Benchmarking serialization
I was discussing recently with a TYPO3 colleague about performance, specifically caching. Both he and I are working on systems that may involve hundreds or thousands of objects that need to be cached for later use. The objects themselves are fairly small, but there's a large number of them. The data format is only internal, so we don't need anything standardized or parsable by outside systems.
PHP actually has two options for this use case: serialize()/unserialize() and var_export()/require(). But which is better?
Quick, to the benchmark mobile! The results I found were not at all what I expected.

(Image courtesy of the ever-delightful Nathan Pyle of Strange Planet.)
(If you don't care about the details and just want the numbers, skip down to the "Results" section.)
The serializer(s)
PHP's serialize() and unserialize() functions have been around since time immemorial, although exactly how they work has varied. More specifically, there are three different ways that objects can hook into the serialization process to affect how they are represented.
- Implementing
__sleep()and__wakeup(). These callbacks take no arguments.__sleep()is called before the object is serialized to unset values that should not be serialized, while__wakeup()is called after to restore values. These methods are of limited use, and you should not use them. - Implementing the
Serializableinterface, which lets the object return a string representation of itself, and unpack the same string representation of itself. This approach has a number of downsides and can break nested objects, especially if there's circular relationships. You should not use it, and it is being deprecated and phased out. - Implementing
__serialize()and__unserialize(). These callbacks take and return an array of the object's data to be serialized/unserialized, but lets the object pick and choose what values to use. This is the only override mechanism you should use as of PHP 7.4.
Whether you use any hooks or not, serialize() produces an opaque PHP-specific string that has no use other than to be passed into unserialize(), to get the objects back. Additionally, unserialize() also supports a second argument to list what classes the incoming data may be deserialized into. That is necessary for security, as a carefully crafted serialized blob could inject alternate objects into a deserialized payload and produce unexpected results, including security holes.
PHP's secret code generator
It's not often used, but PHP has another way to dump out values to a string or disk: var_export(). This function takes an arbitrary variable and produces a string of PHP code that will reconstitute that variable. So exporting the string "hello" produces the code string "hello", which can be safely used in an assignment statement. The standard way to use it is something like this:
$code = "$exported = " . var_export($something, true) . ";";
$code can now be executed (usually via a require statement; please don't use eval()) to produce a variable exported that is the same as the original value. That's great, but what about objects? They don't have a clear literal version.
For objects, what var_export() does is hard code passing all assigned properties of the object to another magic method, __set_state(). This static method acts as a named constructor, and therefore you must implement it on a class you want to be re-hydrated. For example, a class like this:
class Test
{
public function __construct(
public readonly int $i,
public readonly string $s = 'dummy',
) {
}
}
Would look like this when exported:
Test::__set_state(array(
'i' => 1,
's' => 'dummy',
))
You can implement whatever logic you want in __set_state(). A general purpose implementation would look like this:
public static function __set_state(array $data): static
{
static $reflector;
$reflector ??= new \ReflectionClass(static::class);
$new = $reflector->newInstanceWithoutConstructor();
foreach ($data as $k => $v) {
$new->$k = $v;
}
return $new;
}
The reflector caching is optional, but reflection is needed in order to bypass the constructor and assign properties manually. Alternatively, if the properties are all constructor promoted (as in this example), a more compact version would work as well:
public static function __set_state(array $data): self
{
return new self(...$data);
}
The tests
Tests were run on my local laptop, a 7th Gen Lenovo Thinkpad X1 Carbon with 16 GB of RAM running Kubuntu 21.10. Obviously if you have a different system your absolute results will be different but the relative values should be about the same.
I had two sets of tests. One was run from the CLI in a Docker container, with PHP 8.1.7, using PHPBench. The other was run from a default Lando LAMP configuration, using Apache Bench. The web version used PHP 8.1.1, because Lando's PHP container is a little out of date. I don't expect there to be any meaningful difference between those point releases, however. XDebug was disabled.
