trust you 65% to have the same taste in content that I do). If a third-party comes along and you don't trust them, I have no opinion about them. If you do trust them, I transfer some degree of the amount of trust I have for you to them. It may be that they don't share any of my taste in content at all, at which point I can explicitly tell the system that they have zero trust and any degree of inherited trust from you won't matter.
A web of trust system exists to propagate value through a network of connected entities in order to provide a scaler value specifically related to the view of any given particular user.
Why would we want such a thing?
This is the $10,000 question.
Web of trust systems might appear to be overly complicated, unintuitive, and a lot more work than they're worth. After all, why is it not sufficient to simply know what "everyone" believes to be true? Why is it not enough to believe that other people like a thing so you will probably like a thing, too?
Some of you out there have twigged to the problem.
Web of trust systems allow platforms to be customized to the needs and interests of particular users. That means that their experience over time gives them more of what they want. It means your experience over time gives you more of what you want. The experience becomes more refined, more able to be of use to you no matter what "of use" means to you personally, because it builds an understanding of what you want by listening to what you say you want.
This is almost the inverse of the way that LBRY.tv and the LBRY app surface discoverable content for you. Right now, all that matters is how much LBC someone else has put into a given piece of content. It has nothing to do with the content itself. It has nothing to do with you as a consumer. It doesn't even have anything to do with the creator as a creator. All it takes to get to the top of Trending or Top is for a whale with a lot of LBC to decide to put 10,000 tokens into the Support for a given piece of content. That's it.
It's actually less useful to the user than advertising algorithms which big content platforms like Google and Facebook use in order to put advertising for which the user might have interest in front of them. Targeted advertising takes signals from a user and attempts to classify them by interest to expose them to content that they never asked for but might find useful. Web of trust systems take signals from a user in order to help them sort and filter content that they have asked for to maximize the exposure to content they might find useful.
It's the sorting and filtering mechanisms which are of interest to us in the context of the LBRY experience.
On the Table

We know what LBRY is. We know what web of trust systems are. We have a few ideas about what the uses are.
Let's talk about some more specific user experience advantages for web of trust systems.
Spam filtering
Spam is the eternal bane of social media platforms. Even defining what "spam" is becomes harder every day.
Originally, spam was unsolicited commercial communication. Mailbox full of free flyers advertising local businesses that you end up throwing away by the fistful? Spam. Emails trying to get you to buy unlicensed erectile disorder drugs? Spam. Those are clear examples.
Over the years the definition has broadened to include things which are spam-adjacent but not technically spam. Scams in particular often get thrown into the definition of spam because they have an actionable financial incentive. The Nigerian credit scam where a prince needs your help to move a $250 Western Union credit to free up $20 million? Stupid, a scam, but usually classified as spam these days. Phishing scams in which a notional attractive member of the appropriate sex would like to trade naked squirming pictures of them for your credit card or other identifying information? Classified as spam.
Spam and scams are easy to find on the LBRY. Since the addition of content comments, an entirely new branch of possibility for spammers and scammers has opened up which requires very little effort to build a bot that can post a comment on every new piece of content associated with a tag. Right now there is no way for a user to express their distrust of any content creator – and that's a real problem.
Consider the situation where a web of trust system overlays a spam filter. Being able to say "I trust that this source of content is a spammer", a form of negative trust expression, means that their content no longer appears for you. Likewise, if you trust me in a positive sense and I express a negative trust relation with a third-party account, you trust them less than one that neither of us has seen. Networks of trust simultaneously build up networks of active distrust, and nobody trusts spammers.
This also addresses the issue of whether or not a centralized platform should and can be responsible for policing spam and scam content on the distribution network. We know from looking at Google and YouTube that it is impossible. Not difficult, not challenging, but impossible, even given effectively unlimited resources to throw at it. This is what happens when you look for top down solutions; they don't exist.
Instead, imagine that LBRY Inc. was simply one more entity which you could trust or distrust at will. If you trust them, and they have an effective process and procedure for filtering spam such that they were good about applying negative trust to content and providers who created spam, you would inherit the advantages of their good work. If you disagreed with how they made their decisions or how the effects were applied – you would have no real cause to give them positive trust and as such would be unaffected by any of their personal policies or mechanistic effects. In fact, you may yourself be a source of trust in finding and rooting out spammers and scammers and if enough people believe that to be true and trust you, thus getting the advantages of your efforts, that would be providing a meaningful service.
