Cordiales Saludos
Ya hemos dado los primeros pasos para la generación (creación) de datos para hacer nuestros primeros ejercicios, con los cuales hemos podidos hacer Series, Data Frames para leerlos en los formatos .csv y excel. También aprendimos como guardarlos para su futuro uso.
Hemos avanzado bastante y ahora corresponde trabajar con Datos Reales, que a partir de esta publicación iremos buscando en internet donde encontraremos bastante material para trabajar. En ésta y en las próximas publicaciones profundizaremos en la Extracción de Datos.
Extract, Transform and Load / Extraer, Ttransformar y Cargar
Aquí tenemos la definición de wikipedia.
"Extract, Transform and Load («extraer, transformar y cargar», frecuentemente abreviado ETL) es el proceso que permite a las organizaciones mover datos desde múltiples fuentes, reformatearlos y limpiarlos, y cargarlos en otra base de datos, data mart, o data warehouse para analizar, o en otro sistema operacional para apoyar un proceso de negocio." Fuente

En esta ocasión tomaré los datos de la publicación: Daily Twitter Data Reports as of October 7, 2021 / 2,856 hive tweets of the day De la cuenta @hive-data. Que mejor forma de aprender con datos de nuestra propia comunidad.
Comencemos
link del Reporte. A continuación le damos click a dicho link y nos llevará a una hoja de excel.Al final de la publicación de @hive-data, nos dan el
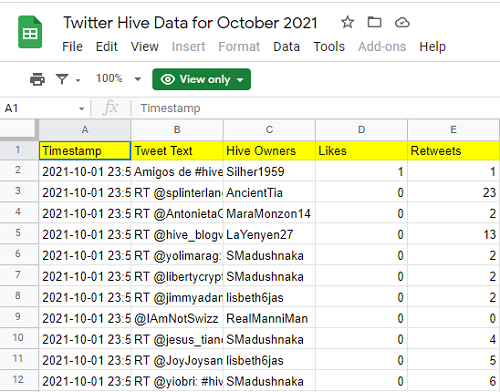
Escogí en esta oportunidad compartirlo (ya que es púbico) dentro de mi DRIVE de la siguiente manera. Otra forma es descargarlo en tu computador y luego subirlo a tu DRIVE.
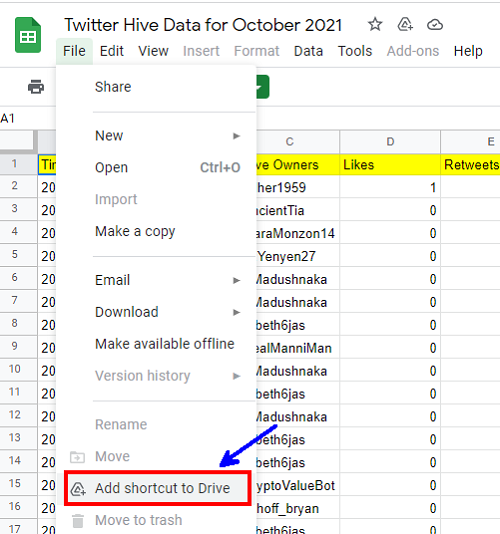
Así creamos el acceso directo a este archivo
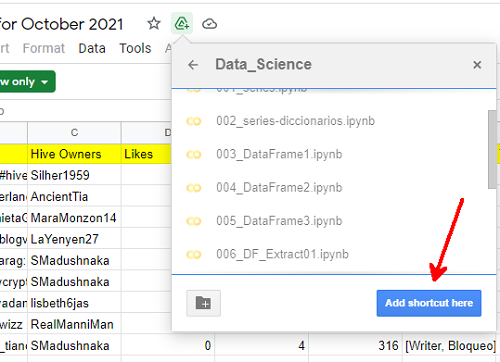
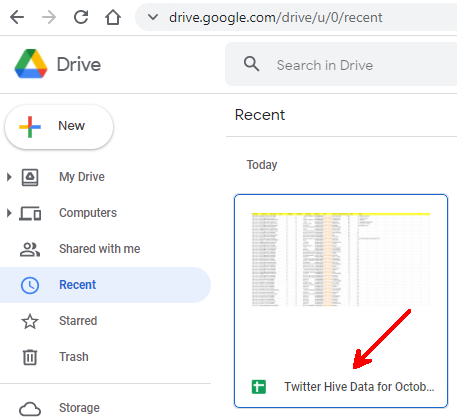
Verifiquemos lo que hicimos.

Conectando Google Sheets
Lo nuevo que haremos es conectar Google Sheets, que es la forma de google compartir las hojas de excel en la nube. Al escribir estas lineas de código nos generará una clave que debemos validar como hicimos en la publicación pasada para conectar nuestro DRIVE.
from google.colab import auth
auth.authenticate_user()
import gspread
from oauth2client.client import GoogleCredentials
gc = gspread.authorize(GoogleCredentials.get_application_default())
Luego abrimos la hoja de excel e importamos todos los valores
hive = gc.open('Twitter Hive Data for October 2021').sheet1
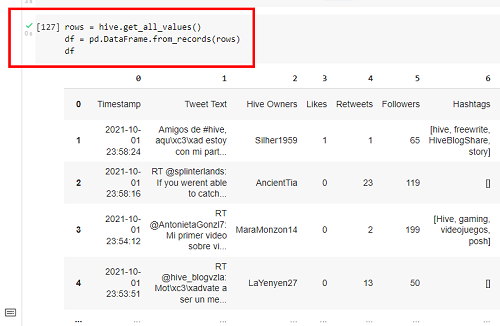
rows = hive.get_all_values()
df = pd.DataFrame.from_records(rows)
df
Aquí el Data Frame importado
Resguardo de información - Para trabajar con nuestro archivo, no con la fuente de datos.
Crearemos un un nuevo archivo de excel para nuestro uso, el cual nos servirá para trabajar
df.to_excel('/content/drive/MyDrive/Colab Notebooks/Data_Science/hive.xlsx')

