pixabay

改了一点上回实现的搜索功能的逻辑。每当搜索文章发现这并不是我所需要的。之前的逻辑是搜索所有的tag, title, body值,即,tag OR title OR body。
tag和title/text本身就不是一个性质,所以不能这样实现。通常搜索,都是先搜索tag,然后在下级继续搜索title或者body。也就是说tag AND (title OR body) 。
哎~ 事先没明确设计,导致出现如此问题。没办法,只能再次改逻辑了。
顺便都改为python的类。虽然我不太懂python的类到底哪里好。(#当作学习#python初学者)
services.py
- 在 services.py 创建类,之后新建account, q_titles, q_texts, q_tags, blogs 类变量。
- 创建 init 函数,定义参数 query 并赋值给类变量
- 添加 search_posts 函数。
当tag为空或者有匹配值时继续检查title或body,并且把匹配值装入另一个list里。 - 另创建 is_keywords_contains 函数,内部检查 title 和 body 值。
- 创建一个 get_tags 函数
import json
from steem import Steem
class Search:
s = Steem()
account = 'june0620'
q_titles = []
q_texts = []
q_tags = []
blogs = []
def __init__(self, query: dict):
self.q_titles = list(filter(None, query['titles']))
self.q_texts = list(filter(None, query['texts']))
self.q_tags = list(filter(None, query['tags']))
self.blogs = self.s.get_blog(self.account, 0, 400)
def search_posts(self):
s_blogs = []
for blog in self.blogs:
blog_data = blog['comment']
title = blog_data['title'].lower()
body = blog_data['body'].lower()
tags = self.get_tags(blog_data['json_metadata'])
if not self.q_tags or set(self.q_tags) & set(tags):
if not self.q_titles and not self.q_texts:
s_blogs.append(blog)
elif self.is_keywords_contains(title, body):
s_blogs.append(blog)
return s_blogs
def is_keywords_contains(self, title: str, body: str) -> bool:
if any(q_title in title for q_title in self.q_titles):
return True
if any(q_text in body for q_text in self.q_texts):
return True
return False
def get_tags(self, json_metadata: str) -> list:
'''
steempython의 get_blog()함수의 json_metadata값이 str이므로 list로 변환
'''
metadata = json.loads(json_metadata)
if metadata:
return metadata['tags']
else:
return []
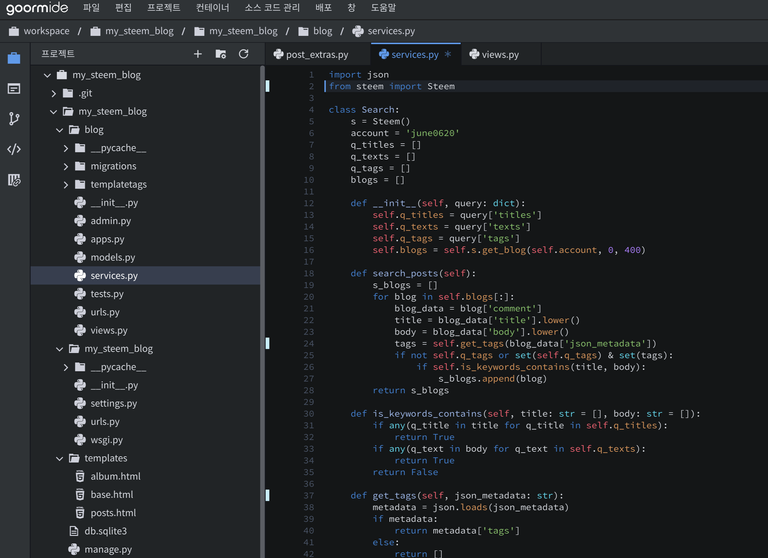
views.py
继承 django的 ListView,把文章目录装入 queryset 一并映射到 html。
from django.http import HttpResponse
from django.views.generic import ListView
from .services import Search
from steem import Steem
s = Steem()
def main_view(request):
data = s.get_account('june0620')
response = HttpResponse()
response.write(data)
return response
class posts(ListView):
template_name = 'album.html'
context_object_name = 'all_posts'
def get(self, request, *args, **kwargs):
# self.queryset = s.get_blog(kwargs['account'], entry_id=0, limit=100)
query = {
'tags': ['kr'],
'titles': ['python'],
'texts': ['사랑하겠습니다']
}
se = Search(query=query)
self.queryset = se.search_posts()
return super().get(request, *args, **kwargs)
Results
经简单测试,未发现问题。
下回学习 django 的 test 功能,再好好测试一番。
[Cookie 😅]
Python 3.7.4
Django 2.2.4
steem-python 1.0.1
goorm IDE 1.3
Congratulations @june0620! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
You can view your badges on your board And compare to others on the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Do not miss the last post from @hivebuzz: