If You want to write a Hive application based on The HAF, then You must know the SQL interface for the blockchain data defined by The Hive Fork Manger - one of the framework components, You must at least once read its documentation.
If You don't know what is The Hive Application Framework please read "What is HAF"
Where is the Hive Fork Manager documentation ?
The documentation is on GitLab, in the same folder where the sources are: haf/src/hive_fork_manager. The component is a part of a more general project 'HAF', which provides utilities to help build and deploy Postgres extensions and modules. If You are a software developer interested in the development of The Hive Fork Manager then You should look at:
- HAF documentation
- description of functional tests HAF/tests/integration/functional/hive_fork_manager
The rest of the post is about the document haf/src/hive_fork_manager
For whom the documentation is ?
Hive Fork Manager documentation has a few goals:
- help programmers to write HAF based applications
- help administrators to install Hive Fork Manager in a Postgres cluster
- help programmers to develop Hive Fork Manager
Based on the above, the documentation is targeted at software developers and administrators who are interested in The HAF deployment.
The plan of documentation
The main Hive Fork Manager (HFM) documentation file begins with a brief description of what HFM is.
Installation
Probably this section will be the most frequently read because it describes how to install HFM on the Postgres database. Administrators and programmers will read it to set up this crucial part of The HAF. Important notice here, I observe that everyone who installs the HFM first time, forgets to read the important section about the authorization and his first start of The HAF usually fails because of a lack of permissions.
Architecture
Here are described fundaments of The Hive Fork Manager. This part of the document explains how the internals of the HFM work and how the applications and hived should use the component's interfaces.
Overview of the fork manager and its interactions with applications and hived
Most important picture - componets diagram
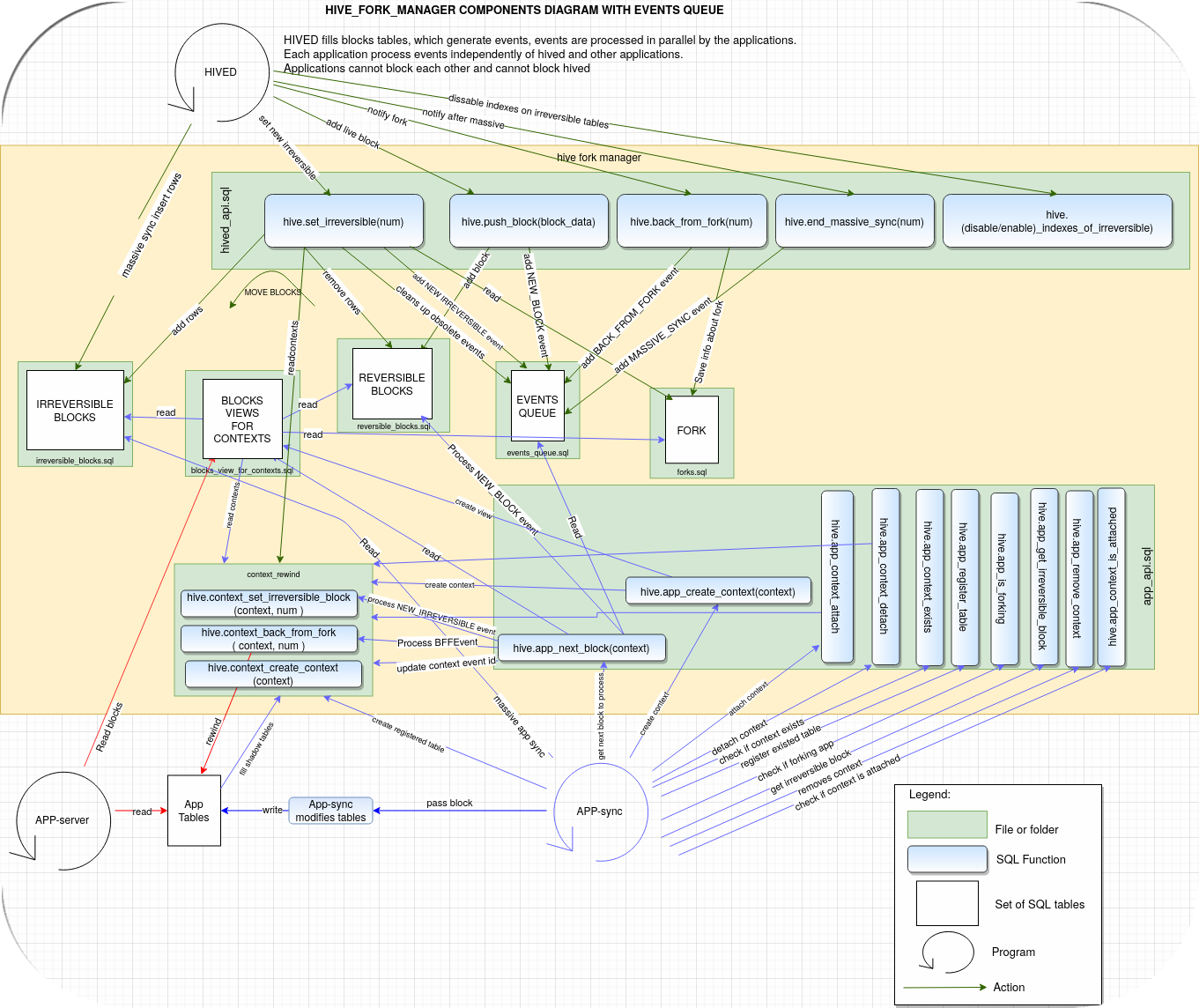
The picture above contains all the functionalities and components included in the Hive Fork Manager. How to use it ? Arrows are described with a function that is executed by the anchor site's component on a component on the arrow side. Components represent files, folders, SQL functions, and tables in the project source directory.