Después de creado, entremos a nuestro DRIVE y lo abrimos para revisarlo
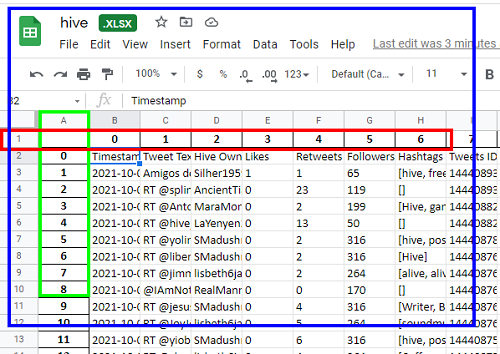
A continuación eliminaremos la primera fila (recuadro rojo) y la primera columna (recuadro verde).
OBSERVACIÓN: Este paso corresponde a transformar no lo abordo con código porque el interes de esta publicación es solo extraer los datos de una fuente externa. Más adelante en la transformación de datos veremos como se limpian los datos, como quitamos los datos que no nos interesa, etc.
Llamada de nuestro archivo excel
leer = pd.read_excel('/content/drive/MyDrive/Colab Notebooks/Data_Science/hive.xlsx')
leer
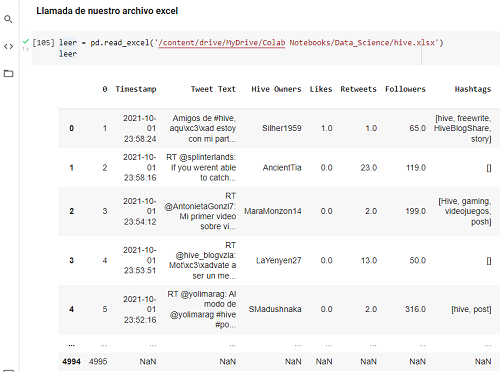
Recomiendo tomar en cuenta el primer registro y el último. Tomar una captura de pantalla o guardarlo. Ya que cuando limpiemos los datos estemos seguros donde comienza y donde termina la información.
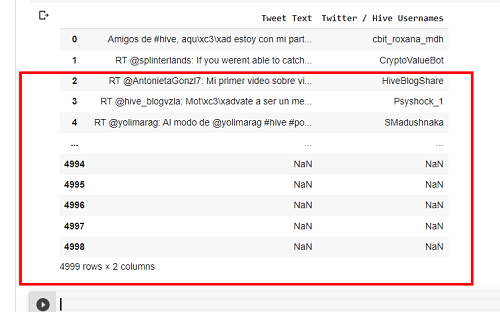
.
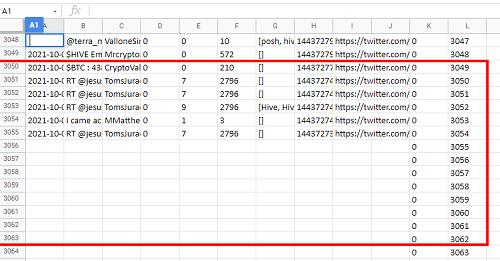
Notemos que más adelante debemos eliminar los registros que exceden nuestra información por estar vacios.
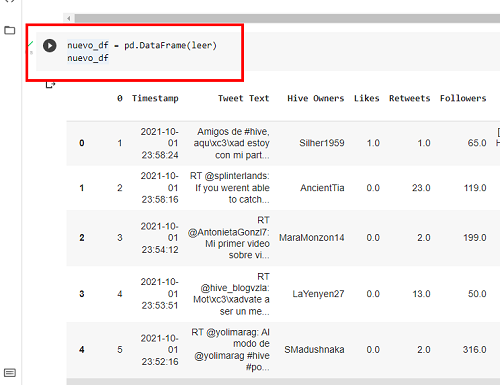
Por último cremos un nuevo Data Frame para hacer nuestros análisis.
Todo lo tratado en esta publicación está en este JupyterNotebook
Importancia de trabajar con nuestro archivo creado
Con nuestro archivo creado podemos trabajar sin comprometer la información original. Al crear nuestro archivo, tenemos en nuestro poder una copia del original y una copia creada por nosotros.
Importante: En este caso la información es pública y de seguro ya está replicada y resguarda. Éste archivo público solo permite lectura y no su modificación. Pero tomemos el caso donde se hace un estudio estadístico en un pueblo y la persona que vació la información la tiene solo en un Pen Drive, y nos lo facilita para vaciar la informacíon y cometemos el grave error de trabajar con los datos originales directo del pen drive, si sucede algo (que siempre va a suceder) perderemos toda la información. Recordemos "Si puede ocurrir, ocurrirá" repasemos la Ley de Murphy.
Publicaciones de esta serie:
Data Science N000. Preparando todo!
Data Science N001. Series
Data Science N002. Series a partir de Diccionarios
Data Science N003 - DataFrame con Diccionarios
Data Science N004 Recopilar datos de una tabla en excel y el formato .csv
Data Science N005 Resguardar datos con formato de excel y formato .csv
The rewards earned on this comment will go directly to the person sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.