
This post is an update to the ideas and concepts presented in the ƒractally white paper based upon lessons learned over the past 4 months of community experimentation with the process using Hive as the ledger. Some of the principles that are guiding this update include:
- Limits of Precision of Subjective Judgement
- Scale Invariant Design (down to 20 people)
- Need to Average over Time
- Minimize Meeting Times
- Predictable Token Supply
Limits of Subjective Judgement
We have come to model people as a scientific instrument attempting to assess the relative value of each individual’s past contributions relative to their past recognition. Furthermore, each instrument has a different scale and we are attempting to integrate the different values of all community members to arrive at a consensus value. In the weekly meetings it is generally easy to identify the greatest and least contribution but harder to rank two people with similar levels of contribution. This is complicated by the fact that the same person ranking the same contributions may have different opinions on different days.
We can therefore assume that any given measurement has a wide margin of error and that many measurements are required in order to get a more accurate measure of community consensus.
We can also assume that not all people are equally skilled in making these value judgments so the average error over the entire population is likely much greater than the average error in the top half of the population. This skill in valuing contributions is likely pareto distributed and therefore fractal in structure. Meaning the top quarter of people are likely far better at making value judgments than the top half.
That said, even the most skilled individual is operating with limited information and would have a hard time distinguishing contributions. Therefore, if we apply the fractal governance pattern as outlined in the white paper with up to 5 rounds, the later rounds are likely to have amplified errors as fewer and fewer measurements are responsible for allocating a larger and larger percentage of the communities budget.
On the other hand, if we only have 1 round then the noise from the less skilled contributors will dominate. Under the model in the Fractally white paper a community would need to have at least 30 people to get to a second round consisting of just 5 people. These top 5 people will have a hard time accurately ranking each other leading to more noise.
Scale Invariant Design
In an ideal world the rules for governance would not need to change as a community grows. This means that there should always be the same number of rounds regardless of community size. The design we present in this update will work with any community with at least 20 people participating every week.
Round One
In the first round everyone is randomly assigned to groups of 5 or 6 people who must reach consensus on who contributed the least (Level 1) to who contributed the most (Level 6). Unlike how the current Genesis Fractal ranking system has been operating, the ranking order of the top 3 contributors (Level 4, 5 and 6) does not matter because the top 3 people from each group must advance to Round Two. Because the order of the top 3 contributors does not need to be agreed to in Round One, it should dramatically reduce the time it takes to reach a consensus.
Round Two
In the second round the top 3 contributors from the first round are randomly grouped and they must reach consensus on who contributed the least (Level 3) to who contributed the most (Level 8). This round will operate in a manner similar to how the Genesis Fractal has currently been operating.
