перевод статьи Дэниела Ларимера. Оригинал на английском - https://hive.blog/fractally/@dan/fractally-s-groundbreaking-new-database-outperforms-lmbdx-eos-hive-chainbase-rocksdb
Децентрализация и масштабируемость идут рука об руку. Чем дешевле эксплуатация блокчейна, тем больше людей могут успешно его тиражировать и тем более децентрализованным он будет. Одна из основных проблем, с которой сталкиваются EOS и Hive, заключается в том, что они полагаются (или полагались) на базу данных в оперативной памяти, производительность которой резко падает, как только данные перестают помещаться в памяти. Это делает стоимость оперативной памяти EOS чрезвычайно высокой, а также принципиально ограничивает объем оперативной памяти, который может быть размещен на одном компьютере.
В конечном итоге Hive заменил chainbase (базу данных с привязкой к памяти) на бэкенд с более традиционной базой данных ключей/значений без sql (Rocks DB). Это позволило Hive масштабироваться для хранения большего объема данных за счет снижения пропускной способности транзакций.
Уникальные требования блокчейн к базам данных
Блокчейн - это база данных, которая может иметь несколько ожидающих завершения форков, и все транзакции применяются последовательно для детерминизма. Это означает, что база данных не может фиксировать данные до окончательного завершения и может быть вынуждена опираться на несколько частично подтвержденных состояний. В EOS, Hive и BitShares мы использовали "историю отмены", которая отслеживала изменения и позволяла нам быстро восстановить состояние блокчейна до более ранней версии, чтобы мы могли начать применять изменения для другого форка.
Такая модель доступа принципиально не подходит для транзакционной модели типичных встроенных no-sql баз данных, таких как RocksDB или LMDBX. Более того, даже если база данных поддерживает несколько вложенных друг в друга открытых "транзакций", мне еще не удалось найти такую, которая позволяла бы вам частично зафиксировать подтвержденную часть транзакции (новый завершенный блок), оставляя остальные (частично подтвержденные блоки) открытыми.
Более того, крайне сложно построить запросы, которые могут считывать состояние необратимого блока, позволяя при этом применять новые транзакции к вершине блокчейна. Обходные пути часто значительно снижают пропускную способность базы данных.
Методы, используемые традиционными базами данных для ускорения производительности записи с помощью многопоточности, приводят к недетерминизму и не подходят для блокчейн. Это значительно ограничивает производительность, которую можно извлечь из традиционных баз данных, и делает их эталоны записи и параллельного чтения неактуальными для понимания последовательной схемы доступа к производительности чтения-изменения-записи, требуемой всеми известными мне платформами смарт-контрактов (за исключением, возможно, блокчейнов на базе UTXO).
Однопоточное чтение
EOSIO и Hive могут поддерживать только однопоточное чтение через интерфейс RPC, поскольку базовые структуры данных не могут быть изменены во время чтения. Мы реализовали различные хаки в Hive, которые позволяли многопоточное чтение за счет ухудшения целостности и случайных сбоев в работе считывателей. Я не могу говорить о текущей структуре Hive, но я могу рассказать об опыте работы с RocksDB и LMDBX. Хотя они позволяют многопоточное чтение, накладные расходы на версионирование каждой записи в сочетании с другими ограничениями их конструкции означают, что общая пропускная способность значительно снижается.
Репликация состояния в традиционные базы данных
В block.one мы потратили много усилий, пытаясь найти лучший способ экспорта состояния блокчейна eosio в традиционную базу данных. Проблема, с которой мы столкнулись, заключалась в том, что было трудно поспевать за потоком данных, поступающих из EOS. Кроме того, нам приходилось ждать, пока блок станет окончательным, поскольку воспроизведение поведения переключения между форками во всем стеке было хрупким, сложным и снижало производительность.
