
La régression linéaire est une des méthodes de régression des plus courantes et des plus simples à mettre en place en Machine Learning.
Ici, nous sommes en présence d'un modèle paramétrique, c'est-à-dire un modèle ayant un nombre de paramètres constant. Il s'agit d'un modèle rapide, mais avec des présupposés forts à propos des données sous-jacentes[1]. Ces biais inductifs concernent généralement la distribution des données, de p(y|x) ou de p(x) selon le problème posé.
Background
La régression linéaire est souvent définie avec les données d'entrée x, leurs poids associés w, et une erreur résiduelle ε assumée normalement distribuée par :
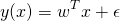
ou
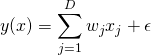
Ainsi, la régression linéaire est définie avec θ les paramètres du modèle et σ l'écart-type de la distribution d'ε par :
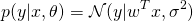
Estimation des paramètres
En supposant que N données sont indépendantes et identiquement distribuées (hypothèse iid), les paramètres sont estimés en minimisant la log-vraissemblance négative (NLL)** :
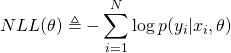
Avec la somme des erreurs au carré (SSE), l'implémentation classique vise à trouver les différents poids w et le biais w0 en minimisant l'erreur. Cette méthode est souvent appelée méthode des moindres carrés.
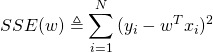
Python
Dans un premier temps, il convient d'importer les différentes librairies qui seront utiles à l'implémentation efficiente d'une régression linéaire.
import numpy as np # Pour la génération des données
import matplotlib.pyplot as plt # Pour la visualisation
from sklearn.linear_model import LinearRegression # Pour l'implémentation de la régression linéaire
Il faut ensuite générer nos données vérifiant l'hypothèse iid.
# Paramètres réels
gradient = 0.5
w0 = 1
# Création des données
X_train = 2 * np.random.random_sample((20, 1))
y_train = gradient * X_train + w0 + 0.1 * np.random.random_sample((20, 1))
# Affichage
plt.scatter(X_train, y_train);
Maintenant, place à l'utilisation simple et efficace de la régression linéaire, en passant par la librairie Scikit-Learn.
# Définition et entraînement du modèle
model = LinearRegression(fit_intercept = True)
model.fit(X_train, y_train)
# Création de la population de test
X_test = 2 * np.random.random_sample((10, 1))
y_test = gradient * X_test + w0 + 0.1 * np.random.random_sample((10, 1))
# Calcul du score
r2 = model.score(X_test, y_test)
print("Gradient : {}\nBiais w0 : {}\nR2 : {}".format(model.coef_,
model.intercept_,
r2))
Gradient : [[0.49493139]]
Biais w0 : [1.04069008]
R2 : 0.9911788822610862
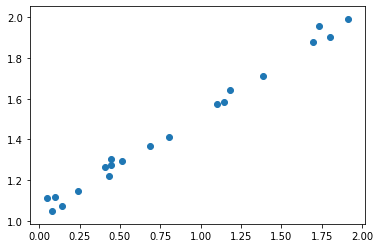
En appelant la méthode fit() de notre modèle, le gradient est estimé à 0.49 (au lieu de 0.50), et le biais w0 est estimé à 1.04 (au lieu de 1.00). Sur un jeu de test, le modèle atteint un score (R²) de 0.99, représentant un ajustement quasi-parfait.
# Affichage des données, de la prédiction et de la vérité
x = np.linspace(0, 2, 10).reshape(-1, 1)
y_truth = gradient * x + w0
y_estimated = model.coef_ * x + model.intercept_
plt.scatter(X_train, y_train, label="Données")
plt.plot(x, y_truth, label="Réalité")
plt.plot(x, y_estimated, label="Modèle")
plt.legend();
Une fois notre modèle défini et entraîné, il est possible de réaliser des prédictions sur de nouvelles données.
# Prédiction d'une nouvelle observation
observation = np.array(1).reshape(-1,1)
y_pred = model.predict(observation)
y_truth = gradient * observation + w0
print("Prédiction : {}\nVérité : {}".format(y_pred, y_truth))
Prédiction : [[1.53562147]]
Vérité : [[1.5]]
Références
[1] Murphy, Machine Learning : A Probabilistic Perspective. 2012.
60s (Data) Science est un nouveau format d'articles ayant pour objectif d'introduire et de présenter rapidement des concepts en Sciences, et Sciences de Données. Tout feedback sera apprécié à sa juste valeur :)

Bannière par @nitesh9 et @rocking-dave
Merci aux communautés #SteemSTEM et #FrancoSTEM pour leur aide et leur soutien ! <3
Nice programing post :)
!trdo
Congratulations @cryptoyzzy, you successfuly trended the post shared by @clement.poiret!
@clement.poiret will receive 0.06184350 TRDO & @cryptoyzzy will get 0.04122900 TRDO curation in 3 Days from Post Created Date!
"Call TRDO, Your Comment Worth Something!"
To view or trade TRDO go to steem-engine.com
Join TRDO Discord Channel or Join TRDO Web Site
Congratulations @clement.poiret, your post successfully recieved 0.0618435 TRDO from below listed TRENDO callers:
To view or trade TRDO go to steem-engine.com
Join TRDO Discord Channel or Join TRDO Web Site
Congratulations @clement.poiret! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
You can view your badges on your board And compare to others on the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @hivebuzz: