
Dzisiejszy wpis będzie na temat anonimizacji, haseł, ładunków nuklearnych i hakerów, a nawet trochę o blockchainie. Wszystko z dodatkiem własnoręcznie tworzonych ilustracji. Interesujące połączenie? Jeśli tak, to mam nadzieję, że artykuł nie zawiedzie oczekiwań wysoko postawionych przez ten lekko click-baitowy wstęp.
Zacznijmy jednak od haseł i ich podstaw, a potem przejdziemy do bardziej interesujących elementów.
Hasła, hashe i... hamaki
Jak działają hasła, wszyscy wiemy. Ja mam hasło, nikt inny tego hasła nie zna, i dlatego ja mogę zalogować się do usługi z której korzystam, podając unikalną kombinację swojego loginu i hasła. Proste, prawda? Zakładam jednak, że nie każdy z czytelników interesuje się technikaliami i dlatego też nie każdy wie jak dokładnie "od zaplecza" wygląda proces logowania się na tradycyjny portal internetowy (tradycyjny, czyli np. nie steemit). W najprostszej wersji, proces logowania wyglądałby tak: leżymy sobie na hamaku z laptopem, otwieramy w przeglądarce mojulubionyportal.pl, podajemy w polu logowania swój login i hasło, przeglądarka przesyła je do serwera ze stroną mojulubionyportal.pl, a serwer tej strony sprawdza w swojej bazie, czy hasło podanego przez nas użytkownika, zapamiętane w bazie, jest równe hasłu które podaliśmy. Tak jak na obrazku poniżej:
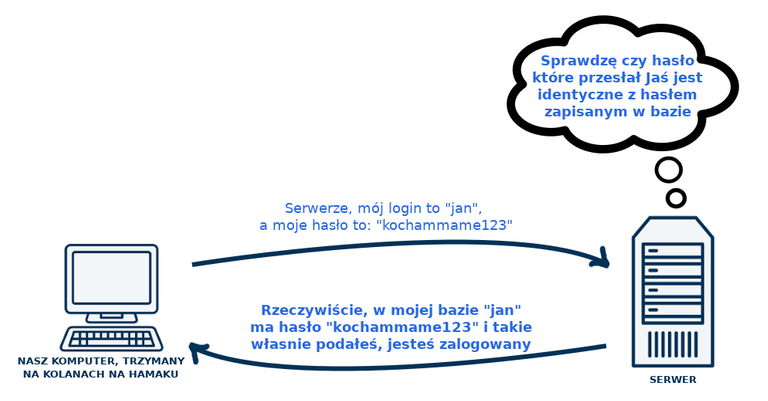
Zwykle w praktyce tak się jednak nie dzieje, a przynajmniej nie powinno. Oznaczałoby to, że nasze hasło jest zapisane na tym serwerze w tak zwanym "plaintexcie", czyli w postaci takiej samej w jakiej my to hasło mamy zapamiętane w głowie i w jakiej wpisujemy je w pole logowania się do serwisu. Mam hasło "kochammame123" i tak samo jest ono zapisane w bazie, jako "kochammame123". Jeśli haker, włamywacz lub kto inny uzyska dostęp do serwera tego serwisu, to pozna też nasze hasło. To z kolei jest bardzo niebezpieczne, jeśli takie samo hasło wykorzystujemy do innych serwisów (co nie jest zalecane), do których na przykład logujemy się jeszcze tym samym adresem e-mail. Co więc się robi? Hasło jest zapisane w bazie w postaci zahashowanej, z wykorzystaniem funkcji hashującej. Kto zna podstawy działania blockchaina, ten wie czym hashowanie jest. Funkcja hashująca to funkcja która przekształca jakiś ciąg znaków, w tym wypadku hasło, na inny ciąg, ale z zachowaniem pewnych istotnych cech tego nowego ciągu. Mianowicie ten przekształcony ciąg, hash:
- nie może zostać łatwo przekształcony na hasło z którego został wygenerowany. Czyli gdy mam
XyZ14I7d94rf#sk2to nie mogę odgadnąć, że stoi za tym "kochammame123" - zawsze jest takiej samej długości, niezależnie od długości hasła które zostało na ten ciąg przekształcone. Tak więc jeśli "kochammame123" zahashujemy jakąś wymyśloną funkcją hashującą, to otrzymamy
XyZ14I7d94rf#sk2, 16 znaków. Jeśli jednak zahashuję tą samą funkcją literki "abc", również powinienem otrzymać 16 znaków, na przykład73gfS32lfFS5631o. - Hash dla jednego hasła jest kompletnie różny od hasha dla innego, lecz bardzo podobnego hasła. Chodzi o to, że hashe dla "kochammame123", a "kochammame12", muszą być kompletnie różne. Mimo że hasła same w sobie są sobie bliskie, to hashe nie mogą być. Hash od "kochammame123" to