Даже если бы мы смогли успешно и надежно реплицировать состояние базы данных в базу данных, поддерживающую горизонтальное масштабирование чтения, конечным результатом была бы централизованная система, и любые приложения, созданные на ее основе, могли бы быть закрыты, если бы каждый полный узел не реплицировал ту же сложную настройку.
Существует несколько сервисов, обеспечивающих индексацию цепочек EOSIO в режиме, близком к реальному времени, но их базы данных сложны и дороги в эксплуатации и не подходят для использования смарт-контрактами. Это ограничивает их полезность лишь поддержкой интерфейсов для приложений, подписанных на их API.
Время для нового подхода
Как только наша команда приступила к созданию собственного блокчейна для фракталли, я понял, что нам нужна технология базы данных, которая будет хорошо работать в оперативной памяти и плавно масштабироваться для обработки длинного хвоста данных, которые не помещаются в оперативной памяти. Она должна делать это, не вызывая чрезмерного износа SSD-накопителей, что в EOS может привести к тому, что SSD-накопители будут выходить из строя не через годы, а через месяцы.
В течение последнего месяца я кодировал пользовательскую базу данных, которая идеально подходит для приложений blockchain, и сегодня я собираюсь поделиться некоторыми из первых результатов. В одном из следующих постов я опишу дизайн, который позволил добиться таких результатов. Обратите внимание, что эталонные тесты не обязательно являются показателем производительности в реальных приложениях; однако они позволяют сравнить относительную производительность различных систем для рабочей нагрузки конкретного эталона.
Для этого теста я создал "наихудший случай" для базы данных, генерируя случайный 8-байтовый ключ и сохраняя 8-байтовое значение. Этот тест практически исключает возможность эффективного кэширования "горячих ключей/значений" в оперативной памяти и является хорошим показателем производительности в наихудшем случае. Когда дело доходит до доступа к длинному хвосту данных, к которым может захотеть обратиться блокчейн, практически гарантировано, что таких данных не будет в кэше.
Конкуренты (LMDBX и std::map)
В качестве точки сравнения я выбрал одну из самых высокорейтинговых баз данных, которую смог найти (LMDBX), потому что она поддерживала чтение прошлых состояний при продвижении вперед. Прошлый опыт работы с RocksDB и месяцы тестирования и оптимизации позволили мне понять, что она не будет служить нам достаточно хорошо. Некоторые реализации Ethereum используют LMDBX из-за его производительности по сравнению с Rocks.
Я также решил сравнить с хранилищем ключей/значений по умолчанию, присущим всему коду C++, std::map. std::map не является правильной "базой данных" и должен заботиться только о поддержании отсортированного дерева пар ключ/значение. У него нет других накладных расходов. Его производительность начинается с высокой, поскольку он находится в памяти, и в конечном итоге вынуждает операционную систему начать использовать виртуальную память для свопинга на диск. На данном этапе мы моделируем верхний предел chainbase, который использовался в Hive и используется в EOS. Chainbase имеет дополнительные накладные расходы и исторически всегда была медленнее, чем чистая std::map.
Прототип ƒractally базы данных представлен тремя отдельными линиями для сравнения однопоточной случайной записи с записью при чтении более ранних ревизий с 6 потоками параллельно.
Результаты
Все базы данных имеют два уровня производительности: один - пока все помещается в памяти, другой - когда ресурсы оперативной памяти исчерпаны и все начинает уходить на диск. Все тесты проводились на ноутбуке Apple M1 Max с 64 Гб оперативной памяти. Разница в точке дискового обрыва основана на решениях Mac OS о том, как управлять своим страничным кэшем в зависимости от модели доступа.