The mechanics and use of being a trusted member of the platform and accepting tips/payment for providing the service is left as an exercise for the reader.
Spammers which are detected can be distrusted and thus be less visible/surfaced. This is why spammers often move from account to account, attempting to escape their history. However, in the process of escaping their history they escape any positive trust, and without any positive trust they have a much harder time getting in front of more eyes in a web of trust-grounded system, making spamming even less likely to be profitable and thus less likely to be done.
Lensing
"Lensing" is probably not a term that most of you are familiar with but it's a term that I use a lot. It's simple. It's comprehensible.
Think of all of the content which is available to you via any given outlet as a river. It's just a bunch of flowing water. New water is added to the river constantly and sometimes water is removed from it (as it's deleted or no longer referenced). But it's just flowing water.
The current standard for presenting stuff is what I refer to as "the fire hose method." River comes in, the most recent stuff is blasted into your face first and then more of it comes blasting through, forever and ever. It's like trying to take a sip from a fire hose. There's just too much content for you to find the bits of it that you want to taste. Facebook and Twitter are the worst possible offenders when it comes to the fire hose method of presentation because of their obsession with reverse chronological order and endless scrolling streams.
A lens is a device through which you pass light and on the other side, that light is changed in an elemental way so that you can see what parts of it that you're interested in. Some lenses act as filters, removing part of the content that you're not interested in. Some lenses merely spread out and reorder the light that comes in, letting you start at one end and comprehensively move through to the other end, understanding the position in the whole thing as you go.
Lensing lets me take the fire hose, the stream of water-made-light, hook it up to the back, and project it in a way that lets me order the stream of stuff and comprehend it.
There are lenses currently available and implemented on all of the LBRY platforms – but none of those lenses have anything to do with me as a user. All of them take as primary importance the staking of LBC, without regard to any of my expressed interests or desires.
Now consider what an available web of trust metric provides. It's a metric, so we're able to sort content which matches our interests to the top and push content which doesn't match our interests down the list without actually removing it entirely. This keeps the availability of new content from new creators in play.
As new creators which entities we trust earn trust, even outside our immediate lensing horizon, that content is pushed further up the list, making discovery far more likely. Providing a useful user-centric metric for discovery is something which all content distribution platforms should use.
Beyond discovery and exposure, lensing has applications in content distribution itself. As more content hosts come online, many of them automated replicators, they will need some method by which they can prioritize some content to replicate before other content. (This imagines a future in which more content is being created and posted to the LBRY backend than bandwidth allows for keeping up with. That may be optimistic, but let's go with it.) A web of trust metric provides an excellent opportunity to determine what content should be hosted before others for individual hosting providers.
Lensing is a general-purpose ranking/filtering mechanism which can be applied across the board to LBRY application developments.
Freedom from authoritarian diktat
Taking up this issue runs the risk of coming across as ridiculously pretentious, but much of the underpinning documentation of LBRY is phrased to prioritize privacy, stability, and a strong disinclination to centralized control and the potential for censorship. I am 100% on board for all of those things.
I've written before about "the authoritarian in assumption," and it's time to put that in simple terms. It is not complicated.
The imposition of the core metric "what is good" from outside of the individual is essentially and incontrovertibly authoritarian. It demands that the individual accept that others are better at deciding what they should like and will like than themselves. It is externally imposed control over what the individual not only can see and do but should see and do.
I don't like it.
I'm not against those metrics being among those individuals can choose to use as part of their customized experience but that is not how they are implemented, presented, or created.
In the case of LBRY, the user has only two individualized available lenses:
- Channels that they follow
- Tags
You can't use them together.. You can look at content from channels that you follow. You can look at content from tags that you follow. You cannot look at content from channels that you follow filtered by individual tags.
Within each of those trimmed fire hoses, there are only three ways to sort content.
- Purely reverse chronologically
- By which of them has accumulated the most LBC and Support and Tips
- By which of them has the greatest delta of the LBC in Support and Tips
None of those things care about what you're interested in. It is the roughest, grossest kind of paring down with the bluntest possible tool. It assumes that those with the most LBC make the best choices about what you and I should want to see.
