
Not long ago, AskSteem project was shutdown and Dapps such as @DTube and @SteemTelly that were using their API suddenly lost search functionalities. My @SteemTelly app was using AskSteem for doing keyword search and related content search.
I initially replaced the AskSteem’s API with my own, powered by @steemsql but I got inspired by Tower, a Steem API project by Steem Witness @emrebeyler powered by Hivemind. So I decided to try setup a Hivemind node and see what it can offer.
Hivemind
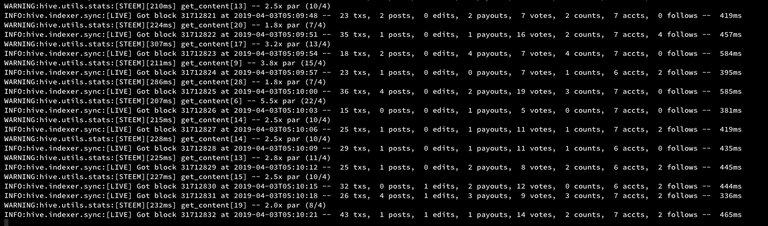
Hivemind is a layer sitting above steemd, the Steem blockchain software. It is indexing social data into a Postgres SQL database. This allows us to do search on accounts, posts, comments, reblogs, follows using SQL queries instead of accessing the blockchain directly. Not only it is faster but it also require a less powerful server than running a full RPC node.
My Hivemind node is running on a baremetal server with:
- 32GB of RAM
- 50 GB network SSD root disk
- 250 GB local SSD data disk
I could run with 16 GB of RAM but that’s the config I’m getting for that amount of disk space.
Hivemind is currently using 186 GB of disk on the data disk and 17 GB on the root disk. In order to optimise disk space usage, I split the data of Postgres database onto the two disks. We’ll come back to this later.
Initially, I was running Hivemind and Postgres inside two Docker containers on my old server with a HDD disks. But the disk speed and probably network speed was too low and after almost three weeks the blockchain synching was not completed. So I transferred the Docker images to another server and completed the synching within 2 extra days.
New Postgres indexes

Once Hivemind has completed the initial sync, I started to dig into the Postgres tables to see what data were in there. What I needed for @SteemTelly was present, however, a lot of that data was in side in the form of a JSON string in a text column. Luckily, Postgres allows me to access the data as a JSON object and after creating a few extra indexes, I was able to perform some useful searches at decent response time.
Indexes are ways to optimise search processes inside a database. Because the Steem blockchain is rather large, having indexes setup for specific search functions is important.
Here are the ones I added to my Hivemind setup.
CREATE INDEX ON hive_posts_cache((json::json->>’app’));
CREATE INDEX ON hive_posts_cache(created_at);
CREATE INDEX ON hive_posts_cache(author);
CREATE INDEX hive_posts_cache_json_video_tags_idx ON hive_posts_cache((json::json->’video’->’info’->>’title’));
CREATE INDEX hive_posts_cache_json_audio_genre_s_idx ON hive_posts_cache((json::json->’audio’->>’genre’));
CREATE INDEX hive_posts_cache_json_audio_title_idx ON hive_posts_cache((json::json->’audio’->>’title’));
CREATE INDEX hive_posts_cache_json_video_tags_idx ON hive_posts_cache((json::json->’video’->>’tags’));
CREATE INDEX hive_posts_cache_json_audio_tags_idx ON hive_posts_cache((json::json->’audio’->>’tags’));
@SteemTelly requires to retrieve posts from the blockchain that contains specific data. Retrieving posts tagged with #dtube or #dsound is not enough because someone could create a simple text blog post using that tag. I needed the database to give me valid posts so it needed to search within the json_metadata property of the post object. Inside Hivemind’s Postgres database, the json_metadata property is stored in the ‘hive_posts_cache’ table under the column ‘json’.
So to get a valid DTube video post I’m searching for posts that:
- have ‘json.app’ starting with ‘dtube’
- ‘json.tags’ contains ‘tube’
- ‘json’ contains a property ‘video’
To find related content or perform searches, I use the same filters as above and additionally, I also check for ‘json.video.info.title’, ‘json.video.content.tags’, ‘json.audio.title’, ‘json.audio.genre’ and ‘json.audio.tags’.
Luckily, Postgres also allows me to create indexes on a JSON property which is very cool.
Steemulant’s Steem REST API
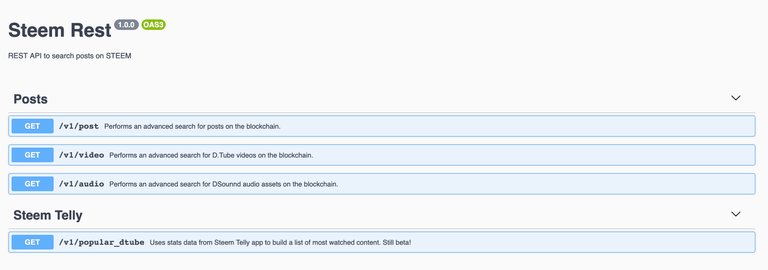
Once the indexes were created and after some test queries, I started to write a REST API to access the data. The project was created using NodeJS using ExpressJS and is documented using Swagger following OpenAPI 3.0 specifications.