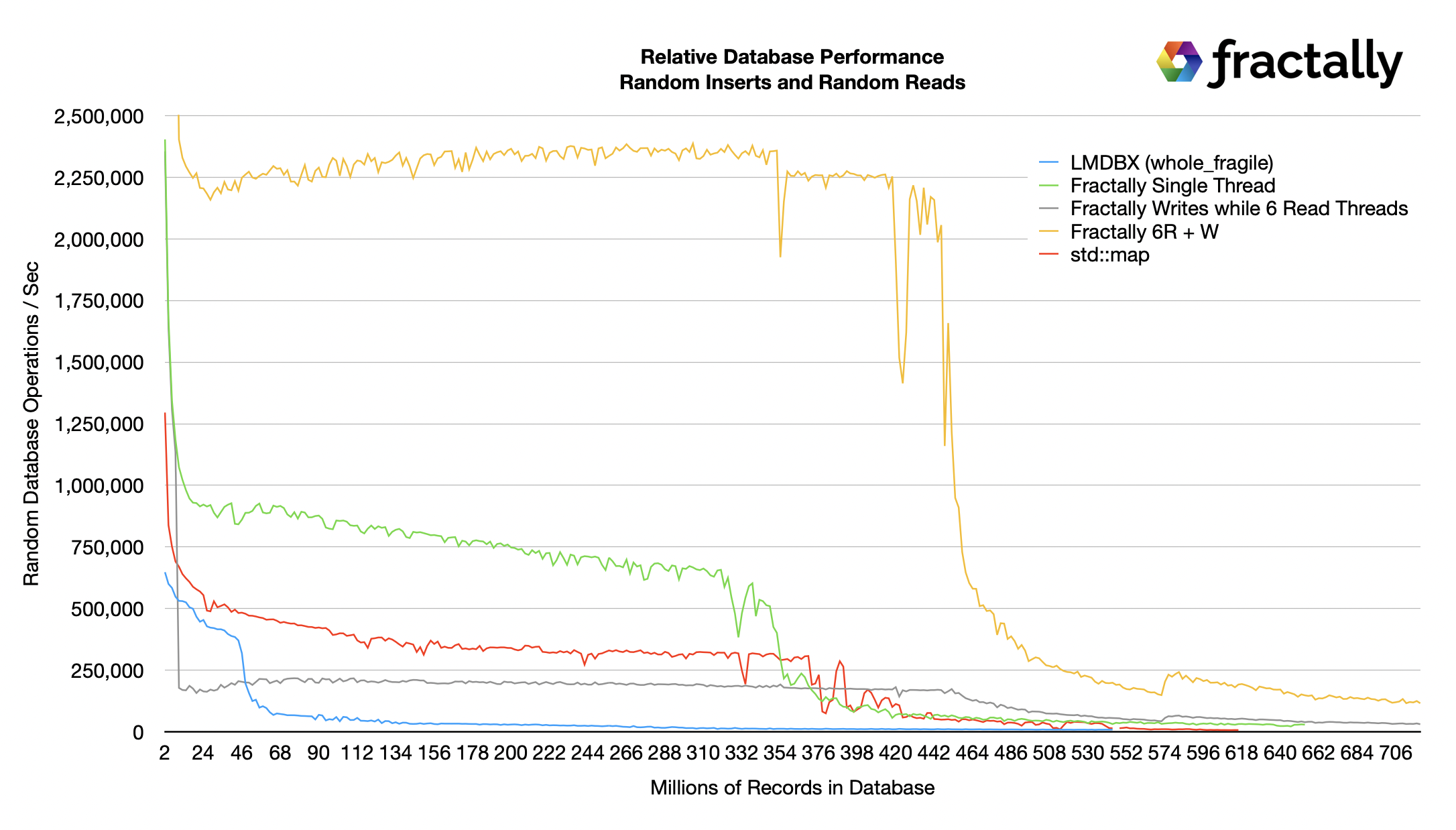
LMBDX отказался от хранения данных в оперативной памяти и быстро опустился до уровня производительности на диске, несмотря на то, что он был настроен на то, чтобы никогда не сбрасывать данные на диск, если ОС не требуется обмен страницами. Возможно, можно настроить некоторые параметры базы данных LMDBX для хранения большего количества данных в кэше оперативной памяти и замедления падения производительности, но это было бы спорным вопросом, учитывая, что даже на пике производительности он значительно отставал от всех остальных кандидатов.