I understand of the ease of that assumption but that doesn't keep it from being any less inherently authoritarian.
Tools of the Trade

The basic ideas have been laid out, but that's only the skeleton. We need to look at the meat.
No system can function without information. What do we have available to us? There are the basic facts encoded in the LBRY Protocol. Can we use them to build a web of trust metric from the information gathered naturally both through the blockchain and content distribution systems? How about at the application level, through the content browsers?
If we can build a system with what we have in hand, are there changes to the underlying architecture that would make our job easier?
Data available in the LBRY Protocol
LBRY has been very forthcoming in a lot of their documentation for both their application platforms and the Protocol. While there are certainly parts of the centralized decision-making process which remain unclear or ill-defined, things like data collected from applications are clear. In fact, the Privacy and Data FAQ is an excellent resource for figuring out what kind of information is available to the system. Coupled with the LBRY Rewards FAQ, you can build a relatively comprehensive model of user information that flows through the system.
Note that we don't actually need or want to modify the underlying LBRY Protocol in order to implement web of trust metrics. Web of trust systems are inherently decentralized in terms of necessary client data; while you can build systems which make use of economies of scale and large servers for centralized access, it's not necessary. It's preferable that web of trust metrics be introduced at the application/service level and not integrated into either the blockchain protocol or the content distribution protocol – because it has nothing to do with either.
Making reference to the Privacy and Data FAQ, we can deconstruct the minimum possible information available to a client application using the LBRY Protocol in order to consume content. This doesn't involve any kind of Reward interaction because all of those are issues at the particular access application level and involve a holder of LBC choosing to give it away in response to actions taken through a particular interface. They are not inherent to the LBRY Protocol.
Through the LBRY SDK, effectively a command line level tool/plug-in library for interacting with the LBRY Protocol, there are only a few pieces of information necessary.
- System information
- Content access analytics
- Blockchain transactions
In theory, using a VPN is acceptable with the LBRY SDK as long as you accept that no qualification for Rewards from the LBRY Inc. LBC pool are possible. Of that list, only blockchain transactions are visible to everyone; the rest of that information is apparently obscured and only shared with LBRY themselves.
That makes sense because without an associated email address within a content-revealing application, there is no continuous chain of identity possible for a given user. For our purposes that means that we don't need to care about the LBRY SDK as an information source because it doesn't have anything associated with the individual user, which we absolutely need to establish a web of trust relationship.
Now we know that we must be talking about information acquired and used by an application-level interface with the user, either the LBRY Desktop App, LBRY.tv, or the LBRY Android App, and preferably a system usable by all three. Each of them is very much driven by access to a singular account identified by a singular email address with associated user preferences (unfortunately not distributed through the LBRY Protocol), identity verification, content access analytics, absolutely required IP addresses (no VPNs), blockchain metadata (wallet transactions for Rewards associated with an individual account), and blockchain transactions (general access to blockchain/naming/payment transaction information).
Since all three applications provide identity verification as part of their operation, we can start by assuming that the wallet ID associated with any of them represents an individual. That saves us a lot of time and trouble.
The blockchain transaction information which is available and visible to everyone also might provide us with an opportunity to accumulate web of trust data without an explicit web of trust interface which is user facing. We know that the user has a singular identity, we know they have a wallet identifier which is singular, and we have access to every transaction on the blockchain which has a permanent effect – and this could allow us to build a web of trust network based solely on the expressed preferences of the viewing user.
Except, of course, that it can't. The reason? Wallet address identifiers are not a strict match to a singular identity. In fact, public-facing wallet addresses can be arbitrarily changed on every transaction if the user so desires. (The LBRY SDK API Documentation for the account_create call is enlightening here.)
This is great for privacy concerns but not awesome for systems which want to use public data to build individualized web of trust systems.
This is only a stumbling block and not stopping point, however.
There is a bit of a problem in that even though we can accept the identification of the user in an application, our only concept of "other entity" is limited to Channels or wallet addresses. (And content elements, but ultimately those need to resolve back to a decision making entity for the system to be useful.)
