This article continues the series “Decentralization and Blockchain as Tools.” In the previous article of this series, we discussed the problems which can be solved using decentralization and blockchain. However, once we identified the problem, we need to build a solution. In this article, I want to demonstrate an iterative process of introducing decentralization into a software product.
Step 1. Fully centralized prototype
This step is essential. I cannot overemphasize this point: you should always build a centralized prototype of your system before going for any decentralization. I would even argue that for most real-world problems centralized solution should be fully implemented and shipped before entertaining the advantages of decentralization. But if your particular domain demands a decentralized solution from the very beginning, you still should build a centralized prototype first. Here are some reasons why.
Ease of implementation
Decentralization is hard. Designing and implementing a decentralized system always demands an order of magnitude more work than a centralized one. Additionally, your team is probably way more proficient in building centralized solutions. As a result, chances of something going wrong are way higher with decentralized solutions.
End-user applications
Never forget your end-users. User experience should not be dependent on the nature of tools. Meaning that you end-user should not even feel the difference between centralized and decentralized solutions (goal to strive for but hardly achievable as far as state-of-the-art goes). What that means is that you can perfect your end-user applications without combating problems of “backend decentralization.”
User research
While user research should be done way before coding anything and you should have an excellent understanding of your users by the time you start designing and consequently implementing, having an actual working end-user application allows us to begin getting metrics and statics. At this point, it is not too late to figure out that “Oh shoot! We are doing the wrong thing! People actually want xyz not abc”.
Demonstration and Presentation
It is always helpful for your marketing team to have some kind of product to show.
Economic modeling
A lot of blockchain projects demand a rather sophisticated economic model to work. While you can do all the modeling with a bunch of formulas and assumptions, it is always handy to have an environment which can be used to run imitation models. “What if X users buy Y tokens at time T?” You can give your mathematicians and economists a handy tool here.
General playground
To continue the idea of tests, every assumption should be tested as early as possible. And a centralized solution is perfect for this.
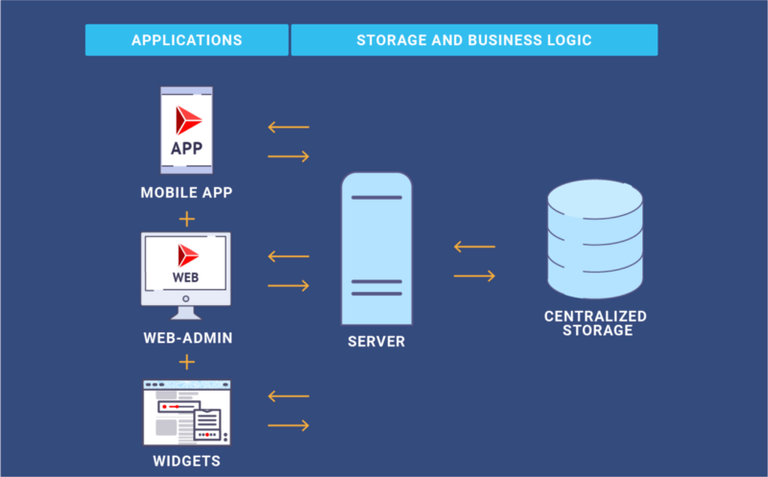
Step 2. Partial Decentralization
Next, you need to identify the parts of the solution where decentralization will bring the most benefits. While from a philosophical standpoint it is often necessary to bring decentralization to all parts of the system to achieve a desired level of decentralization, in practice I strongly advise introducing decentralization gradually.
For example, let’s say we need a right tool for tasks:
- Value transference on a global scale.
- Secure storage of value.
As we discussed in the previous article one of public blockchains can be a good fit for these tasks. At this point, we probably can use one of the existing payment gateways which can work with public blockchains. However, if we need to add logic which controls value evaluation, token emission or tokenomics, in general, we often have to introduce blockchain based smart-contracts since centralized solutions for these tasks will compromise the solution.
Even this step adds a ton of complexity to your system.
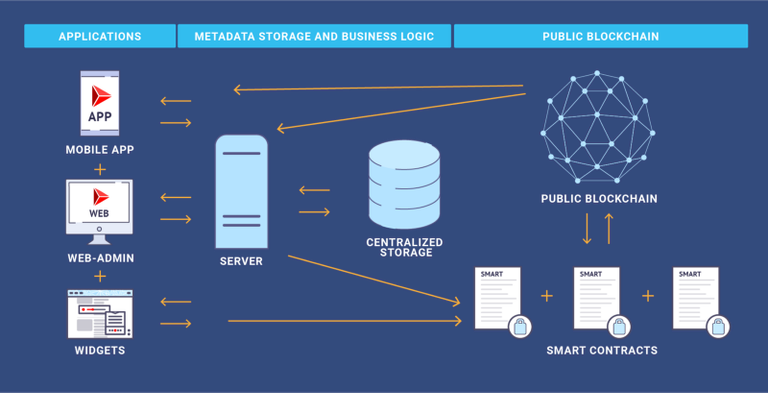
But maybe even more importantly it demands a very crucial shift in the way you think about your system and its components. From this point on you leave in a (partially) trustless world. Writing code for this world is hard; truly embracing the fact that you cannot trust parts of your own system is even harder.