Зеленая линия представляет собой сравнение однопоточной вставки моей новой базы данных с LMDBX и std::map. Как вы можете видеть, она более чем в 2 раза быстрее, чем LMDBX и std::map, пока все находится в оперативной памяти. Мы увеличим производительность на диске в одном из последующих графиков. Это означает, что она, вероятно, более чем в 2 раза быстрее, чем chainbase, используемая в eosio и hive.
Желтая линия представляет собой суммарную производительность при максимально быстрой записи в один поток и максимально быстром случайном чтении в 6 потоков. Более того, при случайном чтении считывается состояние за 4 "блока" до головного блока. Такая модель доступа невозможна с помощью std::map, которая не может быть прочитана и изменена одновременно, а LMDBX сделал такой доступ слишком сложным для реализации, и их документация предполагает, что он будет работать плохо. Поэтому любой блокчейн, построенный на LMDBX, будет нуждаться в высокоуровневой системе кэширования для поддержки ожидающих записей.
Одним из последствий наличия дополнительных случайных запросов является снижение пропускной способности при записи. Хорошо известно, что RocksDB не очень хорошо подходит для тяжелой смешанной нагрузки запросов и записей. Серая линия представляет операции записи, происходящие во время высокой нагрузки запросов.
Производительность диска
Поскольку производительность RAM и SSD различается на порядок, я решил рассмотреть производительность длинного хвоста, поскольку база данных больше не помещается в RAM. Первое, что можно заметить, это то, что LMDBX и std::map приближаются к одинаковой производительности. Я не смог запустить LMDBX достаточно долго, чтобы заполнить базу данных так же далеко, как в других тестах, потому что его производительность упала намного раньше.
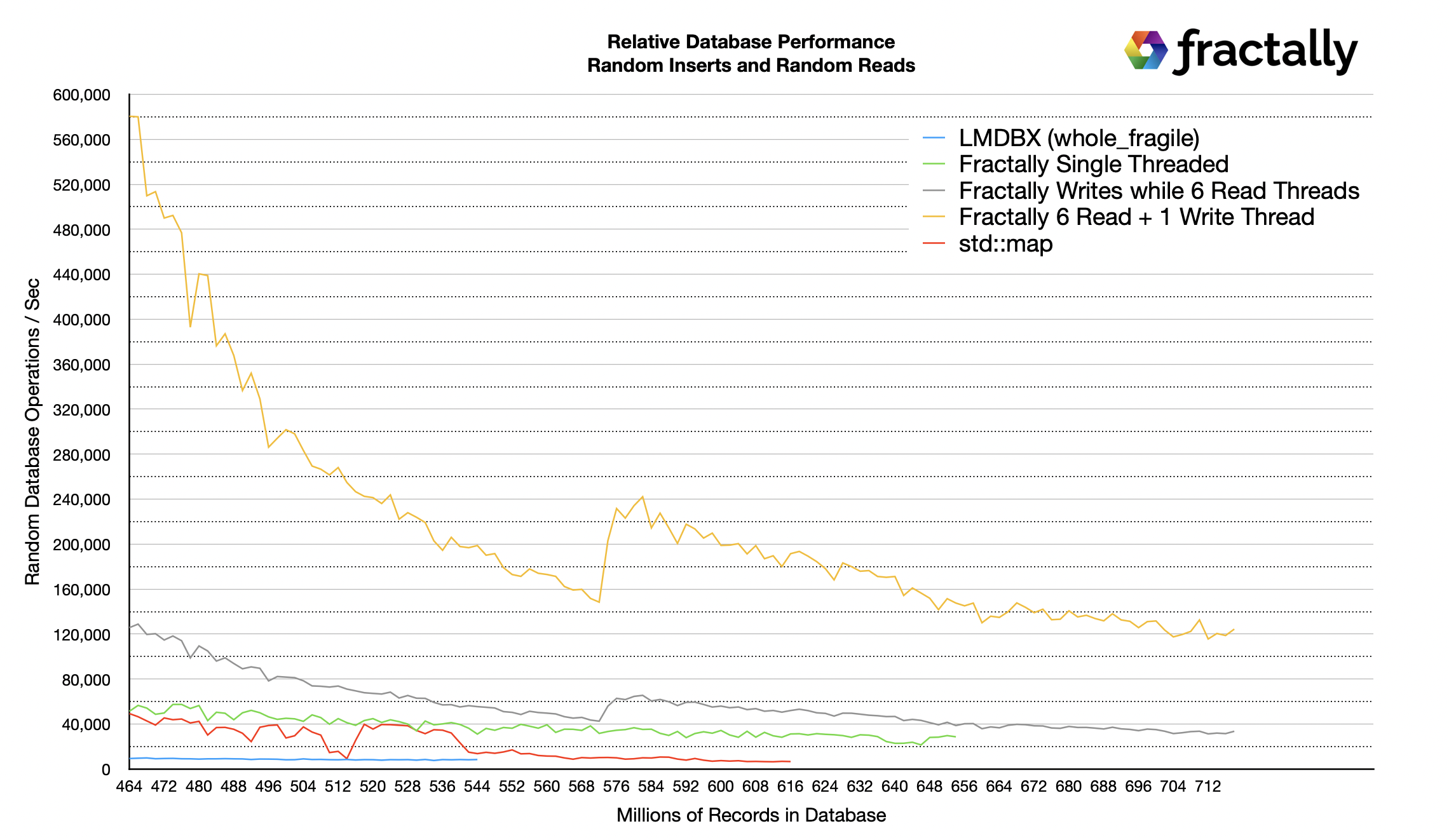
Следующее, что следует отметить, это то, что пропускная способность записи моей прототипной базы данных приближается к одинаковой долгосрочной скорости с потоками чтения и без них. Однако поддержка многопоточного чтения позволяет моей базе данных выдерживать более 120 000 операций в секунду при выполнении более 30 000 случайных вставок в секунду, пока состояние больше, чем оперативная память.