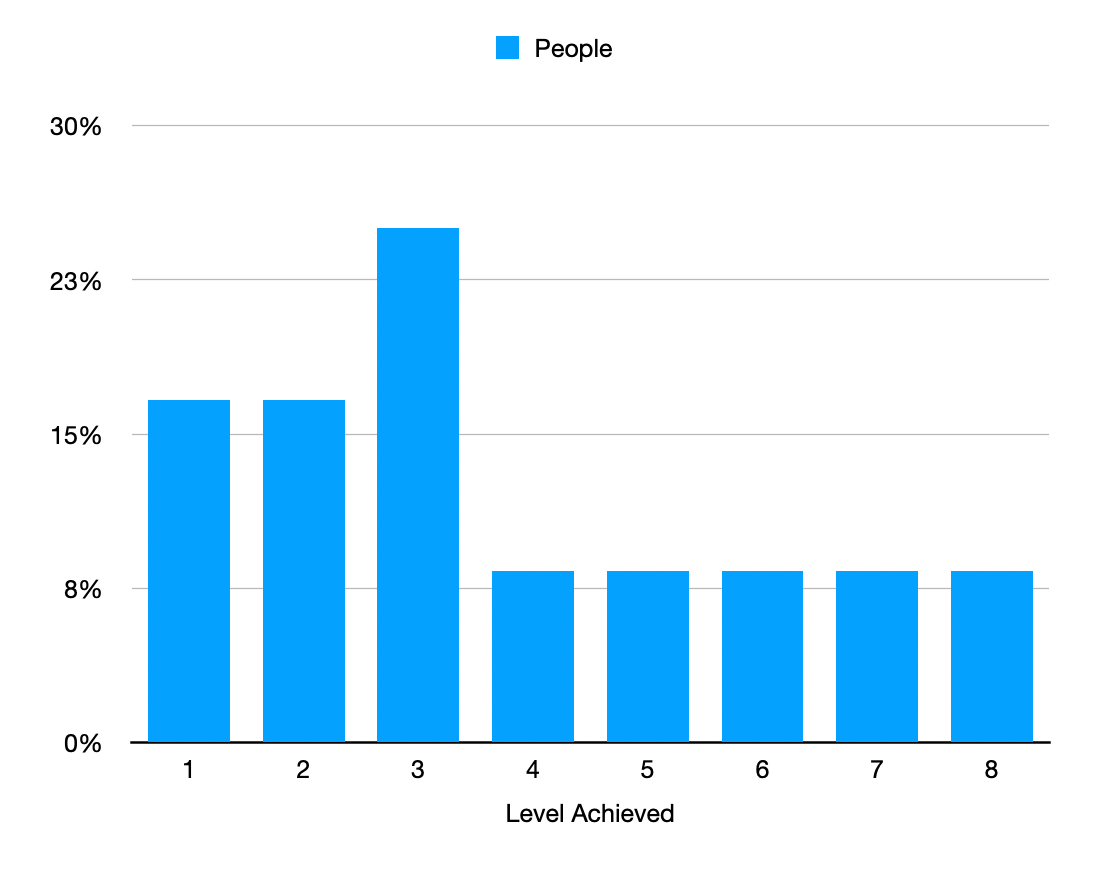
With this model the community is able to identify the top 9% of contributors in just two rounds. Critically there is always at least 3 groups in round two even with communities as small as 20 people. This means there will always be at least 3 people who achieve Level 8. After 4 months of experimentation we believe that the this may represent the limit of human judgment and that further ranking of the top 8 is more likely to introduce noise to the measurement and introduce incumbent advantage. If we assume the best people are reliably recognized by earlier rounds then each successive round will tend to promote a similar group of people. If we allow this group of people to push people further up the fibonacci sequence then they would tend to dilute the influence of earlier rounds and amplify the errors of individual measurements.
One of the caveats of this new model is that not everyone is promoted to Round 2 is guaranteed to get a Level greater than the highest level that wasn’t promoted from Round 1. This was done to reduce the incremental advantage between Level 3 and Level 4 of Round 1. Under a Fibonocci distribution that advantage was already going from earning respect of 3 to respect of 5 (a ~60/40 split of 8) but now the gap would also include the opportunity to reach Level’s 5 to 8. This could make it difficult for Round 1 participants to decide who should be Level 3. By making the lowest Level assigned by Round 2 equal to the highest Level assigned by Round 1 it removes the difference in Respect distributed in Round 1 between those they rank at Level 3 and those they promote to Round 2. This lets Round 2 groups resolve that difference.
The net effect is that unless you believe that you are likely to achieve Level 4 to 8 in Round 2 then you have nothing to gain by being promoted. Promotion to Round 2 requires participating in another meeting. In other words, by starting Round 2 at Level 3 we make it easier for Round 1 participants to reach consensus.
Average over Time
One of the emotionally challenging aspects of the ranking process is that sometimes a group of 6 people is randomly assigned many of the top people from the community. When this happens someone has to be ranked lower even though they contributed far more than people in other groups. On the other hand, some groups are randomly assigned people who contributed very little and someone gets lucky and is ranked far higher than a top contributor. This is bad enough when there is only one round and it would be seriously amplified when multiple rounds are introduced if only the highest ranked individual was promoted to the second round.
This noise introduced by the necessary randomness combined with the limits in our ability to reliably compare relative values means that community members need to trust the process over time and not get discouraged (or overly optimistic) due to the results of any single week.
What we have learned is that a persons average Level is probably a more accurate means of ranking someones average contribution over time. This average integrates the opinions of not just one random group of 6 people, but potentially 6 to 12 random groups of people depending upon whether you average over 6 to 12 weeks.
Someone who reliably achieves a Level 8 every week is likely to be contributing far more value (with far greater consensus on that value) than someone who only averages a Level of 7.5. There is a bigger difference between an average Level 7.5 and 7.6 than between 7.4 and 7.5.
