One of the first things tasks we took on with the development of the Hive blockchain code was to setup an automatic build-and-test system. In this post, I wanted to quickly describe that work, and it’s current status. Before I detail that work, let me start by explaining what and why it’s good to have an automated build-and-test system.
Why use an automated build-and-test system (AKA continuous integration, AKA CI)?
With an automated-build-and-test system, whenever a programmer makes a change to a program’s source code and submits it to the code repository, his change is compiled, then tested against a set of standard tests. This is a very important improvement to the development process, as it makes it easier to detect when a code change has a negative impact.
Without an automatic build-and-test system, a bunch of changes can be made to the code before a bug is detected, in which case programmers have to spend a lot of time figuring out which change caused the problem.
Note that there’s several ways in which a code change can have a negative impact: build errors, bugs, and decreased performance.
Automated builds to detect compile errors
In the simplest case of a negative impact, a change causes the code to no longer compile (build). This particular problem is relatively easy to detect even without an automated build system since no one will be able to work until the compile error is fixed.
But it is much better for compile errors to be detected soon enough to notify the programmer who introduced the compile bug, instead of leaving it to other programmers to discover that they can no longer build the code. In a project with many programmers, this can waste a lot of time, as each programmer has to do their own separate build to discover there’s a problem, then they needs to either figure out what the problem is, or wait for the programmer who broke the build to fix it.
With an automated build system, the programmer will be notified that his commit broke the build process within an hour or less of when he makes his commit (the notification time depends on how long it takes to do a build and how much computing resources are available to the automated build system).
One more note about the need for automated building systems: it might seem like programmers would never commit code with a build error, because they should always build it on their local computer, before committing it to the code repository. But this overlooks one common problem: the user’s local computer may have an environmental difference of some sort that allows the code to compile on their computer, but not on other computers. Several things can cause this: environment variables, differences in installed libraries and software, and operating system differences.
Operating system differences are particularly problematic: often a program is supposed to work on different operating systems such as Linux, Windows, and Mac OS, but a programmer normally works on one computer running a specific operating system and he doesn’t generally have a computer running each supported operating system. For this reason, any software that is supposed to run on multiple operating systems should pretty much always require that the development process include an automated build system.
Automated tests to detect bugs
An automated build-and-test system discovers bugs in newly commited code by running a series of tests on the code. The more tests that are available, the more likely that the automatic system can detect a bug, and the more likely that it can precisely identify the nature of the bug.
When a programmer is making a change to the code, he usually focuses on testing based on the exact reason he made the code change. For example, if he’s adding a new feature to the code, he will spend most of his time just testing that new feature. But more often than we would like, a change that seems like it should only affect one thing can have unexpected impacts on other existing features in the code.
This is why it’s important to build up a large set of tests that test the entire system, so that programmers don’t spend days manually testing everything the software can do (which is generally too hard to do anyways, as no single programmer will know how everything is supposed to behave on a large software project).
Automated tests to detect performance slowdowns
In addition to making sure the software is giving the correct answers, tests can also be used to measure how fast the software is computing those answers. Often, you can just keep track of how long your tests take to run, in order to detect a performance slowdown (or a speedup).
An automated test system really excels at detecting performance changes, because it maintains a history of previous test runs, so a simple visual inspection of old and new test times will reveal performance problems or performance improvements. When performance is of especial concern, extra tools can be added to make an automatic comparison between old and new test times and report the data in an easily understandable format.
Ok, but what about Hive’s automated build-and-test system?
The initial focus was to simply get the automated build system operational. The basic build system includes a set of “unit tests” in the core C++ code that verify basic operations in the blockchain code.
But the unit tests don’t test the blockchain functionality needed by Hive-based applications (e.g. hive.blog, peakd.com, splinterlands, etc). To fill this gap, we’ve also created a large set of tests written in Python that check all the API calls used by these applications.