Channels are flexible pseudonyms. At the Protocol level it looks like they could technically be controlled by multiple accounts, even though that functionality isn't in any current application, but Channels aren't the identifier which drives Supports. If they were, this would be a very easy system to implement because we could just treat Channels as individuals and proceed accordingly.
Wallet addresses aren't unique to a singular wallet – or rather, a wallet may have any number of addresses through which it transacts. The record of those addresses don't define a singular entity necessarily post hoc. There is a many to one relationship between addresses and wallets and no way to associate particular identity with any given address.
You would rightfully see this as a real problem. Building trust networks requires at least stable pseudonymity, the expectation that you are dealing with a structured entity with predictable behaviors. There is no way to assure ourselves that any other entity that we can see interacting via Supports on the system has that level of stable pseudonymity.
It's clear that we cannot use purely blockchain data in order to build up a suitable web of trust model. It lacks the one thing that we need absolutely in order to function: a representative static identity.
That means that any web of trust implementation is going to have to occur at the application level using information available to the application itself. In the case of LBRY, that means LBRY.tv, the LBRY desktop application, and/or the LBRY Android application. Only those things have a singular point of identity which the system knows about and which we can use to express trust.
Sidebar:
It's extremely interesting to note that on the full text of the LBRY Privacy Policy, the following is extremely explicit.
**Does our site allow third-party behavioral tracking?
**It's also important to note that we do not allow third-party behavioral tracking
… While simultaneously using Google Analytics for doing a considerable amount of the heavy lifting on the backend of the content consumption applications. I'm not saying that it's hypocritical but I am saying that it suggests a much higher degree of trust in Alphabet as a corporation than an organization which has prioritized privacy and a lack of censorious control probably should.
It would be more accurate to say "nobody that we work with tells us about their third-party behavioral tracking."
Data available to active LBRY content browsers
If we're going to implement stable pseudonymity outside of the blockchain and content distribution protocols of LBRY, we have to decide on some mechanism by which the stable pseudonymity can be named.
The obvious answer is that a user should pick a Channel to operate as within the web of trust. The system already has the means and mechanisms to verify and validate that an individual user has access to make claims on the blockchain as a given Channel, which is all we need in order to operate as a stable entity.
As a side effect, this means that an individual user might have multiple pseudonyms by which they can accumulate and discharge trust from other individuals. That is not a problem.
In fact, that provides a certain amount of flexibility that is often overlooked. One can cultivate a reputation in multiple areas for certain kinds of content or certain kinds of decision and there's no reason that all of your reputation has to accrue to the same entity. If you operate as a Channel which is very good about finding and enjoying classic films across the network and build up a reputation for doing so, while simultaneously operating another Channel which is active as a commenter and very helpful for new people coming to the platform, other people rightly should trust your judgment on finding good film resources more strongly when operating as the first Channel than the second. That's not to say they aren't both trustworthy – but they are differently trustworthy.
The obvious counterargument for the idea is to suggest that because Channels are very cheap to establish and very cheap to burn, they are an obvious means by which spammers and scammers could rapidly appear, engage in trust-betraying behavior, and then burn the Channel before the lack of trust/accumulation of negative trust became meaningful for that pseudo-ID.
All that is true. But it is also true that it is currently near-trivial for a spammer/scammer to create new wallets and new accounts, fund them from a blinded account, and engage in bad action as it stands. It certainly doesn't make the system worse for them to be able to sidestep accumulating negative reputation and a web of trust system has multiple positive effects for good faith users.
With Channels chosen as our pseudo-ID, we have the noun necessary to convey our intent to the system. Now we need verbs.
What are the ways in which we express trust within the current architecture of the LBRY applications? Remember, we are explicitly avoiding mechanisms which are scaler and only looking at expressions which can be rendered as binary decisions.
The place to look for user intent communication is what they choose to Tip and Support (which we will talk about as if they were identical functions, which they are in the API). Because both Channels, which represent our pseudo-IDs, and content can be interacted with by Supporting, Supporting becomes our obvious first verb.
Channel SUPPORTS Channel.
Channel SUPPORTS Content.
Because this information cannot be derived from the blockchain, it must be stored in a separate database associated with the application. In theory this could be another blockchain explicitly devoted to storing trust transactions, orthogonal to the blockchain intended to store LBC and claim transactions. Or it could just be a simple database kept on an application server. It doesn't really matter to us at this point.