How to use component diagram- an example
We want to understand what exactly happens when hived notice HFM about micro-fork occurrence: At the bottom is a part of the picture which describe desire functionality:
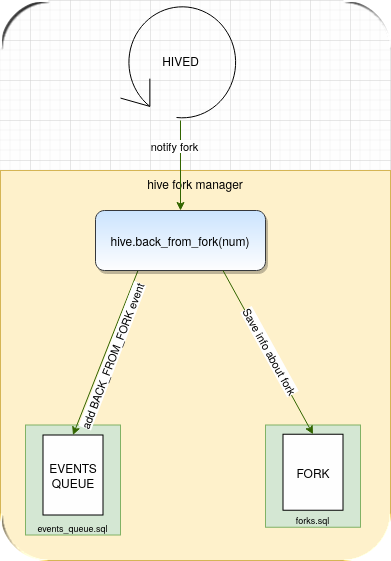
1. we found the hived on the top of the picture
2. now we found the 'notify fork' action described on one of an arrow anchored to the hived component
3. we see that hived calls hive.back\_from\_fork function, which we can find in hived\_api.sql file
4. hive.back\_from\_fork adds BACK_FROM_FORK event to EVENTS QUEUE which is defined in events\_queue.sql file
5. hive.back\_from\_fork adds information about a fork to a hive.fork defined in the file forks.sql
A similar procedure can be repeated with any interaction started by hived or by the application.
Hived and the application algorithm
The next sections present definitions of algorithms that must be implemented by hived and the applications to cooperate with the Hive Fork Manager. HFM is only a Postgres extension - a set of SQL functions and tables. Unlike programming languages, SQL does not provide efficient mechanisms to express its modules logic to clients, so instead of using the language syntax, documentation must be delivered that describes how to use them. The algorithms present the only valid ways to use HFM by its clients.
Important implementation details
It is worth understanding some details about the project because they may have an impact on the whole HAF node and particular applications' performance. There are descriptions of some non-trivial algorithms hidden behind the SQL API functions, the reader gets knowledge about blockchain data splitting for reversible and irreversible parts and about traversing events queue by the applications.
CONTEXT REWIND
Context rewind is a part of the Hive Fork Manager which is responsible for rewind applications data during the micro-fork occurrence. It was designed and implemented first, at the beginning of the project. During its testing, it was proved that rewinding of the changes of any SQL table is possible and is fast enough to allow it to be used by the applications which demand high performance. The context rewind is a closed, internal part of the system, defines API which is used by the rest of the HFM.
Database structure
Here is the database schema - tables created by the Hive Fork Manager and their dependencies.
SQL API
Descriptions of all SQL functions which are parts of the HFM API.
Known problems
Here is the place where are described problems which we known, but it is clear that they won't be solved. There is one such problem:: the Hive Fork Manager cannot support the applications tables which contain Foreign Keys not deferrable - these constraints cannot be evaluated at the moment of committing a transaction, which is required by the micro-fork rewind algorithm.
Other architectures which were abandoned
Here is the answer to why today the Hive Fork Manager looks like it looks. There were a few attempts with different approaches to implementing the HFM, all of them are described in this section. It may be important to the developers to know the problems presented here, to do not back to previously compromised solutions.
That's all about the Hife Fork Manager documentation. I hope this post will help You during starting working with HFM.
So do dapp developers need to become familiar with how HAF handles micro-forks in order to develop their dapp?
No, it is hidden behind HFM API. It is important to know the algorithm which a dapp needs to implement, and understand that application can work with reversible blocks (micro-fork can abandon such blocks), but it is possible to works only with irreversible blocks. But of course, it would be good to know what happens in the guts of HFM when some blocks become abandoned - it is a good topic for the next post, I think.
Congratulations @mickiewicz! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
Your next target is to reach 1000 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
@lemony-cricket Check this out.