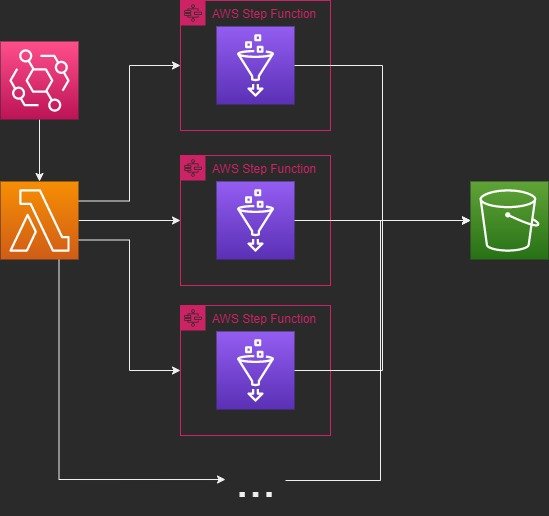
In this article, we'll discuss how to utilize AWS Glue, Step Function, and Lambda to enable you to run ETL workloads at any scale.
I will assume a basic understanding of some common AWS services, like Lambda, Glue, and Step Functions.
This is particularly useful if your data is partitioned by some criteria and you need to do some kind of ETL on this data. For example, if you had data in S3 partitioned by organization/provider in CSV/XML/JSON, and needed to convert this into a standardized data model for processing. These practices could be taken and used in other areas as well.
Create the Glue Script
Our glue script (Python) will read a DynamoDB change log that exists in S3 and then send a message per changed row. The creation of this change log is beyond the scope of this article, however it could be covered later in another article.
change_log_dir = args["change_log_dir"]
provider = args["provider"]
change_log_dynf = glueContext.create_dynamic_frame.from_options(
connection_type="s3",
connection_options={
"paths": [change_log_dir + "/provider=" + provider],
"useS3ListImplementation": True,
"recurse": True,
"groupFiles": "inPartition",
"compressionType": "gzip"
},
format="json",
transformation_ctx=args['env'] + "-change_log_bookmark_ctx"
)
// you can now convert the Dynamic Frame to a Dataframe
// and use native PySpark to do ETL operations
conv_df = change_log_dynf.toDF()
// ETL...
This is just a small snippet to give context, the main focus here will be on the orchestration pieces. Create your Glue Job however you need it.
change_log_dir and env can be set as environment variables when you create your glue job so that you can create multiple glue jobs if you have different environments. provider will be passed from the Step Function so we can run these dynamically.
TIP: The great part here about AWS's Dynamic Frame bookmarks is that they keep track of what data has and hasn't been processed yet for you! The transformation_ctx here is literally all you need to implement a robust Glue Job bookmark into your job.
Create the Step Function
AWS provides a fantastic interactive GUI for creating state machines, so I highly recommend you use that in order to create a step function that best fits your needs. Here is a JSON snippet for invoking the Glue script
"Start change_log Glue Job": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun.sync",
"Parameters": {
"JobName": "etl-${dev}-change_log",
"Arguments": {
"--provider.$": "$.provider"
}
},
"Next": "Update Status Success",
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"Next": "Update Status Failed",
"ResultPath": "$.result"
}
],
"ResultPath": null
}
This piece of the state machine will start our glue job we created in the last step (note that the name in JobName and the name of your Glue Job must match). It will go to the next step Update Status Success if the Glue Job completes successfully, otherwise it will go to Update Status Failed. You can modify this as necessary.
The provider variable will be passed in from the lambda in the next step.
${dev} is a substitution variable and can be replaced via DefinitionSubstitutions in a CloudFormation template. You can replace it with your hard coded env or exclude it if you do not have multiple envs.
Create the Lambda
Your lambda will need some way to know which partitions (providers) to run the data on. We handle this through an external API that keeps configurations of how often each partition needs to run. Again, this is outside the scope of this article.
import os
from datetime import datetime, timedelta
import boto3
import requests
import json
url = os.environ["api_url"]
headers = {"x-api-key": os.environ["api_key"]}
def lambda_handler(event, context):
start = datetime.now()
client = boto3.client('stepfunctions')
response = requests.get(url, headers=headers)
response = response.json()
for resp in response:
if response[resp]['status'] != 'running':
interval = int(response[resp]['frequency'])
last_success = datetime.strptime(
response[resp]['last_success'], "%a, %d %b %Y %H:%M:%S %Z"
)
if start - last_success > timedelta(minutes=interval):
client.start_execution(
stateMachineArn=os.environ["stepfunc_arn"],
input=json.dumps({"provider": resp})
)
// An example API response for context
{
"providerA": {
"frequency": "120",
"last_success": "Tue, 08 Nov 2022 15:47:17 GMT",
"status": "succeeded"
},
"providerB": {
"frequency": "30",
"last_success": "Tue, 08 Nov 2022 16:31:09 GMT",
"status": "succeeded"
}
)
Our API gives us a list of the S3 partitions we need to execute our Glue Job on as well as how often it needs to run and when the last time it successfully ran was. Those pieces are updated via the Step Function in the previous step and can easily be configured using the AWS state machine GUI. However, architect and configure those pieces however you see fit.
The Lambda will iterate through the API response of S3 partitions, figure out if that partition needs to run now, and then trigger a concurrent step function per-partition.
stepfunc_arn is an environment variable that can be configured when the lambda is created.
Create the Event Rule for Triggering the Lambda
This step is pretty simple. Just go to AWS' EventBridge service > Rules > Create rule. Name it whatever you'd like, put it on a schedule, and set the cron to whatever schedule you need it to run on (I choose every 15 minutes). Then target the Lambda service we just created.
Conclusion
This method of orchestrating ETL on partitioned data sets is extremely fast through a threaded approach, and cost effective with the orchestration pieces costing you pennies to run every year! I hope you've learned something and I hope you'll be able to apply this to create something incredible!
Congratulations @fritolays! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 50 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!
@fritolays - Welcome to the Hive Blockchain! Hope you can find people to connect with and can mutually support.
Thanks @sumatranate ! Glad to be here and excited to continue contributing!