Under the design in the Fractally white paper Respect was distributed according to AVERAGE( FIBONACCI( LEVEL ) ). We now propose that Respect be distributed according to FIBONACCI( AVERAGE(LEVEL) ). This means we need a continuous Fibonacci function.
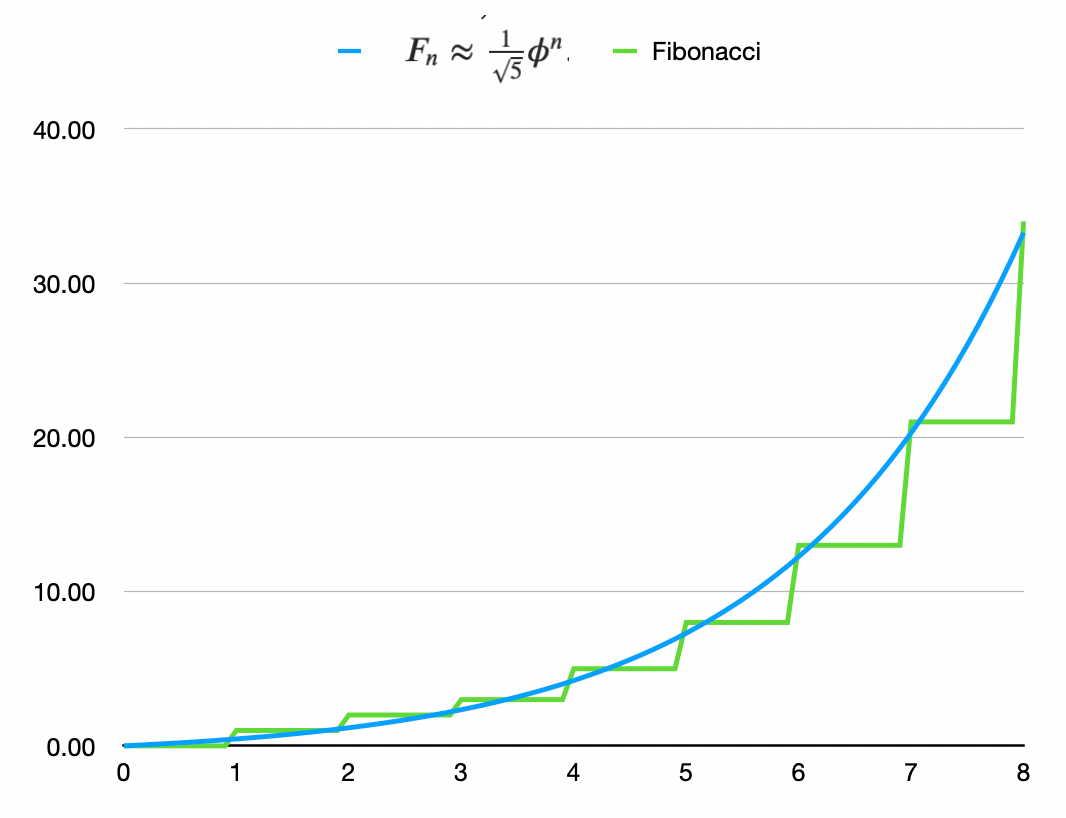
A consequence of this averaging method is that no one can show up for only one week, get highly ranked, and earn a large amount due to the exponential nature of Respect rewards relative to Level. Instead, to climb the curve you must average a high Level over time. This should dramatically reduce the social costs of collusion/misjudgment in any single group.
It also means that you can earn something even on weeks you do not attend a meeting. Your average will fall by incorporating a Level 0, but you will never the less get some compensation. The end result is that the amount of Respect allocated to an individual from week to week is far more stable.
The chart below shows what would be earned each week if someone showed up and started achieving the highest Level (8) every week for 26 weeks and then left and being given a Level (0). Note that after 12 weeks of non-attendance someone would cease to be a member and their income would fall to 0. This graph does not factor in the loss of membership which would take precedence, but is intended to represent the relative shape of the curve.