Наблюдение за активностью диска с помощью Mac OS X's Activity Monitor показало, что скорость чтения составляет 900 МБ/с в тесте многопоточного чтения и 300 МБ/с в тесте однопоточной записи. Что еще более важно для срока службы SSD, активность записи была в основном нулевой, только периодические всплески со скоростью 30 Мб/с или меньше. Эта активность записи была пропорциональна фактической скорости добавления новых данных в базу данных.
Аналогичные наблюдения за LMDBX показали активность чтения/записи 50/50, что привело бы к чрезмерному износу SSD.
Важность многопоточного чтения
Одна из проблем с доступом к состоянию блокчейна EOS непосредственно из nodeos заключается в том, что большая часть мощности процессора уже расходуется только на то, чтобы следить за изменениями состояния блокчейна. Более того, если вы хотите читать только "необратимое" или "окончательное" состояние, вам придется работать с узлом с задержкой, что снижает удобство работы.
Однопоточный доступ означает, что для обслуживания запросов на чтение доступно не более 50% мощности процессора, и API-сервисам пришлось бы развернуть большое количество дорогостоящих машин с большим объемом оперативной памяти, если бы они обслуживали запросы непосредственно с нод. Это настолько дорого, что никто из поставщиков API не идет по этому пути, и вместо этого данные экспортируются в более традиционную базу данных для запросов. Эти поставщики услуг становятся централизованными привратниками состояния блокчейна. Обратите внимание, что у Ethereum есть аналогичные проблемы.
Блокчейн на основе моей новой базы данных потенциально может обслуживать 10-кратное или более количество запросов в секунду из одного и того же состояния и будет ограничен только ядрами процессора и SSD IO. Производительность запросов может сделать дешевле простое копирование полных узлов, а не перемещение данных в более традиционные базы данных.