Apache Bench's output is awful and not designed for scripting, so I wrote an awful PHP script to wrap it and produce output in a usable form.
The full code base of the tests are available on GitHub. I won't go over it in much detail here other than to highlight a few things:
- The test value I used consisted of an object with four properties. One leaf object, one object that was deeply recursive, and two lists of sub-objects, one associative and one sequential. Mainly I was curious if the nested depth of sub-objects made a difference.
- All test runs were defined in a
Makefile, for easier repeatability. - I scaled both the list sizes and the recursion depth up pretty high. The recursion depth I could not raise above about 500, as I ran into memory issues. That's odd, as the memory results I got were very inconsistent and not telling of anything at all, frankly. The list sizes I scaled up as high as 20,000 objects total between the two lists.
- A setup script was used to produce serialized files for each approach that could be deserialized reliably. The same script was used for both the CLI and web versions.
Prediction
Like any good scientist, I am registering my expected result. My prediction going in was that:
require()ing a code file generated byvar_export()would be the fastest way to import data, thanks to the opcache having the file already parsed. It would "just" be a bunch of method calls, since no string parsing would be required.- Using the constructor-based version of
__set_state()would be faster than the reflection-based one. - Using
unserialize()with an allowed class list would be slower than not specifying one. - Using the
__unserialize()magic method would be slower than using the default logic.
This all seemed logical to me. Does it to you? Let's see if PHP is logical...
Results
The raw data is available in a Google Spreadsheet. I'll just show the pretty charts here.
Here's the results at different total object counts (between both the lists and the recursive objects), running on the CLI, as returned by PHPBench:
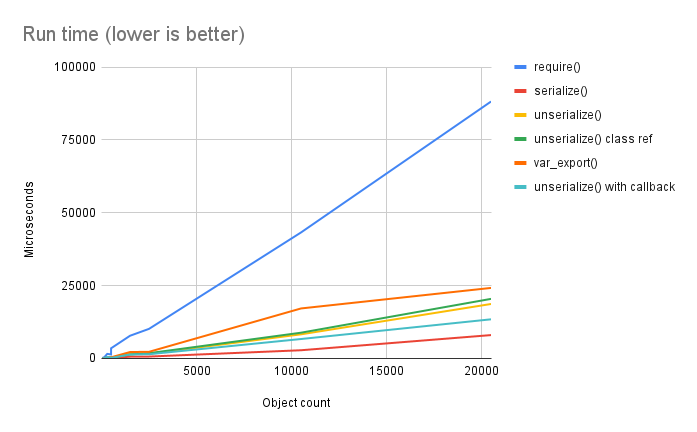
Well, that's... not at all what I expected! require() is by far the slowest option. However, that's not completely surprising. Bear in mind the CLI doesn't benefit from the opcode cache, as there's no persistent process in a web server or PHP-FPM to store it. That means the file has to be reparsed on each run, which is going to undermine all the benefits I'd expect to see. Though it's also interesting to see that var_export() is slower than serialize(), consistently.
What's more interesting is the different versions of unserialize(). Unsurprisingly, restricting it to certain classes slows the function down a bit, but not by much. What is far more shocking is that having a manual, user-space __unserialize() method... is faster than the native logic. That I did not expect at all, and I frankly have no explanation for. It confuses me greatly, but was very consistent even when I reran the tests multiple times.
