Hey,
If you're working on hivemind like me you will most likely test your change locally by fiddling with the mocks and then realize that that you've broken all the automated tests upon pushing your code on the repository.
So obviously it's not optimal to wait for the pipeline to run, but understanding how the test runs can be a little tricky because everything is made to run with the pipeline, so it takes a while to read through all the scripts and steps. I'm here to save you the trouble.
This guide assumes that you have managed to sync hivemind at least once, if you didn't follow this guide: https://peakd.com/hivemind/@howo/hivemind-dev-environment-setup-guide-according-to-my-findings-it-may-or-may-not-be-the-best-way
You also need to install some dependencies:
pip install pytest
pip install pytest-parallel
pip install tavern
pip install deepdiff
Before running the tests, you need to sync your local hivemind database with all the mocks (there's a similar command on the other guide, if you don't understand how to run this command, follow the other guide):
hive sync --log-mask-sensitive-data --test-max-block=5000026 --test-profile=False --database-url postgresql://postgres:root@localhost:5532/hive --mock-block-data-path /home/howo/projects/hivemind/mock_data/block_data/follow_op/mock_block_data_follow.json /home/howo/projects/hivemind/mock_data/block_data/follow_op/mock_block_data_follow_tests.json /home/howo/projects/hivemind/mock_data/block_data/community_op/mock_block_data_community.json /home/howo/projects/hivemind/mock_data/block_data/reblog_op/mock_block_data_reblog.json /home/howo/projects/hivemind/mock_data/block_data/reblog_op/mock_block_data_reblog_delete.json /home/howo/projects/hivemind/mock_data/block_data/payments_op/mock_block_data_payments.json /home/howo/projects/hivemind/mock_data/block_data/notify_op/mock_block_data.json --mock-vops-data-path /home/howo/projects/hivemind/mock_data/block_data/community_op/mock_vops_data_community.json --community-start-block 4998000
Once that's done it's time to execute the tests.
some disclaimer: I tried and tried to use tox and other venvs like the pipeline, nothing works for 500 different reasons so I just gave up and run everything natively.
First run hivemind as a server to test scripts against:
hive --database-url postgresql://postgres:root@localhost:5532/hive server
then download this repository:
git clone https://gitlab.syncad.com/hive/tests_api
Now we need to define a bunch of env variables:
export TAVERN_DIR=/home/howo/projects/hivemind/tests/api_tests/hivemind/tavern # change it to whatever location hivemind is on your computer
export HIVEMIND_ADDRESS=localhost
export HIVEMIND_PORT=8080
export PYTHONPATH="${PYTHONPATH}:/home/howo/projects/test-tools/package:/home/howo/projects/tests_api/scripts/" # change this to where you downloaded tests_api
and finally you're ready !
you can execute a single test by passing the full path to the tavern yaml file:
pytest /home/howo/projects/hivemind/tests/api_tests/hivemind/tavern/bridge_api_patterns/get_trending_topics/empty.tavern.yaml
or test everything at once:
cd ~/projects/hivemind/tests/api_tests/hivemind/tavern # change it to whatever location hivemind is on your computer
find $directory -type f -name "*.tavern.yaml" | pytest --workers auto
note that this command requires https://pypi.org/project/pytest-parallel/ to be installed, it drastically speeds up testing by running it on multiple cores.
you will get an output like this (with ideally no Fs, each F means a test failed):

and for every failed case, the output will be stored next to the tavern file:
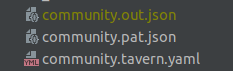
so you can compare it with the .pat.json (the expected output)
thanks for reading ! If you have any questions feel free to ask them in the comments.

Thanks for explaining that, I appreciate so much
Inspiring for the newbies
expect more from you
Please what's "Hivemind"?
What is it used for?
This is my first time hearing of it🙈🙈
Hivemind is a 2nd layer app on Hive that keep track of a lot of "social" data for blogging. Most frontend web sites(hive.blog, peakd, ecency, etc) use Hivemind to get most of the blockchain information they display (e.g. all the posts, comments, communities, etc).
Ohh Okay.. I get it now.
Thanks you! @blocktrades
Gracias por tu apoyo, es un gran incentivo para nuestra participación.
Leí tu publicación pero aún no entiendo😅 estoy aprendiendo.