What does matter is that only entities which signal that they are interested in being part of the web of trust system can gain/lose trust within this mechanism. Because there is no way to automatically determine intent expression from LBRY blockchain content, it must be explicitly maintained by the application. It also might be entirely optional.
That gives us a pair of intent expressions with subject and verb.
Channel OPTS IN.
Channel OPTS OUT.
Opting in would create an entry in the trust database and tell the application that Supports given by this Channel should be tracked for trust purposes. Opting out would remove any trust tracking from being possible.
In an application where trust tracking is available, an easy first cut for distinguishing intentional bad actors from good actors who make mistakes is to simply look at who decides to opt out of the web of trust. A very obvious and useful lens is to only view content which has been posted by a Channel which has opted in to the web of trust.
With as little as these three intent expressions, we can build a graph database which represents contact and connections between Channels sufficient for a web of trust. At the moment it is impossible to express negative trust but merely filtering for sufficient positive trust can suffice to help filter bad actors.
Since we are dealing with purely binary expressions of trust, creating a negative trust expression is extremely simple. Two intent expressions will suffice.
Channel DISTRUSTS Channel.
Channel DISTRUSTS Content.
This effectively signals to the application that when viewing available Content as the pseudo-ID Channel, these things should be down-ranked in apparent value from the perspective of this user.
That is all we need in order to implement a basic web of trust, user-centric, user-first lens at the application level, and purely by accident we have managed to provide a user multiple ways by which they might choose to build and develop web of trust lenses. Because any given user at any given time can switch the pseudo-ID Channel that they are using to build to their perceived web of trust, they can shift between lenses built off of those individuated webs of trust without a problem. The pseudo-IDs maintained by a single individual don't have to trust one another. In some situations it would be very handy for one to distrust another in order to more strongly differentiate the lensed views provided.
(For a more in-depth description of what this might look like, please consult Steemit and the Web of Trust: A Potential Love Story which walks through an entire sequence of trust expressions.)
The rest is a matter of simply figuring out the best way to quickly walk the graph for value. Over the last five years, graph databases like Neo4j have significantly pushed the performance of graph traversal systems beyond what we could even previously imagine. Making use of a modern graph database to do web of trust valuation calculation is an obvious match.
Possible additions to the LBRY architecture
Obviously, the most useful thing that could be added to the LBRY Protocol itself in order to build this kind of operation would be the promotion of Channels as a platform-wide pseudo-ID when putting Supports on the blockchain. Because the transactions which create Channels are blinded, associating a specific Channel with a specific Support doesn't stop anonymity for individual users. Nor does it impact the ability of the network to maintain anonymously sourced content, protecting the identity of creators. Both anonymous and blinded Claims remain a pivotal part of the underlying Protocol.
It would be nice if there was some sort of user data space associated with Channels as part of their pseudo-ID usability, making things like web of trust expressions portable across multiple applications through the blockchain itself or, potentially, through the content hosting side of the Protocol as an associated file which is always Claimed. Support for such associated but portable data is not currently in the Protocol but certainly within the sphere of possibility because of the way data is serialized before it goes into the blockchain side of the system.
Even without that level of support built in, it is relatively straightforward to implement web of trust metrics at an application level; they simply won't be inherently portable across provided applications.