There's an interesting little kink in the require() line, though. Let's zoom in a bit:
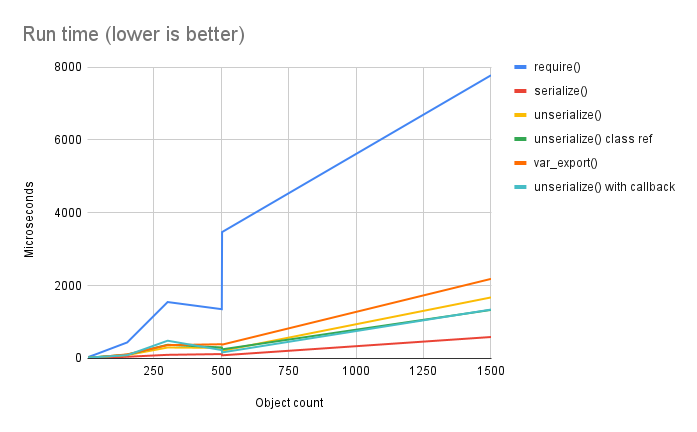
That represents 2 data points at 500 total items; one in which they're all in the deeply-recursive object, one in which they're in the flat lists. Looking at the raw data, the deeply-recursive one is the higher time. I'm not certain if that makes sense, but it probably does.
Of course, I wouldn't call this a really fair test without an opcache. We've known for a decade that PHP without an opcache is stupidly slow, which is why it's enabled by default. So instead, let's look at the web request tests with Apache Bench, which does have a working opcache.
Here's the results for 1000 requests with concurrency=1. I only tested the deserialization cases, as those are the more important and the ones where the opcache would make a not able difference.
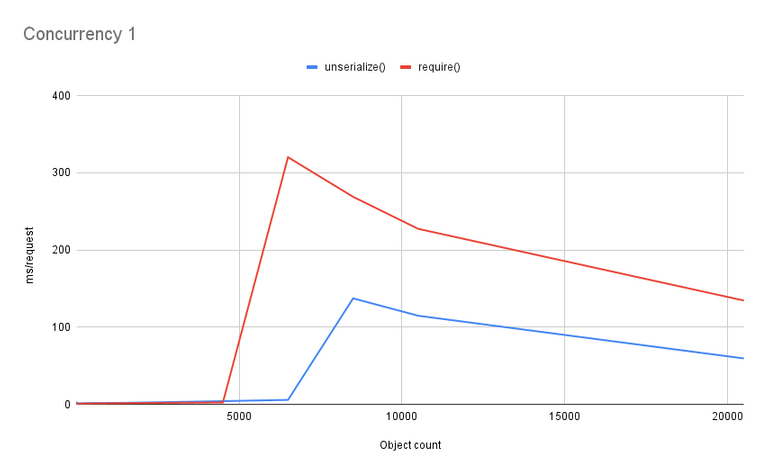
Well, that's fascinating... The huge jump for require() around 5000 objects or so is something I've seen before in performance tests. That's the point at which the file gets too big for the opcache, and so the opcache gives up on it. You can tweak the opcache total memory size and individual file size, so let's put a pin in that for the moment.
What I have no explanation for is the big jump for unserialize() around 6000-7000 items. And I have even less explanation for both lines declining after those initial spikes. If someone has a theory, I'm open to hearing it.
It looks like there is some divergence in the lines before the big spike, so let's remove the higher-cardinality data and zoom in on that:
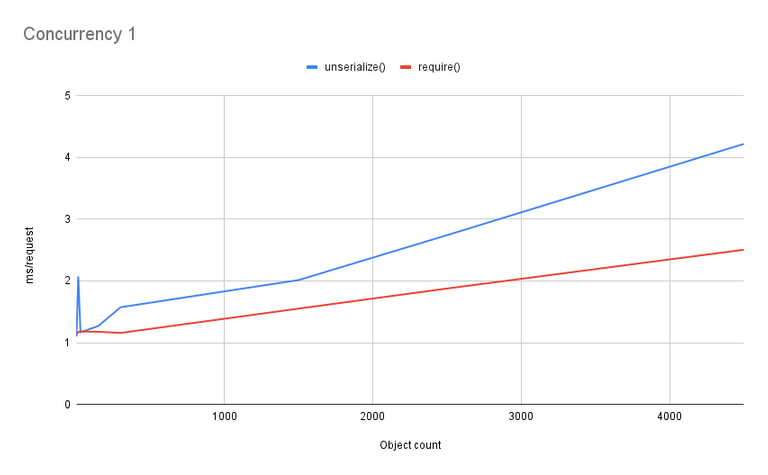
Ah, now that's more what I was expecting! Skipping the odd spike right at the start (likely a testing artifact), require() is faster, and consistently so... right up until we hit the opcache memory limit, and then it's vastly worse. That's more consistent with what I would expect to see. The difference is small in absolute terms (about 1.25 ms per request at best), but large as a percentage.