XyZ14I7d94rf#sk2, ale ten od "kochammame12" to nie będzie coś podobnego, czyli na przykładXyZ14I7d94rf#sk9ale raczej coś kompletnie innego, np.9321dsklcv23d$fe, bo w przeciwnym wypadku ułatwiałoby to odgadnięcie metodą prób i błędów co za danym hashem stoi. - dany hash powinien być generowany tylko przez jedno hasło. Nie powinno być tak, że zarówno "kochammame12" jak i "mojeHasloXYZ" dadzą ten sam hash
XyZ14I7d94rf#sk2. Gdyby tak było, mielibyśmy sytuację w kryprtografii nazywaną "kolizją" i mógłbym zalogować się na konto użytkownika który posiada hasło "kochammame12", poprzez podanie hasła "mojeHasloXYZ"
Jak niektórzy już sie domyślają, lub wiedzą, wszystkie te cechy sprawiają, że parą login+hash serwer mojulubionyportal.pl może posługiwać się jako równą z parą login+hasło, ale tak naprawdę nie zapisując trwale treści naszego hasła. Jak więc teraz wygląda logowanie? Leżymy sobie ciągle na tym hamaku, przesyłamy do serwera swój login i hasło, serwer ten z kolei przekształca nasze hasło określoną funkcją hashującą i otrzymany ciąg porównuje z naszym hasłem które jest zapisane w bazie w formie zahashowanej taką samą funkcją hashującą (zostało ono zahashowane i tam zapisane podczas rejestrowania się na portalu). Jeśli zahashowane formy naszych haseł są równe - ta w bazie i ta wygenerowana na podstawie naszego wpisanego hasła - to przeszliśmy proces autentykacji/uwierzytelnienia. I to wszystko leżąc na hamaku. Autentykacji nie należy jednak mylić z autoryzacją. Autentykacja lub inaczej uwierzytelnienie, to proces potwierdzający, że jesteśmy tym za kogo się podajemy (mamy dobre hasło do danego konta), natomiast autoryzacja, to proces następujący po uwierzytelnieniu, sprawdzający, czy mamy uprawnienia do danego zasobu. Nie będę jednak niepotrzebnie wchodził w szczegóły i się rozdrabniał, bo nie o tym jest artykuł. Tutaj obrazek prezentujący system bezpieczniejszy niż ten który był widoczny na poprzednim obrazku:
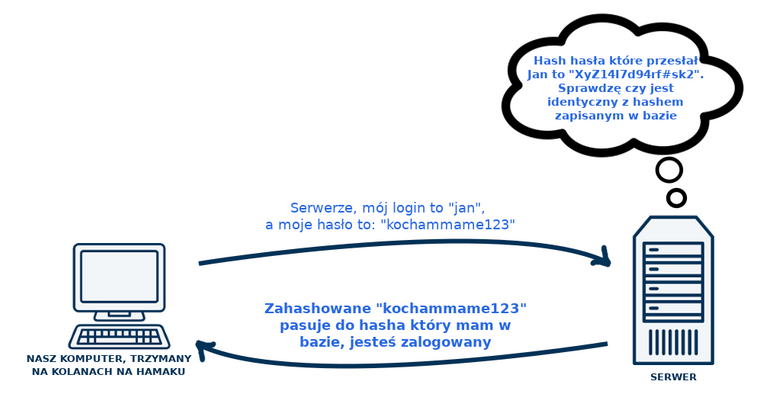
Hasło które przesyłamy do serwera nadal nie jest zahashowane, proces ten następuje dopiero na serwerze, dlatego też przesyłane hasło może być przez kogoś "podsłuchane". Od tego jest jednak SSL, temat na inny artykuł
Co to będzie, wycieki wszędzie
W miarę regularnie słyszymy, że z jakiegoś serwisu lub innej bazy, "wyciekły" hasła. Innymi słowy ktoś się do danego serwisu włamał i wykradł dane. Jeśli serwis ten przetrzymywał te hasła w "plaintexcie" który wyjaśniłem powyżej, tym większa afera. Jeśli nie przetrzymywał w plaintexcie, ale w formie hashy to istnieje szansa, że włamywacze lub ktoś inny hashe te "złamie", czyli pozna jakie hasło stoi za danym hashem. Jeśli haseł wyciekło dużo, lub oprócz nich ofiarą włamywaczy padły też dane wrażliwe, to też będzie większa afera (patrz wyciek danych z portalu randkowego Ashley Madison, specjalizującego się w oferowaniu usług ludziom w związkach, którzy szukają tak zwanego skoku w bok).