Pulling It Together: A User Story

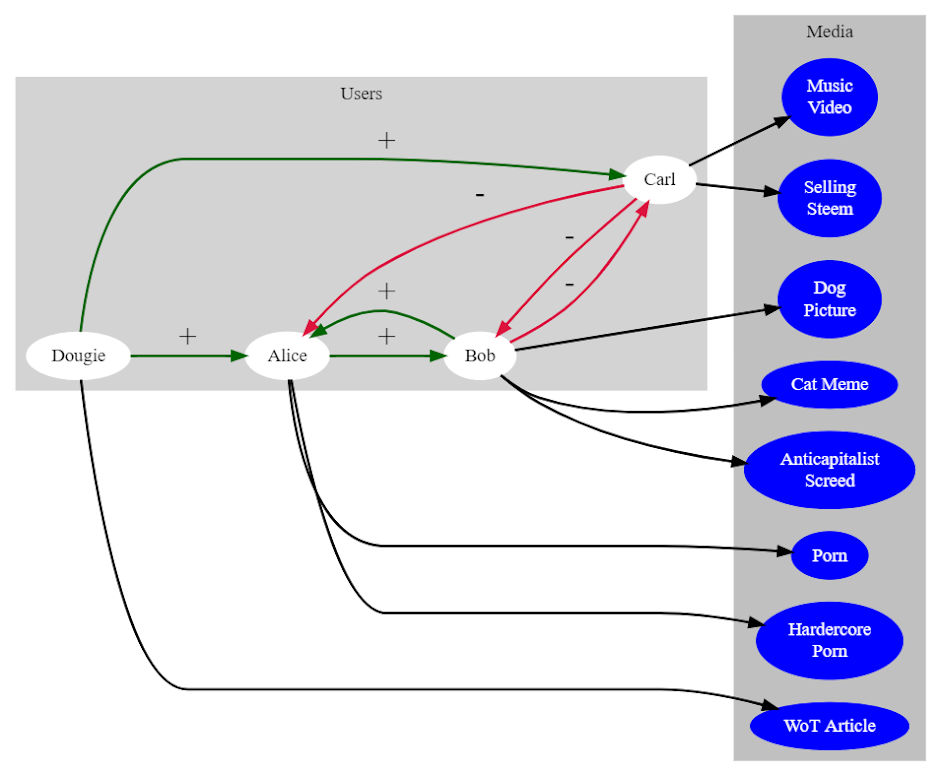
Once upon a time there was a user, Alice.
Alice was tired of dealing with traditional content distributors and their arbitrary rules, the way that they isolated her from her fans, and that they made finding things she was interested in harder than it had to be.
Alice created an account on LBRY. She decided that her interface of choice would be the LBRY desktop application.
New to the platform, when she created her account, it came with an almost empty web of trust. Alice hadn't consumed any content or met any users and so the only account that she trusted by default was the LBRY Foundation, who maintained a pseudo-ID Channel specifically so they could be part of the overall web of trust.
Because Alice started trusting the LBRY Foundation, when she began to sort through content, she had the option of lensing everything available by trust. When she did so, many spammers and other bad actors dropped away from the top of the list because the LBRY Foundation consistently distrusted the bad actors that they could see.
As she continued looking through content, some creators consistently made things that she enjoyed and she followed their Channels. That created another lens, one which would only show her content from those Channels.
Having found a video on making clay golems, Alice Supported it with 2 LBC. By so doing, she attributed trust to that piece of content. The other Channels who did likewise inherited a portion of that trust. Channels who trusted the Channels who also Supported that content inherited a smaller part of the trust the original Supporters did.
Looking back at the content which was available to her and bringing the web of trust lens back into place, the content was in a different order, ranked by things that people who Supported the same things that she did also Supported.
Alice was pleased. More things that she was likely to enjoy were closer to the top of the list.
She cheerfully worked her way deeper into the pile.
Eventually, Alice found a piece of content that she didn't like. In fact, she didn't like it so much that she Distrusted it. The Channel that posted it and Channels who Supported it thus inherited a little bit of that distrust. Likewise, the other Channels who Distrusted it inherited a bit of positive trust.
Every time that Alice interacts with a piece of content that she cares enough about, the system gets a better idea of the sort of thing that she likes – but it does so without necessarily identifying Alice by name. All it knows is that there is a Channel which is expressing trust.
As she engages, Alice is also creating a feedback loop with other people who are involved with the web of trust system. When she Supports things that they also Support, they trust her a little bit more. When she Supports things that they Distrust, they trust her a little less. Together, everyone builds a better set of lenses for each individual person.
Bill is a spammer.
While Alice is asleep, Bill posts a thousand spam videos to the platform. As that content get seen, Channels begin to Distrust it. Not only do they Distrust the videos, they Distrust the Channel responsible for posting them. By the time Alice wakes up, has breakfast, and checks for new content, enough people that Alice trusts have Distrusted Bill's content that it is buried at the bottom of Alice's content list. She never sees it.
Charlie is a gladhanding windbag.