Let's crank the concurrency up to 10 and see what happens.
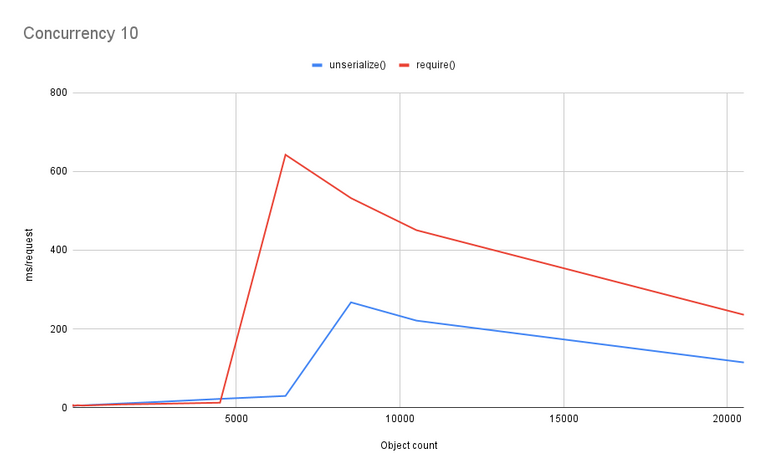
Almost identical to the concurrency=1 test, although it looks like the require() advantage below the opcache limit is a bit larger. Looking more closely, it's about a factor of 2. The same opcache limit exists, though, as well as the bizarre improvement after the initial spike.
So what happens if we increase the opcache size? The largest my test case gets is a 3.6 MB PHP file, so let's crank the opcache.max_file_size all the way up to 10000 (in bytes) and see what happens. I only ran this at concurrency 10, since that's where I'd expect to see the biggest benefit.
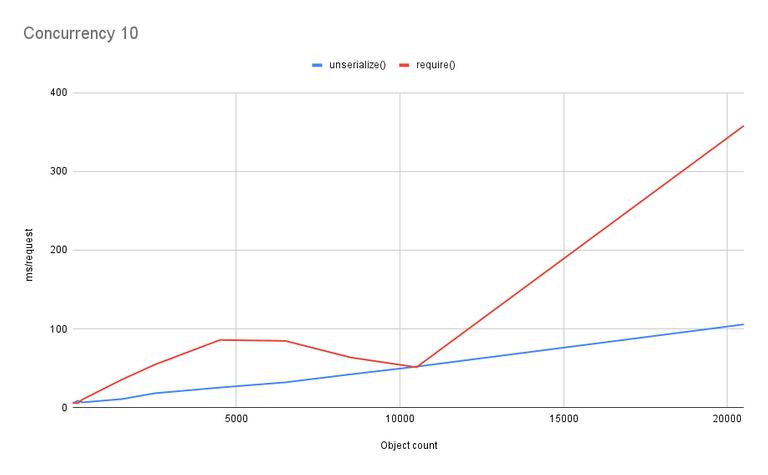
I... what? I ran the test suite multiple times with these settings and got the same result, because it makes little sense to me. Like, none of it. At extremely low cardinality (all the way to the left), there's a brief period where require() is faster than unserialize(). Then it spikes up, but at a much lower size than before. Then it... levels off, goes down, and then spikes up again? Meanwhile, unserialize() is a steady linear growth, which is what I would expect, but would have expected on all tests, not just the one with a larger opcache.