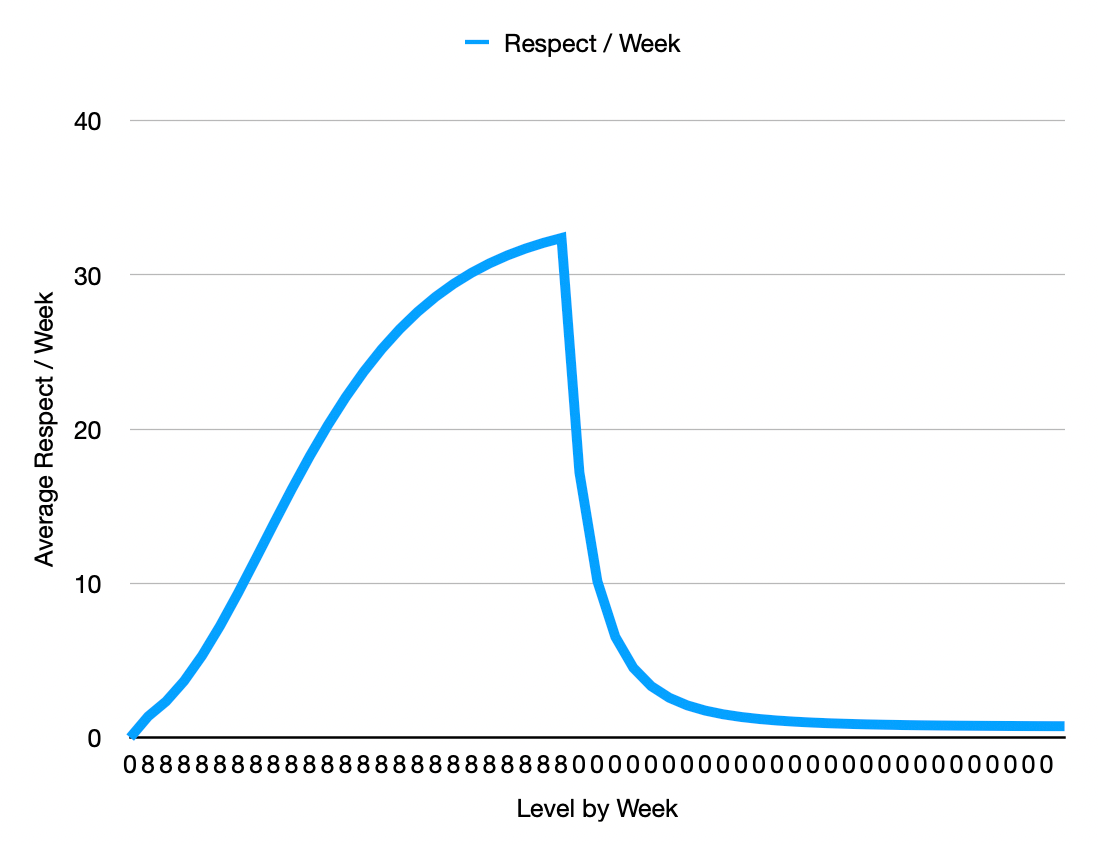
The average is calculated as NEW_AVERAGE = (CURRENT_AVERAGE * 5 + NEW_LEVEL)/6. This moving weighted average is an approximation that is easy to calculate, but there are a number of different kinds of averages that could work in a similar manner. A pure moving window average would go from 0 to max in just 6 weeks and fall from max to 0 in 6 weeks whereas this function has more momentum to it which I believe may better approximate reputation.
Token Distribution
One of the most frequent questions we are asked is what is the “token model” because the token model is one of the most critical considerations in estimating a valuation. Bitcoin has a token model that guarantees there will only ever be 21 million tokens and the rate of issuance will fall by 50% every 4 years. This simple model makes it easy for speculators to estimate supply and demand.