Anyone who has dealt with web development knows that you do not trust the data that comes from your client. Because you never really know that it was “your” client that sent this particular request with this particular payload. But when building a partially decentralized solution, we also have to assume that we cannot trust “our” server. At least in all questions regarding value transference.
For me personally, the hardest thing to overcome was the necessity of shifting (or even duplicating) so much business logic to the client side. Since the client cannot trust the server, it has to be responsible for forming transactions, signing them and sending them to the blockchain. Since the server cannot trust the client, it has to have all these responsibilities too! Juggling signatures, permissions, smart-contracts invocations and direct blockchains interactions is a nightmare for any non-trivial scenario.
You also have to remember that smart-contract execution is extremely inefficient, blockchain resources are ludicrously expensive. Especially so when we are talking about public blockchains.
If you managed to navigate this hell then at this point you have a partially decentralized solution where you still hold a crucial central role. But at least all actions concerning value are transparent. However let’s be honest without metadata from your server, without media resources stored in your centralized storage, without milliard of centralized services your product is worthless. To quote Muad’Dib “The power to destroy a thing is the absolute control over it.” So. Let’s decentralize some more.
Additional food for thought
Further decentralization might not be necessary. Open source your code. Make sure that anyone can use your smart-contracts and you have a platform. Open sourcing is hardly a panacea, but it is definitely a step in the right direction.
An important thing to emphasize is that you will never be able to put all your data on the public blockchain. Anything private will demand a separate solution (zero-knowledge does not work for every scenario).
Another interesting fact is that real world right now is not prepared to work with DAOs and DACs. Your system will often need legal units in the different jurisdictions to remain compliant.
Step 3. Permissioned blockchains
I’ll be completely honest. We have not implemented this step for our system yet. But our current analysis strongly suggests that it is the right way to go. From what we see from IBM’s Hyperledger products (Fabric in particular) our analysis seems to coincide with corporate demands in this domain.
To decentralize business-logic level, we introduce permissioned blockchain to the system. To explain how it works lets walk-through a scenario of adding a new partner to our system. A new partner wants to represent our system in a new jurisdiction and add some new functionality to the system. To do that they need access to already existing metadata storage and services provided by other partners. In the trustless world, they also want to be a part of the infrastructure that validates the changes to the state of metadata. To do that this new partner adds nodes to the system which
- Are responsible for storing data in a way compliant with a given jurisdiction (GDPR or example).
- Are responsible for processing request from his applications.
- Take part in reaching the consesus as far as the global state of metadata goes.
This partner can then represent the system in all interaction with the traditional world, insulating traditional companies, government agencies, and in many ways end-users from complexities of the decentralized system.
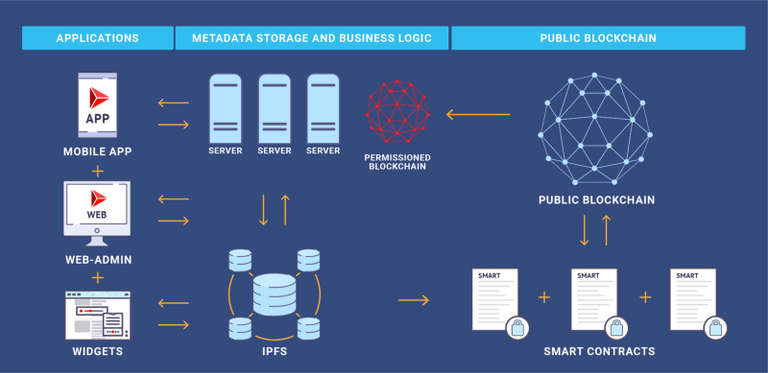
While this description seems way too vague, our current early prototypes show that this scenario can be implemented on top of Hyperledger Fabric. I plan to go into more detail in one of the future articles.
A system built this way can also solve the problem of storing media data, but I believe it goes against the Separation of Concerns principle.
Step 4. Distributed storage
Even if your project does not need a permissioned blockchain, it most probably will need storage for media files. This topic is vast and actively discussed, and I will just make a couple of important points here.
Contrary to any number of ICO whitepapers out there, just adding IPFS to the system does not solve your problem. At the very least you will have to address
- File storage guarantees. You have to guarantee that file won’t disappear from the system regardless of nodes being added and removed from the system.
- Incentives system. Your system will have to pay your “infrastructure providers.”
- Latency issues. Latency for distributed storages remains a huge issue.
Projects like Storj, FileCoins, Casper, Sia, and number of others are possible solutions. Or you can make something “in-house.”
Conclusion
In this article, we very briefly discussed steps of building a decentralized blockchain-based system. I strongly recommend a process of gradual decentralization for software systems. You should always start by creating a fully centralized prototype and use it to identify what should be decentralized. After that, you can step-by-step add public blockchain interactions, permissioned blockchains, and distributed storage to build a fully decentralized system.