This article will assume that you've read the previous one. There might not be too many references to it, but since the topic will revolve around the same parts of code, it is safe to assume there will be some.
Some things changed since last article, f.e. is_producing() is no more. It was replaced with set of transaction status flags that give much more detailed information on how current transaction is processed. Also the problem with write queue congestion, that I was so sure needs addressing, turned out to be nonexistent. Only when node is stuck in processing very large block with slow transactions, incoming transactions might accumulate in the queue, but unless the network is already on the verge of collapsing (with block offsets crossing 2.5s and more), by the time new block is to be processed, the write queue is already empty or near empty.
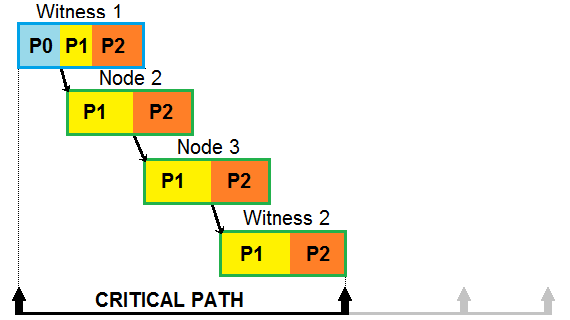
What changed the most is the optimizations that were applied to the process described in previous article. They all revolve around shortening critical path and reducing unnecessary work.
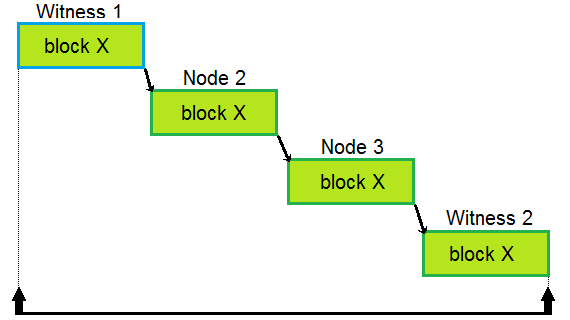
The same block being processed and passed further by different nodes. Note that whole path needs to be crossed before next witness can start producing block.
It is ok to be lazy - skip work on pending transactions.
There are two important changes there. Expired transactions are no longer processed like we didn't knew they expired. Since it is way cheaper to make a check outside the main code (and I mean waaay cheaper; in one test where I had over 100k pending transactions that all expired in the same time, original code could drop less than 5k of them per block, after changes all 100k+ were dropped easily within the same timeframe).
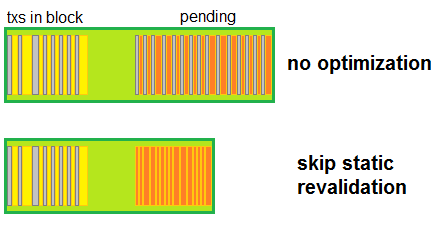
Second change was to stop revalidation of operations and signatures while processing pending transactions. Transactions have two types of checks - static, that don't depend on state of the node (transaction invariants) which are composed of calling validate() on all component operations - and dynamic, performed by evaluators, that (mostly) depend on state (there are some that don't really depend on state but are still performed as dynamic, because they were introduced in some hardfork). It is easy to see that checks that don't depend on state don't need to be performed multiple times with each reapplication of transaction.
The omitting of signature validation is more controversial. Even if transaction was validated in that regard, by the time the transaction becomes part of the block, other incoming blocks might include different transaction that changes account keys, making the original transaction invalid. Previously that situation would be detected during reapplication of pending transactions and such transaction would be dropped. Since the situation is extremely rare, as long as we make sure block producer performs all the checks, there is no need to validate signatures every time on every node. The node only broadcasts validated transactions once, the first time it processes them, and that's when all the checks are performed. The second time it broadcasts transactions is when they become part of newly produced block, applies to active witnesses only (in that case all checks are performed as well). The only drawback of not validating signatures with every reapplication is that in the rare case mentioned above, affected transaction will last on the node until it expires. In the light of next optimization that one might turn out not to be necessary.
Transaction invariants calculated once.
That optimization was actually the last one implemented in experimental code, but due to conflicts with other work other changes had to be postponed, so it was introduced first. It revolves around transaction invariants in more explicit way. Remember how in previous paragraph I said that all checks were still performed when new block is produced? Well, since new blocks are made solely out of pending transactions, and the node has done static validation on them already, it makes no sense to do it again. Moreover, while witness has to verify signatures, the calculations leading to it, namely extraction of public keys from signatures, is also an invariant (actually it depends on chain id, which changed in HF24, but in this case it doesn't make a difference anymore). Incidentally it is also a costly process, so it pays to only perform it once. There are some other pieces of data that are also invariant (f.e. transaction id) but they don't take enough time to recalculate to make it obvious that we want to actually use RAM to keep them precalculated (they are now stored, but that might change if it turns out the data takes too much space).