Speeding up the build-and-test cycle
Until recently, a full build-and-test cycle took about 53 minutes on the public repo. During earlier development, we were working on a private repo with an extremely fast server, where the full cycle took 27 minutes. In the past few days, all our devs have made the move over to the public repo, as we’ve completed the initial Hive rebranding work, and so it seemed like a good time to begin optimizing the build-and-test time there.
As of today, we’ve reworked the process to where a full build-and-test run takes only 16.5 minutes on average. We did this by enabling the build-and-test process to be distributed across several computers at once. It can now simultaneously build three different versions of the hived code (consensus node, testnet node, and fat node). We also split up the various tests into multiple groups called “jobs”, so that they can be run in parallel as well, once the testnet node is built. There’s also a new “package” step which is done at the end of the build process that makes docker images for easy deployment to other computers. Here’s what the new build-and-test process looks like in terms of dependencies of each job in the overall "pipeline" process:
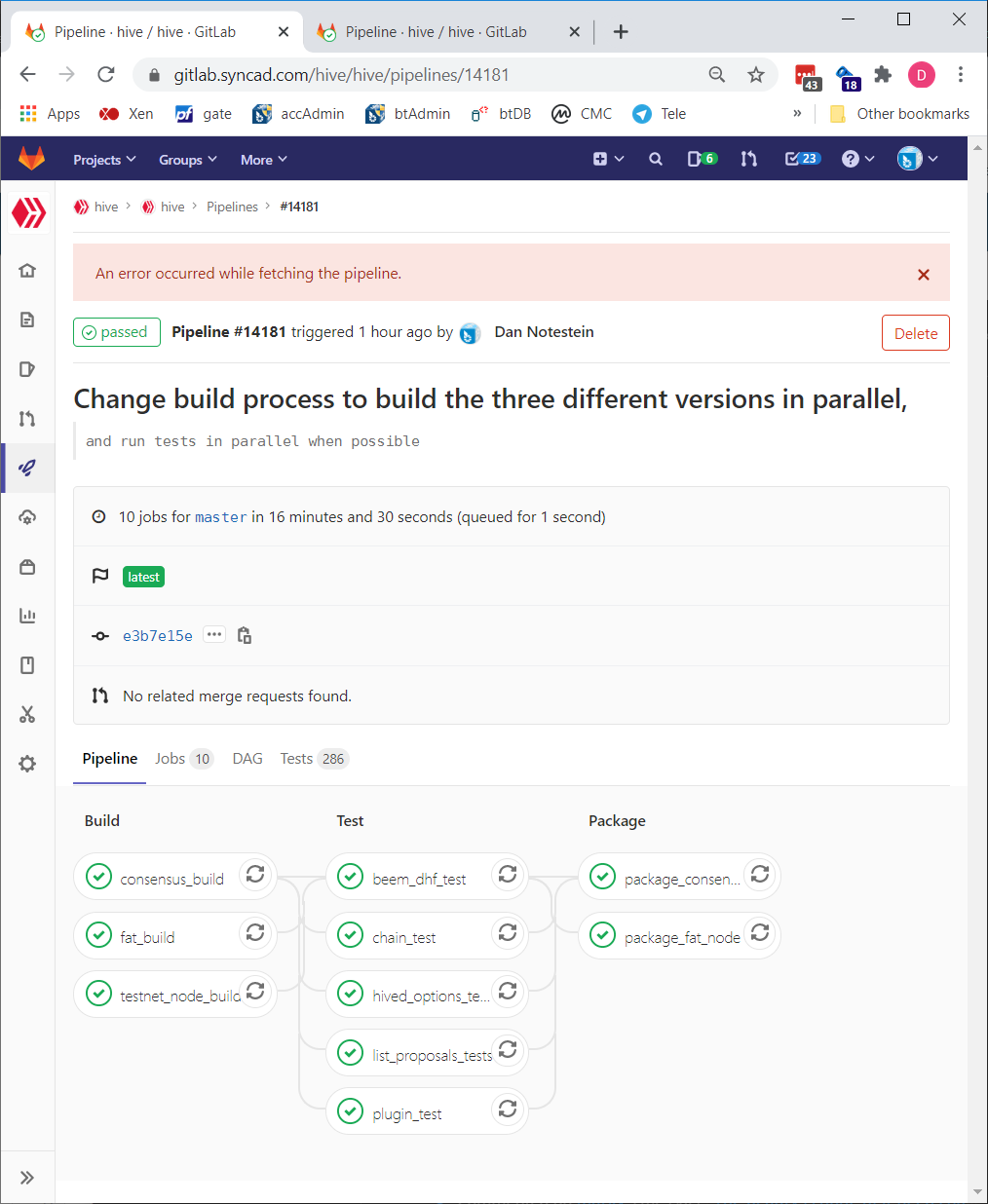
https://gitlab.syncad.com/hive/hive/pipelines/14181
And here you can see the times of the individual jobs in a build-and-test run:
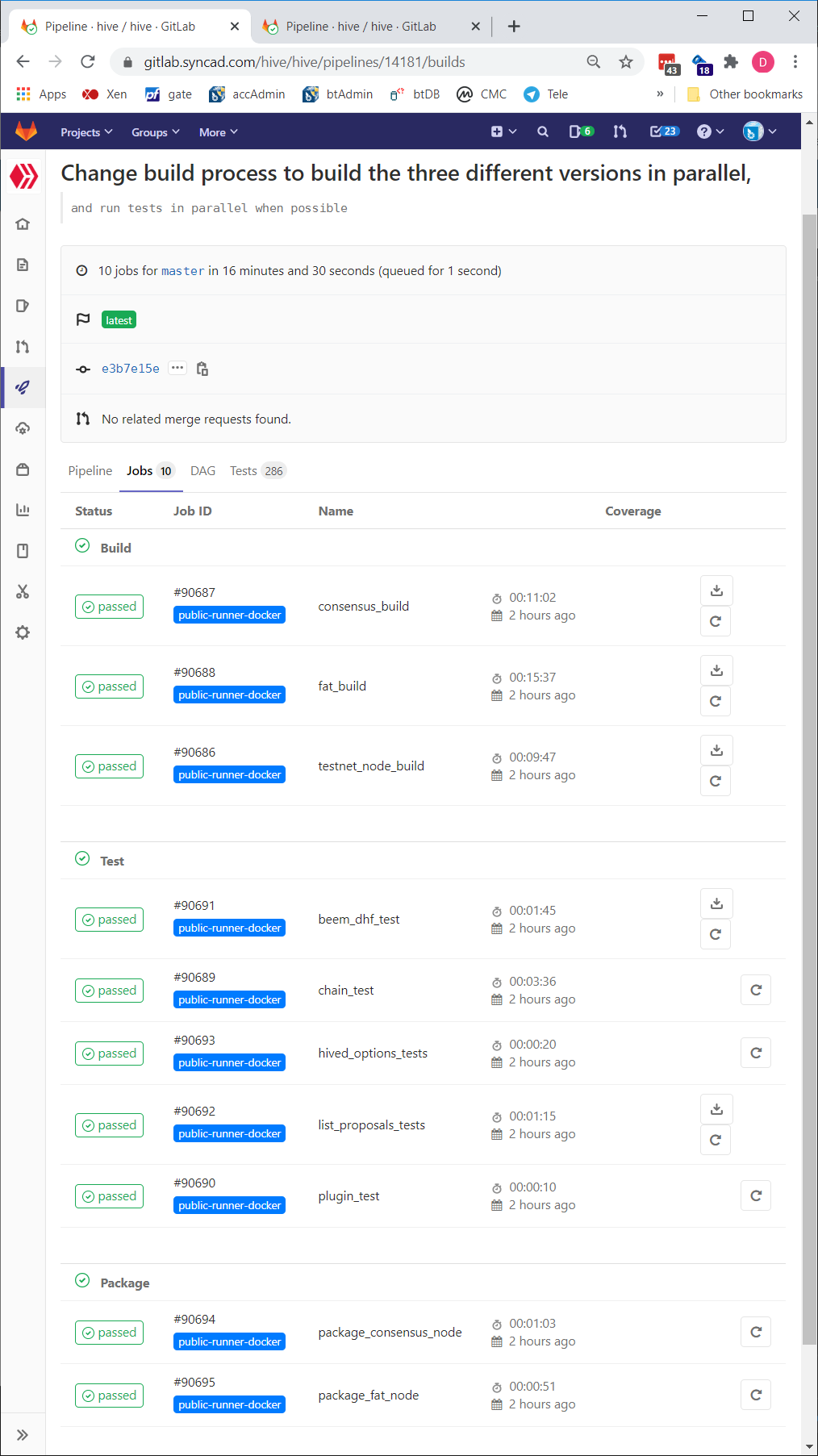
https://gitlab.syncad.com/hive/hive/pipelines/14181/builds
Once we made the build more parallel, we added another server to our build farm, so that all three compiles can be done simultaneously (previously we only had two build servers in the farm). In the image above, you can see that the entire build-and-test cycle only took 16m30s, even though the build of just the fat node took 15m37s. This is the power of a parallel build process that allows us to cut the time down from a sequentila build time of 50+ minutes.
Better test reporting
In addition to speeding up the build-and-test process, a side benefit of separating the tests from the build jobs is that our gitlab repository now give us nice reports about how long each step takes (how long it takes to build each node, how long each set of tests takes to complete) and shows detailed reports about what tests passed or failed in a test group. Below are screenshots of the test reporting:
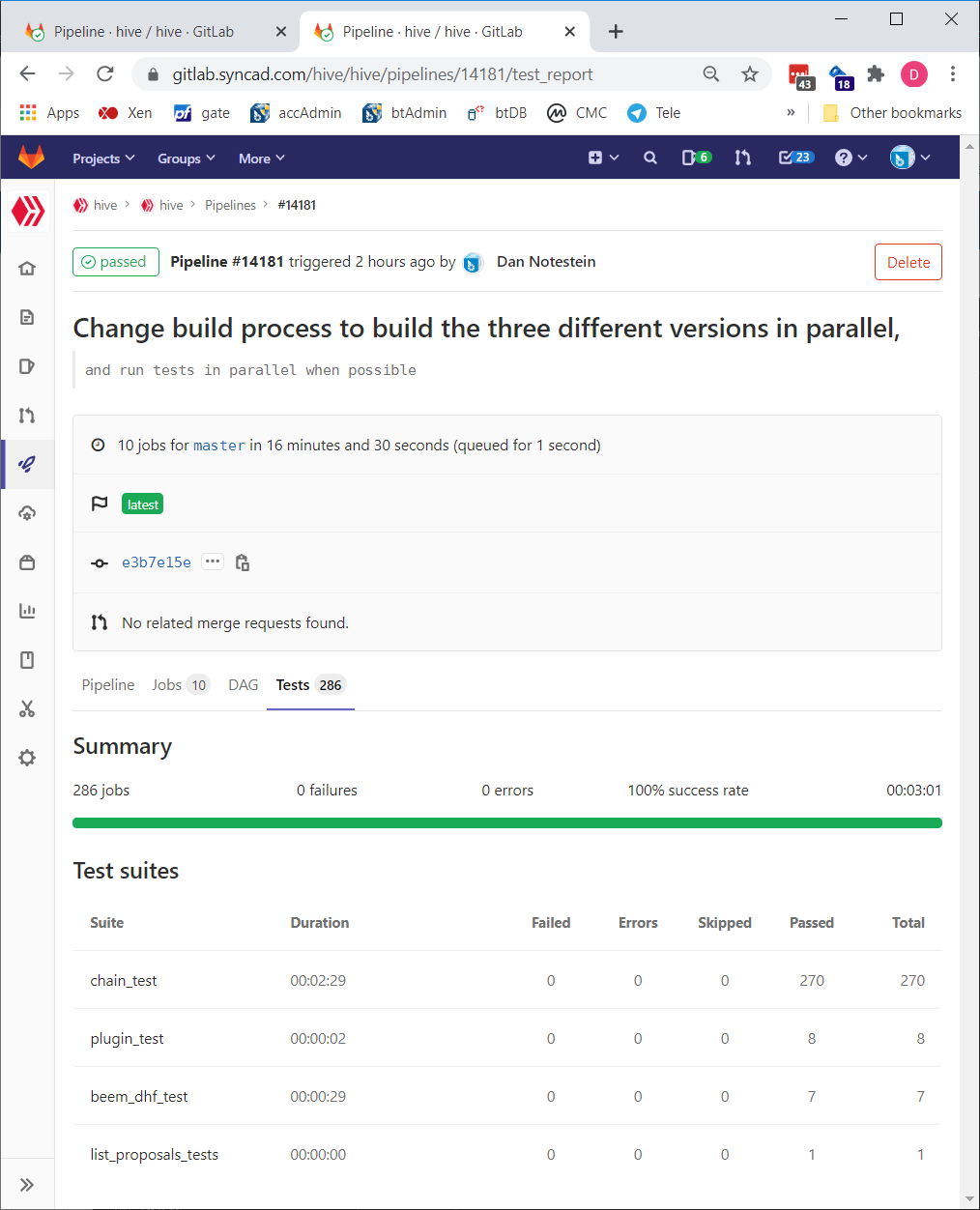
https://gitlab.syncad.com/hive/hive/pipelines/14181/test_report
What’s next? An automated build-and-test system is never done
At this point, our current automated build-and-test system is working extremely well, and it already saves us a lot of time, so I don’t expect many more fundamental changes at the moment, except for creating new tests for functionality and performance.