Более того, моя новая база данных позволяет выполнять длительное чтение тысяч различных корней состояний блоков без ущерба для производительности. Это позволяет делать снимки состояния в реальном времени.
Rocks DB против Griffin DB на Ethereum
В поисках лучшей технологии баз данных я наткнулся на исследование, использованное для оценки вариантов баз данных для Ethereum. В этом исследовании была показана производительность смешивания случайных вставок со случайным чтением уже существующих данных. Эта производительность чтения-изменения-записи критически важна для приложений блокчейна и дает представление о том, как работают другие базы данных.
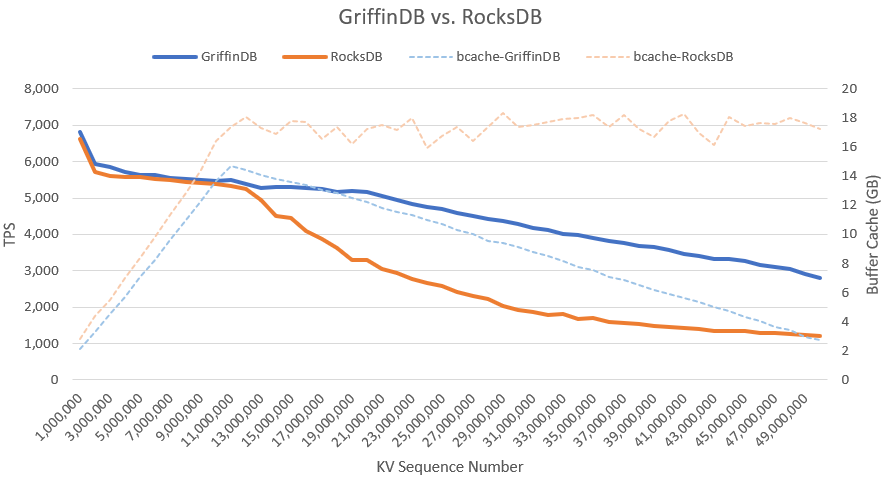
Я решил имитировать этот тест, создав имитацию криптовалюты с 25 миллионами имен учетных записей (взятых с Reddit) и выполнив трансфер путем чтения двух случайных балансов и уменьшения одного из них при увеличении другого, а затем записав изменения. В этом тесте я смог выдержать 570 000 пересылок в секунду, обратите внимание, что такой уровень производительности был достигнут благодаря тому, что все поместилось в оперативной памяти; тем не менее, он все равно впечатляет, поскольку значительно выше того, чего может достичь std::map на аналогичных данных в оперативной памяти. Примечание: этот тест учитывает только нагрузку на базу данных и не учитывает другие накладные расходы, связанные с блокчейном.
Выводы
Существующие структуры баз данных не очень хорошо подходят для требований блокчейн, и с этой новой структурой базы данных наш грядущий блокчейн для fractally.com должен иметь все возможности для создания более децентрализованной, масштабируемой, экономически эффективной и упрощенной инфраструктуры для развития будущего Web 3 и фрактального управления. В ближайшие месяцы мы откроем исходный код этой новой базы данных и расскажем больше о конструкции, которая делает ее возможной.
Отказ от ответственности
Обратите внимание, что все цифры основаны на ранних тестах, и реальные показатели могут отличаться. Существует множество уровней стека блокчейна, включая его виртуальную машину и библиотеки смарт-контрактов. Все эти вещи объединяются для преобразования "операций" базы данных в "транзакции" блокчейна. Для одной "передачи токена блокчейна" требуется как минимум два чтения и две последовательные записи. Опыт показывает, что производительность базы данных, как правило, становится узким местом, как только данные перестают помещаться в оперативной памяти.
Congratulations @shakhruz! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 200 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPSupport the HiveBuzz project. Vote for our proposal!
Подписывайтесь на мой телеграм паблик чтобы быть в курсе последних разработок в области ДАО и блокчейн технологий - https://t.me/ashirov_public