Yeah, that is probably doable. I plan to publish my methodology once I figure it out, and it should apply regardless of the language, though it will be simple.
- Is the comment unique? Ie, does it appear multiple times? + Score if unique, - score if it is not unique, and the less unique it is (ie, the more frequently it occurs, the more negative it gets)
- Is it longer than the average comment on the chain? (and a modifier for good the longer it is)
- How many "tokens" does it have - basically, how many words? You can have a reaaaaalllly long comment (as the length of the comment is counted in characters) but it might have markdown formatting, lots of links, or html in it that extends its length beyond the meaningful comment
- I'm not sure if it will be possible to do analysis row by row, but there is the Readability Tests (Flesch Kincaid) which is something built into Word and other writing tools to make stuff easy to understand: https://en.wikipedia.org/wiki/Flesch%E2%80%93Kincaid_readability_tests
- If it isn't easy to understand, or written at a very high level, it might be seen to have good academic qualities.
There's a whole bunch of other things you can with natural language processing and data to extract insights. I am really looking forward to who swears most on the blockchain :P
Or maybe, we could find out what the most frequently mentioned colour is? blue, red, green, yellow, orange, purple, brown, or something else? :D
As an appendix to this comment, Microsoft Word tells me my grade level for this comment is...
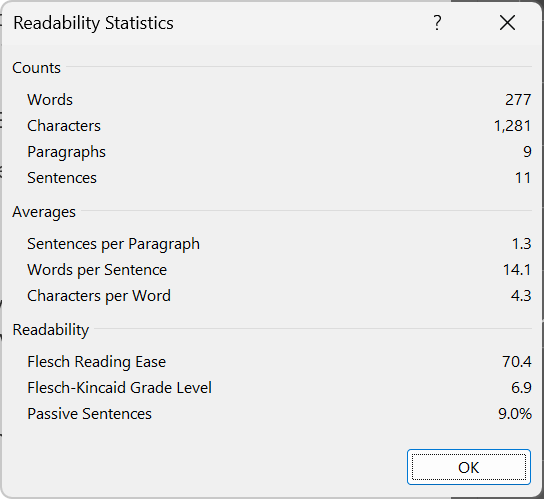
I like to try and keep things mostly simple on HIVE, as not everyone has English as a first language.
I’m really looking forward to a post where you break down the process a bit more. I’m still kind of new to programming and data stuff, but I pick things up pretty fast, and this kind of analysis is super interesting to me.
Also, I was thinking — have you ever considered using ChatGPT or the GPT API to help analyze comments? Not sure what your take on it is, but I’ve used it a lot to help me understand topics that I’ve always struggled with. I just tell it to explain things like I’m five, and honestly, it helps a lot.
Obviously it’s not a replacement for real thinking or research, but as a tool, it can be surprisingly useful.
There's a lot of stuff that pre-dates LLM analytics which is pretty good for text. The whole area of NLP (Natural Language Processing) is probably very foundational to the existence of LLMs like GPT.
I have an idea that I can run a local model to identify some trends on the comments. That is a longer term goal. The problem with doing such analysis is that there's a random seed generated each time you ask a LLM a question, so each time, you'll get a slightly different answer.
As a result, you can't really run tests with different data over different time periods and expect it to treat the analytical process in exactly the same manner, even if you're using the same prompt in the same session, with a different data set.
There's a few commercially available models that focus on repeatable, more empirical analysis, I trialed a few at my old job, but there's a lot of stuff you can do to exhaust the data before you get to "AI" giving you new insights or new paths to go down.
I plan to exercise all those traditional methods before I dive headlong into whatever stuff I can cook up for a LLM to do these data sets.
It will be able to, at a guess - that would be more difficult in traditional NLP methods, if not normally possible:
I am not formally qualified in any of this data science or data reporting stuff. I've just worked with it for years at my old job, and hope to find a new job (I was made redundant about 6 weeks ago) where I can use these skills to make people do things with more integrity, ethics, respect, or.... worst case, y'know capitalism, cos a man like me loves pizza.