The optimization made it so transaction invariants are calculated once and used whenever needed later. Not just the invariants but transactions themselves are shared, that is, when new transaction arrives (be it as standalone from API/P2P or as part of block) it is first checked if the node knows it already. If it does, it means all the work for the transaction, as long as it does not depend on state, was already done and does not need to be repeated. That includes transaction size (easy to check if it can fit into the half filled block), binary version of transaction (ready to be stored in block), public keys (ready to be tested against required authorities).
If it is not yet obvious how it helps in shortening critical path, imagine this. Between arrivals of consecutive blocks (once per 3 seconds) nodes are busy validating and exchanging transactions. That work is outside of critical path. Now it is time to produce a block and node has to be working fast. Yey, all the static validation is already done, all the time consuming calculations of signatures are also done, block production was never that easy (there is one more thing there that can still be improved, but that is to be described another time).
Ok, so block producer can focus on reapplying selected pending transactions and putting them inside block (as mentioned, binary form is also ready). What about blocks coming from P2P? Very similar situation. Statistically such block will consist of transactions that the node has already seen before. That means most if not all work involving invariants of such transactions is also already done.
But that is not all. Since invariants don't depend on state, it also means they are independent of each other. That means they can be worked on in parallel. No longer is the power of the node limited by its single core performance. The more cores the merrier.
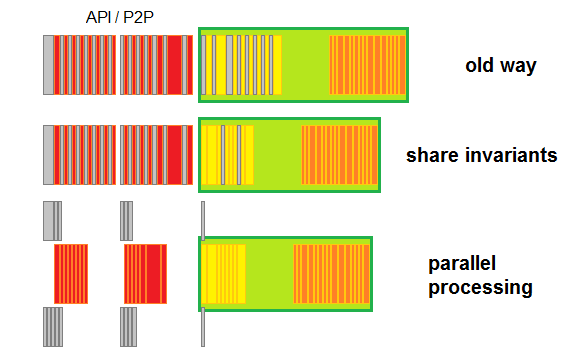
Note how last version has a lot more free time to react on API calls or add even more transactions.
That optimization is especially powerful in case of transactions that have operations that are easy to apply, because then time spent on invariants is the biggest chunk of overall work on them. There is one particular operation that takes almost no time to apply. Yes, you guessed it, custom_json_operation (only custom_operation is shorter because node doesn't even need to check if it has some custom evaluator for it). And what do we have swarming the chain in time of high traffic? Bingo, custom_jsons.
Custom_jsons also gained the most from one more optimization - replacement of JSON parser. The old one was slow and a bit buggy. Normally it would not be possible to replace it and keep it in part of code that is independent of state. That is because old parser allowed some non-JSONs to be included in the chain. If replaced, the new one would start rejecting transactions from old blocks - not good. Such replacement would need to be done on hardfork check and that means in evaluation code which is dependent on state - also not good, because it would slow down replay and could not benefit from invariant optimization described earlier. Clever trick was applied. New parser performs quick check first. If it accepts, it is all good and fast. Only if the check on new parser fails, code falls back to ask old one (which might accept or not). The difference in speed between parsers is so big, that it is not really noticable slowdown for rejecting invalid JSONs, but several times faster acceptance of correct ones.
Trust the block you've produced.
When block producer creates a block, the work can be split into three phases. Phase 0 - actual production of block: reverting to clean state ("the present" - see previous article), preparing header, applying and packing transactions, finally signing the block and reverting back to clean state after block is ready. Phase 1 - reapplying the produced block. As I said in previous article it is to avoid potential differences in code execution when transaction is applied as part of block production and when it is applied as part of incoming block. That is very important aspect, but not the full picture. When block is applied, the code not just applies its transactions, but also does all the work related to automatic processing of existing state (which is not done during block production). Finally phase 2 - reapplication of pending transactions (going back to "the future" which also removes all the transactions included in the block from the list of pending).