I’ve hosted in under my catchall project repository @steemulant. It is, currently, publicly available at:
http://steemrest.steemulant.com/api-docs/
There is no guarantee that these endpoints will remain public for longer term, so keep that in mind if you use them. It will all depends on how much traffic the service will receive.
Here are examples of what you can do with the current version of Steemulant’s Steem REST API:
- 20 most recent posts on Steem: http://steemrest.steemulant.com/v1/post
- 20 most recent posts by @SteemTelly: http://steemrest.steemulant.com/v1/post?author=steemtelly&age=60
- 20 most recent comments mentioning @quochuy within the last 30 days: http://steemrest.steemulant.com/v1/post?type=comments&bodyContains=%40steemtelly
- 20 most recent videos on @DTube by @quochuy with full body and json metadata within the 30 last days: http://steemrest.steemulant.com/v1/video?author=quochuy&age=30&includeBody=true&includeJson=true&sortBy=post_id%7Cdesc&offset=0
- 20 most recent Pop performances on @DSound in the last 30 days: http://steemrest.steemulant.com/v1/audio?age=30&audioGenre=pop
Postgres disk space usage optimisation
Initially, Postgres was using disk space on the 250 GB SSD disk. After the initial sync, there was about 24GB of disk space left. Adding the extra indexes was reducing that available space even more. I’ve however, have around 35GB of free space on the root disk. So before I consider switching to another server or add additional disks, I went searching for ways to spread a Postgres DB to multiple disks. Two solutions were found:
- Using table partitioning: I could create child tables with inheritance and then move data from the master table into the child tables following rules: data from 2016 goes to child_2016, 2017 data goes to child_2017 for example.
- Using tablespaces: they are just named locations on disk where PostgresSQL stores data.
I chose the tablespaces solution as it was the easiest to implement on an existing database already containing data:
- I created a new directory on the host machine and mounted it as a volume inside docker under /postgres_space/data
- I then executed those Postgres commands inside the container, they create the new tablespace at the specified location and move the tables and their content to it:
CREATE TABLESPACE hive_posts_follows_space LOCATION ‘/postgres_space/data’;ALTER TABLE hive_follows SET TABLESPACE hive_posts_follows_space;ALTER TABLE hive_posts SET TABLESPACE hive_posts_follows_space;
Moving the data to the new tablespace only took few minutes and this will give me quite a bit of time before I need to consider upgrading.
Other optimisations
Nginx Proxy was also installed as a Docker container, this allows me to assign different hostnames to the custom port for Hivemind and the API. I will also setup some rate limiting rules.
The API is behind CloudFlare CDN which gives some performance thanks to the cache and a security layer that CloudFlare offers.
Previously on my blog:
- Witness Earnings Report - 2019-04-01
- DIY Hobie Sail Rudder and Turbo ST Fins upgrade
- I have received my first order from Homesteaders Co-op
Vote for my witness
On Steem, Witnesses are playing the important role of providing a performant and safe network for all of us. You have the power to choose 30 trusty witnesses to package transactions and sign the blocks that will go in the Steem blockchain. Vote for me via SteemConnect to help me do more useful projects for the communities.
| I'm a member of | these communities |
|---|---|
 |  |
 |  |
 |  |
 |  |
 |
Credits
- The image at the top has been generated with the Canva app using my own photo.

Banner by @josephlacsamana
Protect your money against Phishing Scam!
Cryptos accounts are the target of international scammers because they want your hard earned money!
Those people are very clever and in a moment of inattention, you've given them your login and password!
I've created a Chrome extension that can help you detecting scam links!
Install Steemed Phish Chrome desktop browser extension now!
Password and Private Keys security
You all know that your Steem password is the access to all your STEEM, SBD, posting, transferring, everything... right?
So, please, follow these simple steps and keep yourself safe:
- Apart from the initial setup of your account, NEVER use your password ANYWHERE, if stolen, it will give full control to your Steem account.
- Backup your password and keep it somewhere safe. Use a password manager like Lastpass, print it on paper and put it in a safe (no kidding). If you forget your password, no one can help you out.
- To login for creating content and curating, use your Private Posting Key
- To make transfers and account operations, use your Private Active Key
- To encrypt and decrypt memos, use your Private Memo Key
Congratulations! This post has been upvoted from the communal account, @minnowsupport, by QuocHuy [witness] from the Minnow Support Project. It's a witness project run by aggroed, ausbitbank, teamsteem, someguy123, neoxian, followbtcnews, and netuoso. The goal is to help Steemit grow by supporting Minnows. Please find us at the Peace, Abundance, and Liberty Network (PALnet) Discord Channel. It's a completely public and open space to all members of the Steemit community who voluntarily choose to be there.
If you would like to delegate to the Minnow Support Project you can do so by clicking on the following links: 50SP, 100SP, 250SP, 500SP, 1000SP, 5000SP.
Be sure to leave at least 50SP undelegated on your account.
Hi, @quochuy!
You just got a 0.16% upvote from SteemPlus!
To get higher upvotes, earn more SteemPlus Points (SPP). On your Steemit wallet, check your SPP balance and click on "How to earn SPP?" to find out all the ways to earn.
If you're not using SteemPlus yet, please check our last posts in here to see the many ways in which SteemPlus can improve your Steem experience on Steemit and Busy.
hello I need all the steem blockchain data to analyze them. Can you help me how to get the block data?