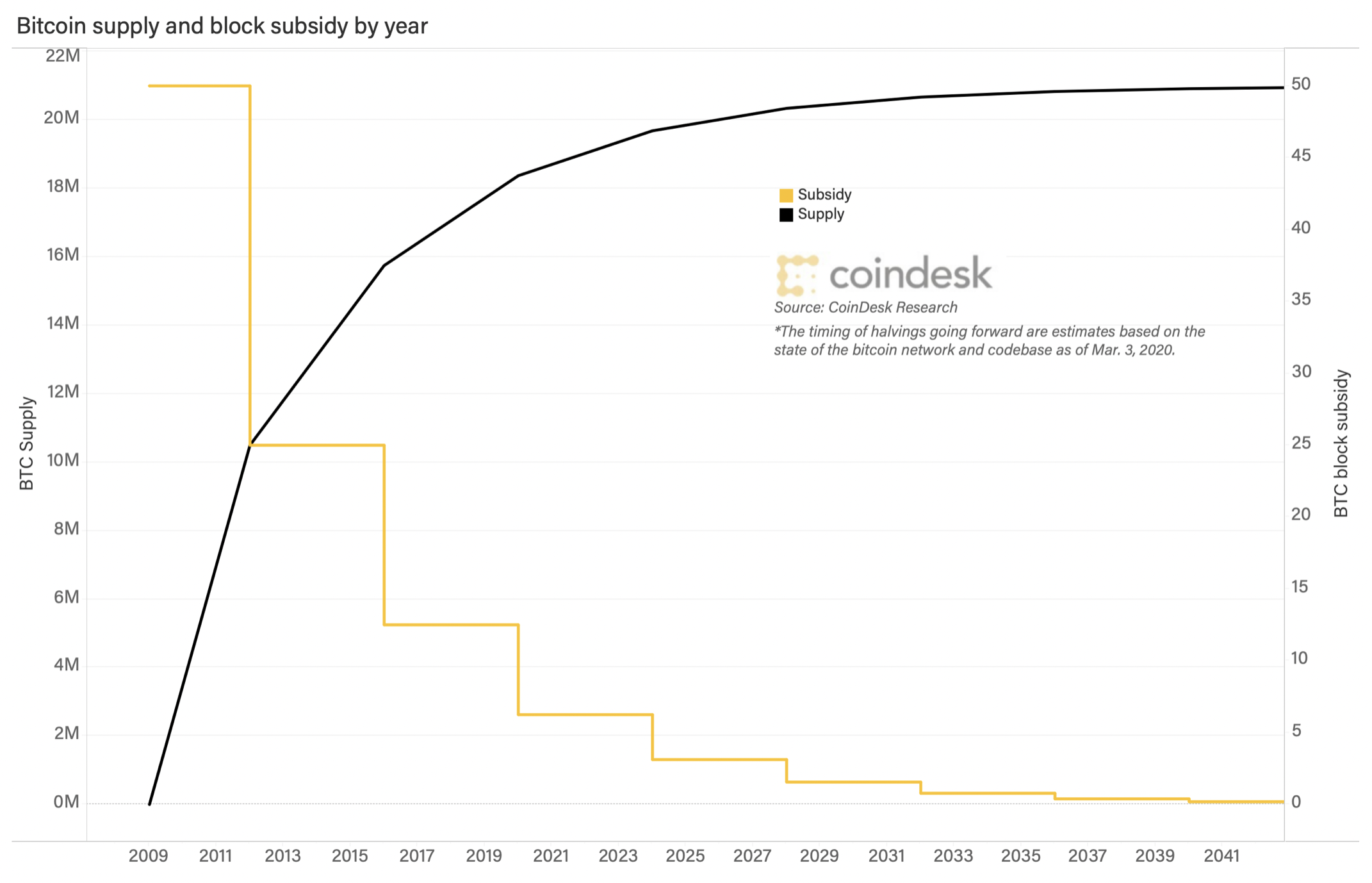
The model presented in the Fractally White Paper was subject to many variables such as the number of community members participating any given week. This makes it challenging for people to model their rate of dilution which could change radically over time.
Under the original design, as the community reaches maximum size the rate of issuance becomes constant and the inflation rate approaches 0% APR. This means that the community does not decay the value of old contributions relative to current contributions and the token will eventually stagnate due to insufficient funding of necessary community maintenance activities.
Furthermore, the token distribution is not initially biased toward the early adopters who take the most risk which means these early adopters will be rapidly diluted by the masses of late adopters who show up when the risk is greatly reduced.
