
After @pharesim wrote a post about our Hive Discover project, many readers reacted with privacy concerns and complained that you can't copy recommendation systems like Meta and Google operate 1 to 1 into Web3. The message was clear: the privacy of the users must now be in the spotlight!
There is no denying that recommendation systems are important for social media to be successful. So far, HIVE lacks such a system and especially new members complain about the limited possibilities to find content or to be found themselves. That is one of the reasons why we have been working on this project for a long time.
With this new update, we think that the transformation of recommendation systems into Web3 has been successfully initiated. Now all data that can infer the interests of a user are securely encrypted with RSA! The next step would actually only be a decentralized storage and processing...
How this works in detail will now be explained:
How is a device registered?
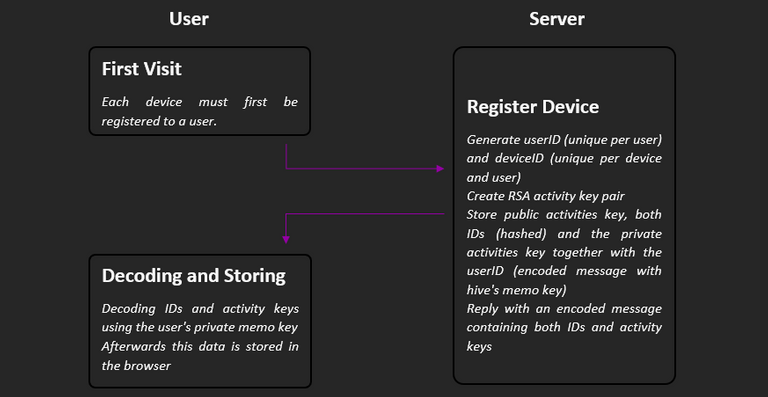
Whenever a user wants to log in to a device for the first time, they must register it. To do this, a request with the username and device name is sent to the server. The server then generates a deviceID and checks whether a userID already exists. If so, the remaining data is loaded from memory and sent back to the user.
If this is the user's first login, the userID and an RSA key pair (activity key) are generated. The public activity key, userID (hashed) and deviceID (hashed) are stored together. In addition, the private activity key and the userID are stored in an encoded message (Receiver: User; Permission: Memo) so that it does not have to be recreated at the next time the user logs on.
The device then receives a response with the two IDs and activity keys, which then only must be decoded and stored.
How is it verified at the backend that a specific user is logged in?
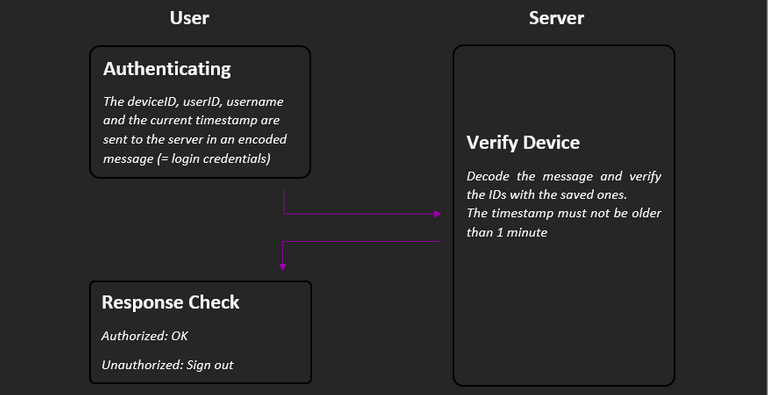
As soon as the page is reloaded or the stored data in the browser changes, it is checked whether the credentials are still correct. For this purpose, the deviceID, userID and the current timestamp are combined in a message, which is encoded by the user and decoded by the server. The timestamp must not be older than 1 minute when the server performs the verification. In addition, the IDs sent are compared with those stored for the user.
The response returned only tells whether the credentials are correct or not, after which the browser responds if necessary.
How are activities stored?
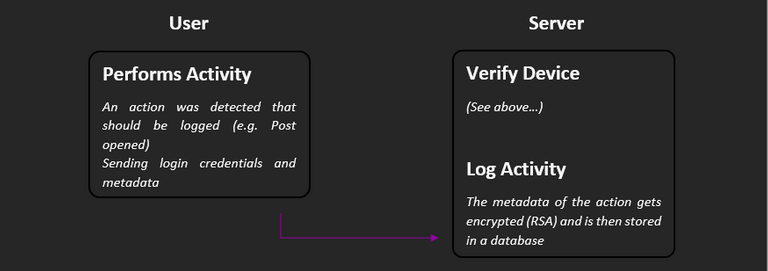
When users perform an action that allows inferences about the interest in a post, it is stored. For this purpose, the appropriate metadata is sent to the server together with the login credentials. Metadata includes, for example, the author, permlink, type, timestamp and other useful information.
