
Source
Dans le domaine de l’apprentissage automatique, nous devons organiser nos données afin de pouvoir réaliser différentes phases. En effet, lors de la réalisation de notre système, nous allons avoir deux grandes phases : une phase d’entraînement et une phase de validation. La phase d’entraînement va nous permettre de réaliser l’apprentissage de notre système. Puis, la phase de validation va nous permettre de vérifier cet apprentissage tout en vérifiant les performances de notre système.
Pour ce faire, nous allons devoir, dans un premier temps, organiser nos données. Ainsi, nous allons séparer nos données en trois catégories. Nous allons avoir nos données d’apprentissage (70~80 %), nos données de test (0~10 %) et nos données de validation (20 %). Nos données d’apprentissage et de test vont être utilisées durant la phase d’entraînement. Les données de test vont nous permettre de suivre l’évolution de l’apprentissage de notre système. Enfin, les données de validation vont être utilisées pour la phase de validation.
Évaluer notre classifier
Afin de pouvoir évaluer notre système, nous allons chercher à évaluer ces performances. Pour ce faire, deux notions clés existent. Il s’agit du rappel et de la précision.
Rappel
On définit la notion de rappel par le nombre de d’éléments trouvés dans une catégorie i par rapport au nombre d’éléments que possède la base de données dans cette même catégorie. Dans une écriture mathématique, nous aurons :

Ainsi, nous cherchons à savoir le taux de réussite sur l’ensemble des éléments de notre catégorie.
Précision
On définit par précision le nombre d’éléments trouvés dans une catégorie i par rapport au nombre d’éléments appartenant à cette même catégorie. Dans une écriture mathématique, nous aurons :

Nous cherchons ici, à savoir le taux de réussite de l’ensemble de nos prédictions sur une catégorie.
Illustration rappel/précision
Dans le cas d’une détection de maladie, il serait intéressant de récupérer toutes les personnes atteintes de la maladie, même si une personne n’est pas forcément atteinte par la maladie. En effet, cela permettrait, dans le cas d’une épidémie, de limiter sa propagation. Dans ce cas précis, c’est le score lié au rappel qui va nous intéresser le plus.
En revanche, dans la classification de courrier mail, et plus précisément dans la détection de spam, nous souhaiterons avoir un système qui pourrait laisser passer quelques spams de temps à autre. Cependant, nous n’aimerions pas qu’un mail important se retrouve dans notre liste de spams. Ainsi, dans ce cas de figure, nous allons privilégier le score lié à la précision.
Le score que nous allons privilégier dépendra de notre cas d’application. En effet, comme nous avons pu l’illustrer au-dessus, il se peut que, dans certains cas, nous souhaitions avoir une précision plus importante qu’un rappel, et inversement.
Donner un score avec la F-mesure
Lorsque nous cherchons à mesurer les performances de l’ensemble de notre système, nous aimons, généralement, avoir une seule valeur qui nous indique l’ensemble des performances de notre système. De ce fait, nous verrons souvent un taux appelé F-mesure. Cette mesure correspond à la moyenne harmonique de la précision et du rappel.
Ainsi, nous avons :
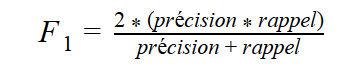
La formule, plus générale, utilise un réel positif β. Ce réel va nous permettre d’ajouter plus ou moins de poids en fonction de si on souhaite mettre plus d’influence sur la précision ou sur le rappel. De ce fait, nous allons avoir :
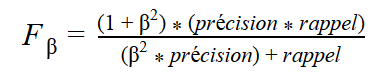
Étude de cas d’apprentissage
Nous allons maintenant nous intéresser à quelques études de score de différents systèmes. Ici, le pourcentage représente le score de notre modèle. Plus le pourcentage est élevé, plus le nombre de prédictions correctes est élevé. En revanche, si nous avons un pourcentage bas, cela signifie que nous avons un nombre de prédictions correctes qui est faible.
| Cas | Apprentissage | Validation |
|---|---|---|
| 1 | 95 % | 60 % |
| 2 | 89 % | 85 % |
| 3 | 20 % | 80 % |
Dans le cas numéro 1, nous avons un score dans la phase d’apprentissage très élevé. Cependant, durant la phase de validation, notre système a été mauvais. Cela se traduit par un effet de sur-apprentissage, notre système connaît par cœur nos données d’apprentissage. Ainsi, notre système ne sait pas comment interpréter les nouvelles données qu’il rencontre durant la phase de validation.
Dans le cas numéro 2, nous avons un système plutôt performant que ce soit durant la phase d’entraînement ou dans la phase de validation.
Dans le cas numéro 3, nous avons un problème avec nos données. En effet, nous pouvons nous rendre compte que la phase d’entraînement s’est mal déroulé pour notre système alors qu’il a plutôt bien réussi la phase dit de validation. Il faut donc réorganiser nos échantillons de données.
Conclusion
Au cours de cet article, nous avons vu comment séparer nos données en deux bases. Une base d’entraînement permettant l’apprentissage et une base de validation permettant de vérifier que l’apprentissage s’est bien passé. Nous avons aussi vu les notions de rappel et de précision qui seront à prendre en compte en fonction de notre cas d’application. Enfin, nous avons vu la F-mesure qui nous permet d’avoir un aperçu du score de notre système.
Ce post a été supporté par notre initiative de curation francophone @fr-stars.
Rendez-vous sur notre serveur Discord pour plus d'informations
This post has been voted on by the SteemSTEM curation team and voting trail in collaboration with @curie.
If you appreciate the work we are doing then consider voting both projects for witness by selecting stem.witness and curie!
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!