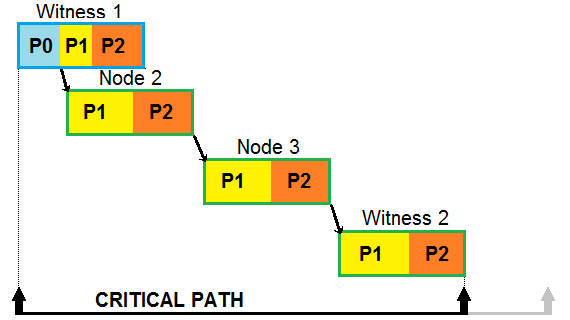
Ok, so let's assume we are the witness node. We've just finished phase 0 and are about to start phase 1. We know the block is good, why not share it with other nodes? There are two problems, but strictly technical. We need to perform all the work anyway before we can free the writer thread - that is one - and the code that was producing block has no access to the functionality used to broadcast the block. For the second problem, instead of passing pure parameters of new block, witness thread grants writer thread part of its power in form of special control object - witness_generate_block_flow_control. It contains functionality needed to perform broadcast. Now the writer thread can just use it right after phase 0, right? Not so fast. When done this way at times P2P communication was fast enough that other peers managed to ask for the block before it was stored in fork db, where P2P expect it to be. It means we need to do the broadcast not at the end of phase 0, but at the start of phase 1, when the block is put into fork db. Ok, since witness thread is blocked until writer thread frees it, can we free it at the time of broadcast, so it can happily get ready to prepare request for another block? Again, not so fast. If done this way at times the witness thread would pick up work fast enough (while still in its production window) to notice the block that was just produced is not in the state yet. It would then request to produce the same block again. Ok, so we have to at least wait until end of phase 1 to free the witness thread. Even when the witness is freed to do its thing, writer thread has to continue until end of phase 2. Only then it can pick up another item from its queue.
Since block production is at the start of critical path, the optimization helps shortening block offsets on all nodes that receive the block. The difference the optimization makes grows with the size of block.
Share the success as soon as possible.
That optimization can spread its wings the most when there is enough pending transactions to fill up limitted 200ms reapplication window. That is the most it can give - 200ms. However since there can be many hops between nodes, those gains add up. In a "proper" configuration witness nodes are not exposed to the outside world, but stay behind "bastion" nodes that usually also act as API nodes. It means that witness nodes are (at least) three hops away from each other (witness1 -> bastion1 -> [zero or more nodes ->] bastion2 -> witness2). The reapplication window fills up during high traffic, meaning the optimization works best when it is needed the most.
When block arrives via P2P the node processes it in two phases: application of the block and reapplication of pending transactions. These are the same as phase 1 and 2 respectively from previous chapter. Once phase 1 ends the node knows the block is ok, so it can share the good news with other nodes without waiting for phase 2 to finish. Just like in case of production of new block we have to borrow a bit of external power, from P2P this time, in form of p2p_block_flow_control. It allows writer thread to free P2P task early, while it continues work on phase 2. P2P thread can in the same time broadcast the block to its peers.
Gather data while you are at it.
One of the side effects of having block_flow_control objects passed through all the major interfaces is the ability to gather extra data. Normally if you wanted to see how much time was spent on each phase, or how many transactions were processed etc., you'd need to dig through the logs and know what to look for. Now there is a way to generate report for each block. The report can be configured (in range of data it contains and where it is generated) but the full version looks like the following example (taken from flood test with 128kB blocks):
{"num":156,"lib":155,"type":"p2p","id":"0000009cb2d92b112c2b6fa4d403e80ef26e37d7","ts":"2022-05-30T16:30:45","bp":"witness17","txs":320,"size":130977,"offset":-108448,"before":{"inc":2298,"ok":2298,"auth":0,"rc":0},"after":{"exp":0,"fail":0,"appl":5016,"post":86340},"exec":{"offset":-137790,"pre":1327,"work":28015,"post":206657,"all":235999}}
As you can see, it is a JSON. To keep it compact, the names of the fields are short, so it can be challenging to see what each value means at first. Let's decrypt it:
{
"num":156, // block number
"lib":155, // last irreversible block
"type":"p2p", // type of block_flow_control used with the block
"id":"0000009cb2d92b112c2b6fa4d403e80ef26e37d7", // block id
"ts":"2022-05-30T16:30:45", // official timestamp of the block
"bp":"witness17", // witness that signed the block
"txs":320, // number of transactions contained in the block
"size":130977, // size of block in bytes (uncompressed)
"offset":-108448, // offset from block timestamp (in microseconds) when the block was considered valid
"before":{ // info on transactions that came to the node between this and previous block
"inc":2298, //number of all incoming transactions (API+P2P)
"ok":2298, //number of those accepted as valid
"auth":0, //number of failed due to authorization
"rc":0 //number of failed due to lack of RC mana
},
"after":{ //info on pending transactions that are reapplied during phase 2
"exp":0, //number of expired
"fail":0, //number of failed (for other reasons than expiration)
"appl":5016, //number of reapplied
"post":86340 //number of postponed
},
"exec":{ // execution times (in microseconds)
"offset":-137790, // offset from block timestamp when block was placed in the writer queue
"pre":1327, // how long block had to wait in writer queue before work started
"work":28015, // time of actual work before the block was considered ready to be passed further
"post":206657, // time spend on further phase(s) after main work was done
"all":235999 // overall time spent by writer thread processing the block
}
}
Some more remarks:
lib- last irreversible block is so close to current block because OBI is already active.type- it can begenfor blocks generated by this node, orp2pfor blocks coming from other nodes. It can also besyncwhen generated during massive P2P sync (but then automatic reports are turned off because their printing does not carry much usefull information while slowing down the process),oldfor tests mainly, but alsoforkwhen fork was switched during processing (timings can be inflated a lot),ignoredwhen the block was from inactive fork (timings will be extra short) orbrokenwhen block was invalid.offset- the first thing to look for when considering state of the network. When the value is negative or close to zero it means blocks are passed smoothly and the node has plenty of time to process new transactions or respond to API calls. When the value grows to near 3 seconds or more, the network starts to choke and fork a lot due to not being able to process blocks in timely manner. It won't break, but it might become really unresponsive and the actual throughput drops dramatically. By the way, all above optimizations made it so even 2MB blocks (hardcoded maximum limit allowed for witnesses to vote on) can be safely processed way within time limit. The best part is that transactions that were most problematic before optimizations (could potentially be used in DDoS attack on HIVE if witnesses allowed blocks bigger than minimal) are now trivial and no longer a threat.before.auth- HF26 introduces (slightly) new way of packing transactions that contain assets, which influences signatures. Since API calls pass transactions as JSONs, there is no way to know if the signatures follow old or new serialization. New is preferred, so the node will assume new at first, and only if it fails, it will try the old one. That means transactions that are signed the old way will show up as failed (and will also inflate the number of incoming transactions since both tries are actually completely different transactions from the perspective of the code, even with different ids). The number can be used to estimate how many active users use not updated wallets (at some point the old way will become deprecated and users will be forced to update - we can measure the impact of such decision with this stat).before.rc- transactions that fail due to lack of RC are especially problematic, because a lot of the execution cost was already spent anyway (RC has to be calculated after transaction is applied). This stat allows us to see how frequently that happens to possibly trigger allocation of manpower to do something about it (some things, like payer, are actually transaction invariants, so they could be calculated in a bit smarter way). Also during transition period between nodes with HF25 code and new ones with HF26 there will be disagreement between them about RC costs, so the stat can be temporarlily inflated.after.exp- some transactions have short expiration times, so they are more susceptible to fall here, also during time of high traffic (and small blocks like they are now) the disparity between blockchain throughput and P2P capacity to feed node with new transactions is so great, that it takes looong time for transactions to wait in the pending list - they might not make it to the block before expiration. This stat counts such cases.after.fail- since different nodes can have slighly different view on order of transactions, as a result they can disagree which ones are valid. It means that what node considered valid in its local order might no longer be valid in order imposed by the witness that produced block (f.e. ifalicesends some funds tobobandcarol, but she only has enough for one of the transfers). Such cases should be rare - they are counted by this stat.after.appl- the purpose of phase 2 is to reapply pending transactions. This stat counts those that made it within 200 ms limit (note that optimizations greatly increased that number), which brings me the the next stat...after.post- sometimes there are just too many pending transactions. Those that didn't fit the time limit are simply rewritten to pending without checking. Because of that, whatever influence they might have on the state, it is not expressed (f.e.alicewill show her balance unchanged, even though her transfer was already accepted to pending). There is nothing that can be done about it except witnesses allowing bigger blocks, because it happens when node continuously receives more valid transactions than can fit inside the blocks. We've done flood testing with small blocks on mirrornet and the number of pending can reach 500k. It does not grow indefinitely only because the oldest pending will start to expire (and as I mentioned earlier handling of expired is super fast now).exec.offset- similar tooffsetbut from the other end of the work. This is when the work was prepared to start. If you could see the stats from the node that sent you the block, you'd see that there is, sometimes very noticeable, gap between itsoffsetandexec.offseton your node. It is because P2P has to pass inventory, decide which items are needed, send out requests and process them, finally the block message has to be pushed through the network. It all takes time, and after all P2P is not only working on the blocks alone. Even though the blocks take priority, if there are some prior tasks scheduled, then they are executed in between. Currently this is the main source of "instability" in the offset measurements, because there are times when all is done right away, other times there is an accumulation of delays (of course it happens more in high traffic). There is potential for improvement, however the offsets now are so small no one will probably bother to mess with the P2P code.exec.pre- waiting in the queue. As mentioned earlier I thought this is where we could see frequent delay, but in practice the numbers here are always neglegible.exec.work- it means different work depending ontype. Forgenit is phase 0 (and a tiny bit of phase 1), forp2pit is phase 1, forsyncit is also phase 1 (but it is all there is),forkwill contain all the time needed to apply blocks during fork switch (and then there will be extra transactions that were popped from former main fork),ignoredon the other hand is just putting the block to fork db without any work on it, finallybrokenwill depend on when the block was found to be invalid. Overall it is the time that had to be spent before block status became known (and could be shared with other nodes in ok case)exec.post- like above it greatly depends ontype, but in all cases it is the "cleanup" work that needs to be done by writer thread in the background after main work (in most cases it includes but is not necessarily limited to reapplication of pending transactions).exec.all- how much in total the writer thread spent processing the block. When writer works with block, it cannot work on new incoming transactions, most API calls are also blocked during that time.