At the server, it is then first verified that it is the user it claims to be. Then the metadata is encrypted with the user's public activity key and stored in a database. Now only the user can decide when the metadata should be decrypted again. In this state, no one else (including us) can do anything with them. In addition, all activities are stored once again anonymously to make analyses practicable at all.
How can users see their activities?
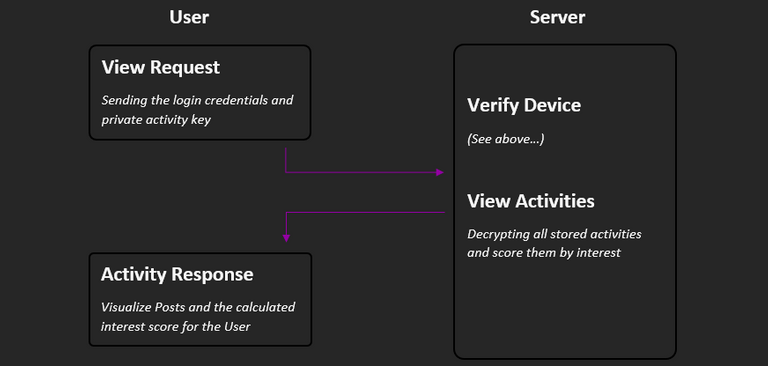
In order for users to get a feeling for the basis from which the recommended content is calculated, they can get an interest overview. To do this, a request must be sent to the server, which contains the login credentials and the private activity key. If the verification is successful, all stored activities will be decrypted with the private key, summarized and scored. The ratings are then available as percentages that indicate how interesting the particular post was for the user.
Note: Since the rating is based on global / post-related and user-related average values, the percentages can only be interpreted as above / below average interest. A value of 50% therefore stands exactly for average interest. Higher values mean above-average interest and lower values signify below-average interest. On the other hand, the results are still vague, especially at the beginning, and change very quickly if the user / post has few activities.
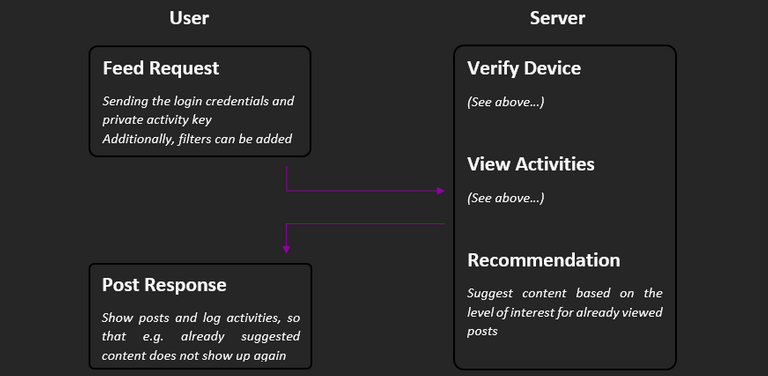
How can users have content suggested to them?
Next, we come to the part why the steps before all exist in the first place: the user wants to have content suggested to him. For this, the login credentials and the private activity key must first be sent to the server. Additionally, filters can be defined, such as tag lists, communities and languages. The user is then verified at the server, the activities are decrypted and ranked. On this basis, content is then selected that the user might also like.
Conclusion
Through these mechanisms, your activities can be stored securely without fear that they will be sold or abused. If you find a vulnerability, please let me know as soon as possible. Even if we worked on it for a long time, bugs can't be excluded. But as long as no one finds a way to decrypt the metadata without the user knowing, we call it safe. The entire source code of Hive Discover is publicly available at https://github.com/hive-discover
I am interested in this project – how can I contribute or help?
Anyone interested is invited to collaborate on the Hive Discover project. It doesn't matter if you are a programmer, designer or just interested, because everyone can and should help. Especially we are currently looking for people in the following domains:
- Categorization volunteers: Together with @pharesim the idea came up to train an AI to categorize posts. This could be particularly exciting in the marketing analysis of posts, because authors could then address the interests of their readers. However, for the results to be meaningful, we would need a good data set. Both of us are not able to do this on our own and therefore call for your help: Help us to categorize and benefit from the results soon! Here you can find out how you can help.
- Frontend-Developers: At the moment @christopher2002 is developing the backend, but he also has to develop the frontend. If you want to work on a frontend for Hive Discover, please contact us! Currently we are working with Nextjs, but we are open for any modern web technology.
Feel free to contact us if you have other skills that you think could help Hive Discover!
Please keep in mind that Hive Discover is still a prototype and latency may be quite long when data is requested. However, this can be improved significantly with already planned optimizations and better servers.
Have a nice day!