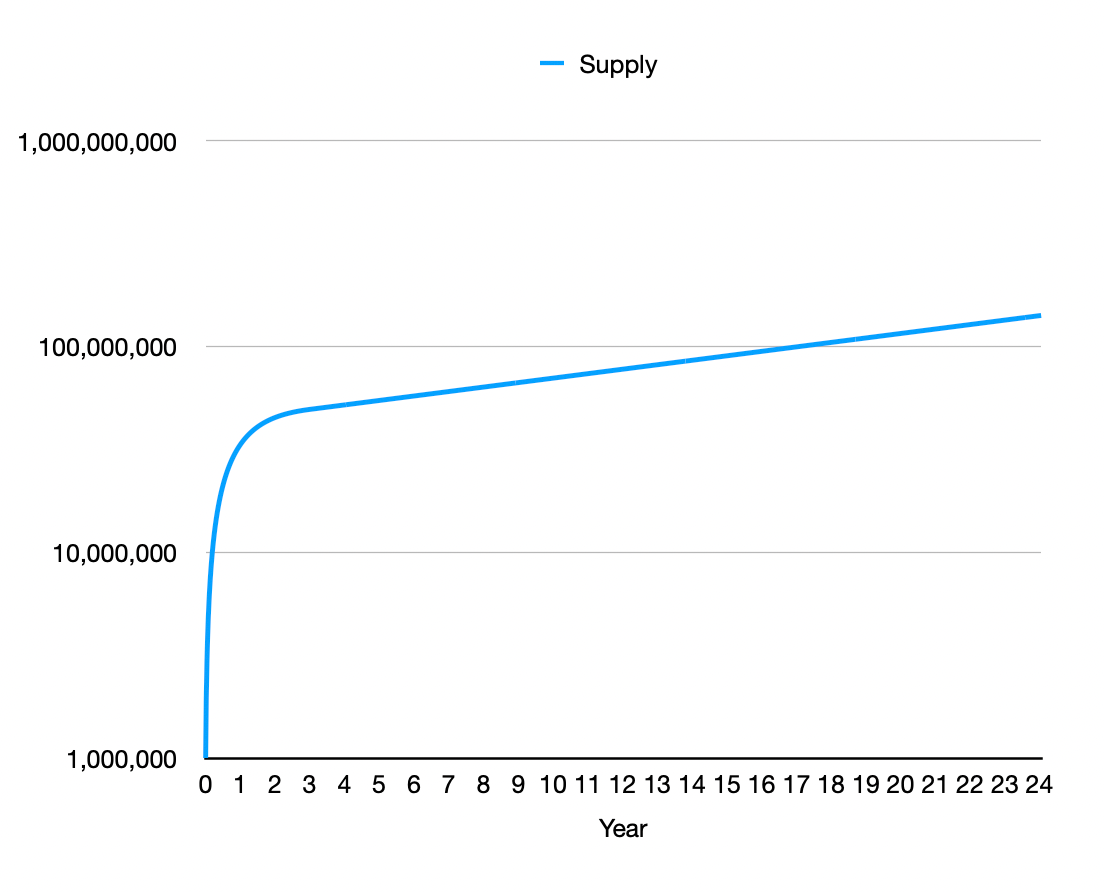
Given these two facts we propose a rate of issuance that falls by 50% per year (continuously) until the annual inflation rate reaches 5% APR at which point it remains constant. This 5% number is consistent with my theory of Universal Resource Inheritance (outlined in my book, More Equal Animals) where the resources of the world are fairly distributed over time from one generation to the next.
We also propose that the initial rate start at 1 million tokens per week. Given these parameters the token supply can be trivially graphed over the next 24 years.
The key difference between the inflation allocated by fractal governance vs the inflation of other currencies is that fractal governance is more likely to distribute the inflation to those producing public goods which grow the value of the currency instead of being syphoned off by insiders and graft.
Given this token model is fixed, we need a way to map the dynamic amount of respect from the weekly meeting attendance onto this fixed supply. This is achieved by dividing the total tokens distributed on a pro-rata basis to the total respect allocated in the meetings. More generally, this can be modeled as two currencies where one allocates shares of inflation in the other currency. The inflation shares are burned when converted to the newly issued fixed-rate currency.
A community can then dynamically adjust how it issues shares in the inflation across weekly meetings, teams, block producers, social media content, liquidity rewards, and staking without impacting the bigger picture of a stable and predictable currency supply.
Migrating Genesis Fractal
The Genesis Fractal has been running for a number of weeks and I would propose that the currency supply indiciated by the above model for that time period be pro-rata distributed among the respect holders who have participated thus far. Then going forward we can utilize the new model which more appropriately recognizes the early adopters who are making this all possible. With more respect for early adopters there is more incentive for people to join early and help us discover the most viable means of collaborating for our mutual benefit.