I am at a loss to explain any of this behavior.
There is one last test I wanted to see, and that's comparing the constructor-based __set_state() vs a reflection-based one. For this test, we'll keep the opcache file size high. (I tried it without and the results were... predictably nonsensical.) We'll run two web requests with cardinality 1, so that we get the opcache. I also increased the granularity of the tests a bit.
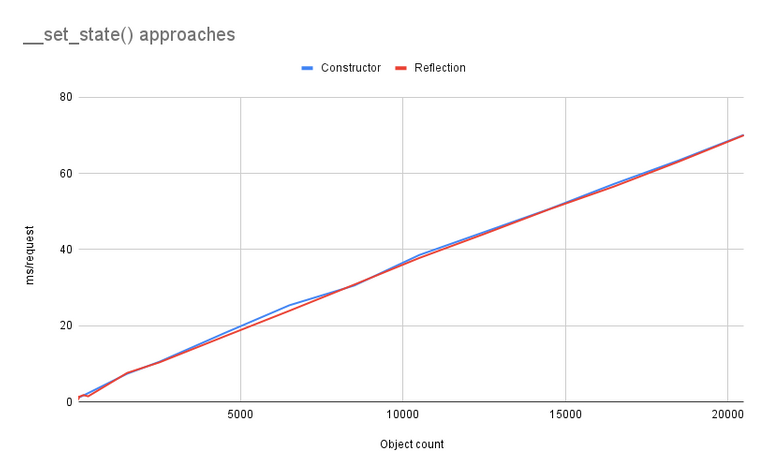
Finally, results that make logical sense! Specifically, it seems there's no real difference in practice at most cardinalities. Sometimes the constructor is faster, sometimes reflection, but the difference is small enough to just be test jitter. For any practical purpose, there's no difference.
Conclusion
Let's see how well my predictions held up.
require()faster thanunserialize(): Sort of. Or rather, it is only under very specific circumstances: If the cardinality is low enough to fit in the opcache, and the opcache is active, then there is a measurable but not drastic difference. But then you have to worry about opcache size, and in either case, the absolute time is still quite small in either case.- Constructor-based
__set_state()vs Reflection: Nope, no meaningful difference. unserialize()is slowed down with an allowed class list: Yes, but only a little bit.__unserialize()would be slower: No, it's actually faster(!)
Clearly not what I expected.
I still cannot explain much of the behavior I'm seeing, particularly at higher cardinalities. My guess is that the engine and opcache are doing all kinds of weird optimizations that make tests like this unreliable, but I don't know the engine well enough to say. If any engine-nerds are reading this, please let us know in the comments what's going on.
What should we conclude from these results?
I think my conclusion is that, although serializing to PHP code sounds reasonable, it's really not a win in practice. Or rather, the scenarios in which it is a win are narrow, and the difference is not large enough to justify the added work of implementing __set_state() in every class to be serialized, securing the generated file, monitoring the opcache, etc. The ROI just isn't there. Basically, unserialize() has gotten good enough that var_export()/__set_state() just isn't needed anymore. I'm both surprised and disappointed by this, but the data seems clear.
There are non-performance reasons to use var_export()/__set_state, of course. If you're using it for those reasons, don't bother with a Constructor-based version of __set_state(). It seems like it should be faster, but it's not. I guess Reflection is just way faster than anyone expects. (Benchmarks for another time...)
Finally, and this one I cannot explain at all, if you want to speed up your unserialize() calls, a manual generic __unserialize() seems to have a measurable performance boost. I don't know why, but perhaps that's something for the core implementation to work on? I don't think I'd recommend doing so by default, but if you're trying to optimize some serialization system then building your own __unserialize() is something to look at.
May your code be fast and your benchmarks predictable. Until next time...
(With thanks to Christian Kuhn and Oliver Hader of TYPO3 for their inspiration and assistance in these benchmarks.)