Next time I think I'm going to speculate on what we can still do in the future :o)
Maybe it would be a good idea to tag plugin custom_jsons which need to be parsed by hived or hive core middleware differently from third party custom_jsons which don't (with potentially lower RC cost for the latter)?
They are tagged differently. In current version only
delegate_rc_operation(withrctag) carries extra cost. All other custom_jsons are only charged base cost, no matter if they are those used by essential services like Hivemind or third party. (By "current" I mean HF26 version :o) )I think we're talking past each other here. Currently all custom_jsons have to be parsed because they might be used by a hived or hivemind. What I'm suggesting is that custom_json be broken out into one kind that is parsed by core services, and another that can be used by third parties but is not parsed by hived or hivemind. The latter would presumably have lower CPU usage (almost none beyond the base to parse an op at all) and therefore could have lower RC cost.
I mean the latter doesn't even have to be json at all. It could be custom_text. We do have custom_binary (I guess this has lower cost, or it should), but people seem to prefer storing json/text rather than packing a binary.
No, hived only checks if
jsonfield of custom_json is a valid UTF-8 JSON string. It does not build variant object out of that string in order to access its fields. To see if it might need to actually do that, it usesidfield that is right there in the operation itself.Moreover the execution time associated with it being custom_json is trivial in comparison with cost associated with the transaction. Validation, execution and RC handling of custom_json (yes, cost of calculating RC is also included in the cost of operations) all together take 1509 ns on average. On the other hand duplicate check, tapos check and charging for RC takes 6622 ns plus a whooping 94165 ns per signature. Transaction itself also costs some state (128 byte-hours) and history bytes (size of transaction). As you can see, even if we started to charge zero for execution of
custom_json_operation, the difference wouldn't matter.If you are thinking about looking for a way to speed up calculation of public keys from signatures (most obvious target when it comes to execution time), it would help all transactions and would be very welcome, however most of the cost of transactions with custom_jsons comes from history bytes, not execution time.
The timings are obviously constants - they don't depend on the hardware the node is run on, because otherwise nodes would constantly disagree on RC mana of users. They were collected by @gtg on average computer recommended for witnesses - see issue #205. They are likely to be updated (lowered) with future hardforks as more powerful hardware is required to run witness node.
Thank you. Pointing out that any processing of the content isn't significant is a good reason further optimization doesn't appear to be needed. Good explanation.
~~~ embed:1556399886530224131 twitter metadata:UG93ZXJHYW1lczh8fGh0dHBzOi8vdHdpdHRlci5jb20vUG93ZXJHYW1lczgvc3RhdHVzLzE1NTYzOTk4ODY1MzAyMjQxMzF8 ~~~
The rewards earned on this comment will go directly to the people( @hivetrending, @urun ) sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
Congratulations @andablackwidow! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 600 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!
Congratulations @andablackwidow! Your post has been a top performer on the Hive blockchain and you have been rewarded with the following badge:
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!
$WINE
Congratulations, @theguruasia You Successfully Shared 0.200 WINEX With @andablackwidow.
You Earned 0.200 WINEX As Curation Reward.
You Utilized 2/4 Successful Calls.
Contact Us : WINEX Token Discord Channel
WINEX Current Market Price : 0.168
Swap Your Hive <=> Swap.Hive With Industry Lowest Fee (0.1%) : Click This Link
Read Latest Updates Or Contact Us
Ok, as far I understand,
everything becomes lighter because transactions need to be calculated once and can't be changed after.
That's cool.
JSON. become more expensive? or did I misunderstand?