Disclaimer
Everything in this post is under development and presented for discussion purposes only. The final token distribution will depend upon the consensus of the Genesis Fractal.
Congratulations @dan! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 70 posts.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Support the HiveBuzz project. Vote for our proposal!
Feedback and clarification on this paragraph:
“We can therefore assume that any given measurement has a wide margin of error and that many measurements are required in order to get a more accurate measure of community consensus.”
This assumption requires clarification since repeated measurements only reduce statistical error.
There are two types of measurement error: 1) statistical error 2) systematic error
All measurement error is a combination of these two types of error and needs to be characterized and quoted separately in order to judge the merits of a proposed change to an experiment and its experimental apparatus.
Statistical error can only be reduced by adding additional measurements, while systematic error is always constant regardless of the number of measurements and is inherent to the experimental apparatus.
Systematic error can only be reduced by improving the experimental apparatus, which is part of what “Fractally White Paper Addendum 1” is proposing.
The proposed changes in this blog post hypothesize that reducing measurement error (a good thing) will be accomplished by reducing the systematic error (another good thing) by improving the experimental apparatus through the addition of a “high-pass filter” (aka a “high-value contributor filter”) to reduce low frequency noice (another good thing) in the form of a sliding/rolling window with the addition of a second consensus round populated with an improved source of signal.
The addition of a second consensus round improves the statistical error since it adds additional measurements to the experiment.
In conclusion, the proposed changes hypothesize that changing the experimental apparatus improve both the systemic error (through structural changes) and statistical error (through the addition of additional measurements).
I support the principle behind these changes when looked at through this perspective.
Someone (maybe me) could create a simple “measurement error calculator” for the fractally team to help them understand the pros and cons of this and future proposals. I would value this contribution. I may build this calculator unless someone beats me to it (which I encourage).
"Told you there was a token plan"
"So we aren't just meeting to celebrate blockchain and gossip about how much faster we are than PoW... hmm... Oh great, room is going to get crowded..."
This is a great job. Looking for a fairer classification is not an easy ask, however I believe that with their proposal you make a significant change.
The rewards earned on this comment will go directly to the people( @steemadi ) sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
"The net effect is that unless you believe that you are likely to achieve Level 4 to 8 in Round 2 then you have nothing to gain by being promoted."
Interesting and I believe original, and upon initial consideration, likely effective.
How does this benefit Hive? Or are you just trying to use the fork of your old project as a launchpad for yet another project to leave behind?
Thank you for your witness vote!
Have a !BEER on me!
To Opt-Out of my witness beer program just comment STOP below
Thank you for your witness vote!
Have a !BEER on me!
To Opt-Out of my witness beer program just comment STOP below
View or trade
BEER.Hey @lunaticpandora, here is a little bit of
BEERfrom @isnochys for you. Enjoy it!Learn how to earn FREE BEER each day by staking your
BEER.Me encanta el post, ahora lo leeré.
Excellent.
Not necessarily true. In the later rounds there will be fewer measurements but higher quality instruments.
Aside these comments, it looks like a great deal of effort and thought put into this addendum. It does feel like a significant experience/feedback based improvement. Great work guys.
I'd say let's put it to test!
Wow very interisting
Will there be an upcoming Genesis vote for the proposal in this blog post that is an all-or-nothing up-or-down vote by the Level 6 contributors from an upcoming weekly consensus meeting?
I think the answer is yes according to the Interim Group Consensus Process. Is that right?
Here is the relevant section from this blog post.
Here is the answer to my question:
Перевод на русский язык Дополнения 1 к Белой Бумаге Фракталли - https://hive.blog/fractally/@shakhruz/belaya-bumaga-fractally-dopolnenie-1
Подписывайтесь на мой телеграм канал чтобы узнавать подробнее о Фракталли и многом другом.
It would be cool to have fractal observers could also rate, which could be shown before, after or during consensus.
Crowd sourced fact checking, and multiplying you n score. Obviously this is a dream for sociology and psychology:). I knew that degree was a great pick.
Maybe for public or common goods meetings.
rePOSTed

for @logiczombie