Using a combination of charm, cunning manipulation, and bribery he rises to a position of control in the LBRY Foundation, kicks out all the reasonable, sensible people, and rules the place with an iron fist. Under his cruel regime, the LBRY Foundation begins taking bribes from spammers to not Distrust them and, in fact, begins to aggressively Distrust Channels which post content critical of the LBRY Foundation.
Alice doesn't like this. She doesn't like anything about it. Despite the fact that the LBRY Foundation Channel was the first one that she ever trusted, by default, and it has accumulated a fair amount of implicit trust in the ensuing time, Alice has had enough. She Distrusts the LBRY Foundation Channel.
Instantly, her lens changes. Because that Distrust is propagated down through the graph to other people who have Supported the LBRY Foundation Channel, there is an entirely different pressure on the content sorting. All of the spam being supported by Charlie is now inheriting that Distrust.
It doesn't matter what happens elsewhere on the platform; for Alice's experience it only matters what Alice's choices are. She can trust anyone she wants. She can Distrust anyone she wants. The system does not judge. The system assumes that she knows what she wants and exists to help her.
Alice continues to see content that she likes and Channels that she likes, and is aided in finding new content that she's likely to enjoy because of inherited trust. Even though there are bad actors with significant power on the platform, Alice is able to continue engaging, continue entertaining her fans, continue being a fan – regardless of what anyone else does.
THE END

Appendix i: References
- Steemit and the Web of Trust: A Potential Love Story
- Steemit and The Dynamic of the Authoritarian in Assumption
- Steemit and the Ultimate Recourse: Blockchains For Everyone!
- Hypothes.is LBRY Group
- LBRY.tv
- LBRY Privacy and Data FAQ
- LBRY Rewards FAQ
- LBRY SDK API
Appendix ii: Credit
Thanks to:
- Eniamza
- ShadowWolfPro
- jigglytom
- Ipessin
- Clement
... on the LBRY Discord for their help and insight while I beat on this article over the last several days.
As we all know, the fastest way to be educated about a topic is to state something that is outright wrong on the Internet. I am absolutely certain that I have mucked something up somewhere in the course of this article.
If you know better than I, if you have personal experience, or you can elaborate on something that I've mistaken – please feel free. Annotate the article on Hypothes.is, comment on Steem or Hive, or just get in touch with me in order to let me know. Every theoretical project is a learning experience and this one is no different.
Appendix iii: Support
If you’ve enjoyed what you’ve seen here today and want to support my continued efforts to bring engineering, art, and the occasional philosophical divergence to the masses, please feel free to send me a tip. Or thousands of dollars, I’m really not that picky. It’s through your efforts that content like this gets created.
Check out my portfolio if you'd like to get in touch or see more of my work.
- PAYPAL: http://paypal.me/SquidLord
- CASH APP: https://cash.app/$SquidInks
- BITCOIN: bc1qy9wkj3g6ueugu0tjuwmh6dfxxn590r3p9tj9qt
- ETHEREUM: 0xcca4C3A3024d7496bDe06f6Fd865BfD5992Bf10B
- BAT: 0xcca4C3A3024d7496bDe06f6Fd865BfD5992Bf10B
- STELLAR: GBI6AMTGCBUPRBKWY3V246FDBZJILGOZHNOYWJXZNRBLACB6ZWAQTIYW
- ZCASH: t1dhcviaYgQuX4z91jhkjHrmkWNf5agJCNc
- MONERO: 48JHK6G4FyvSktU45t5ra7SALwFJAMEebEShPmk1K7xd95p4mYNJMnRZ27JBmcc97VhrJqEDmCyHtVP8iDTeNAJE1VnaCN8
- PO.ET: 0xcca4C3A3024d7496bDe06f6Fd865BfD5992Bf10B
- TRON: THKkzVBLz4V14dmvpDxkag8piKuJ74aATa
- XRP: rHvFZbRtsW2975zQXYTHDz7VAXPSdozoEs
- LBRY: https://open.lbry.com/@LexTenebris:9
- STEEM: @lextenebris
- HIVE: @lextenebris
Congratulations @lextenebris! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
You can view your badges on your board and compare to others on the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @hivebuzz:
Vote for us as a witness to get one more badge and upvotes from us with more power!