One new type of test we’re looking at adding to the system is a “state comparison” test. These tests are made possible by a new feature in the eclipse release that allows saving and restoring blockchain state information. This feature was primarily developed to allow exchanges and other node operators to get a new node running quickly(in the past this could take days, now it can be done in an hour or so). But we can also use this feature to compare state information files generated by hived before and after code changes. This will allow us to detect many types of bugs that are difficult to detect using existing test methods.
Adding still more performance tests is probably our highest remaining priority for the build-and-test system. We’re currently finishing up tests to measure reindexing time (reindexing time is how long it takes a new node to process all the existing blocks in the blockchain).
Because reindexing is a time-intensive testing (requiring several hours), we’ll make it an optional test. But we can also use the new state information feature to allow testing at any particular set of blocks in the blockchain, so we can isolate the reindexing test to a specific set of blocks of interest, or even make the overall reindexing test parallel by running multiple reindexing tests at different block ranges simultaneously, then verifying that the resulting state information still matches the old results at the ending block of each sub test.
blockchain code/hf24 update next please?
Coming soon. I have posts partly written, just waiting for some final numbers on the new Eclipse code after performance tests are completed.
Thank you Dan! :D
A huge hug 🤗 and a little bit of !BEER 🍻 from @amico!
Un caro abbraccio 🤗 e un po' di BEER 🍻 da @amico!
I can't agree with you any less
Very valid!
Congratulations @blocktrades! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
You can view your badges on your board And compare to others on the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Do not miss the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!
The best write for reading
Im sure in due time you will complete all those that are required for a smooth sailing overall operation, good job!
Valuable information. I'm sure they'll do a good job. Go ahead.
A good technology publication is always satisfying to read. Very good work with construction and test cycles! It is essential to have them in order to optimize projects with many or few programmers working on them.
I hope this automated buid-and-test solution for hive's core blockchain code will work perfectly well to suit its purpose. Thanks for the update.