Tak czy inaczej, hasła wyciekają. My natomiast mamy różne konta, niektóre dawno zapomniane. Choć ja osobiście staram się trzymać pod kontrolą to gdzie i jakie konta posiadam, to wiadomo, w praktyce różnie bywa. Skoro te hasła natomiast wyciekają, to znaczy, że są dostępne publicznie. Czy możemy więc sprawdzić, czy nasze hasło znajduje się pośród którejś z tych baz dostępnych publicznie? Najlepiej, gdybyśmy nie musieli w tym celu pobierać tych wszystkich baz i szukać ich po sieci. W tym celu powstał serwis haveibeenpwned.com. Pozwala on nam sprawdzić dwie rzeczy:
- czy nasz adres e-mail znajduje się w którejś z baz kont, których dane wyciekły?
- czy nasze hasło znajduje się w bazie haseł złamanych lub takich które wyciekły w formie plaintext?
Pierwsza opcja nie budzi wielkich podejrzeń. Podajemy w formularzu na stronie https://haveibeenpwned.com nasz adres e-mail, a strona ta przeszukuje bazy z różnych wycieków i mówi nam, czy adres e-mail znajduje się w którejś z tych baz. Nic nie powinno się stać, jeśli ten swój e-mail wpiszemy, w najgorszym wypadku ktoś zacznie nam przysyłać spam na ten adres e-mail, myślimy. Strona jednak jest znana i poważana w sieci, można więc adres e-mail bezpiecznie podać w formularzu.
Jednak na niektórych serwisach z których dane i hasła wyciekły, mogliśmy nie podawać naszego adresu e-mail, a dane, w tym hasło, też mogły z niego wycieknąć. Czy nie lepiej byłoby skorzystać z opcji wpisania bezpośrednio naszego hasła i sprawdzenia, czy nasze hasło nie znajduje się w którejs z baz, zamiast wpisywać tylko adres e-mail powiązany z tymi hasłami? Takie coś oferuje nam formularz na podstronie "Passwords" wspomnianej powyżej strony haveibeenpawned: https://haveibeenpwned.com/Passwords
Tutaj już powinna nam się zapalić czerwona lampka, bo przecież nie powinniśmy naszych haseł do portali wpisywać w innych miejscach niż te portale. Może to jedno wielkie oszustwo twórcy haveibeenpawned i hasło to jest zapisywane na jego serwerze, i tak jak nie było ono dostępne dla hakerów wcześniej, tak już po naszym wpisaniu hasła w formularz, będzie?
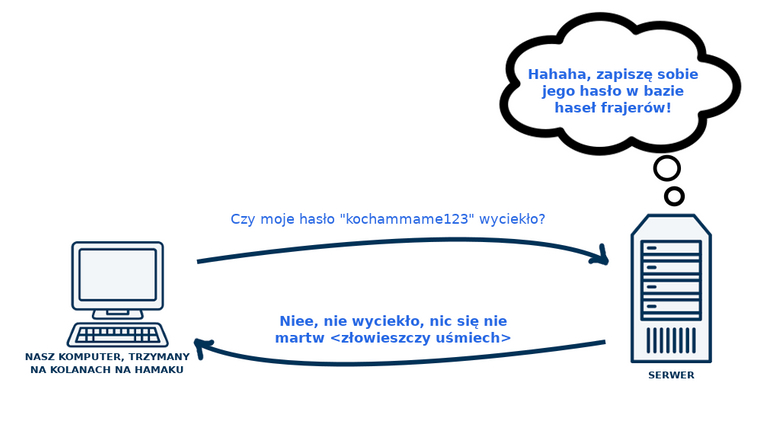
Tutaj zastosowano jednak pewną sztuczkę, dzięki której hasło możemy podać i nie trafi ono na serwer stojący za tym serwisem. Sztuczka wykorzystuje coś co nazywa się "k-anonimowością".
Na scenę wkracza k-anonimowość
Na chwilę pomińmy jeszcze k-anonimowość i zobaczmy jak moglibyśmy ten problem rozwiązać nie wiedząc nic o k-anonimowości. Jednym z rozwiązań tego problemu byłoby zahashowanie hasła po naszej stronie, po stronie przeglądarki i następnie przesłanie takiego hasha do serwera haveibeenpawned.com. Serwer ten porównywałby hash który mu przesłaliśmy, z hashami haseł które posiada u siebie, wykonanymi tą samą funkcją hashującą z której my skorzystaliśmy. Gdyby znalazł u siebie taki hash jak przesłaliśmy, to daje nam informację zwrotną "tak, Twoje hasło kiedyś gdzieś wypłynęło, bo mam je w bazie haseł które wyciekły". Ale chwila moment, przecież wtedy ten serwer mógłby sprawdzić które z haseł w jego bazie w efekcie zahashowania daje hash taki, jak my przesłaliśmy. Mógłby więc sprawdzić, jakie wpisaliśmy hasło, zakładając, jeśli takie hasło już w bazie ma. Nie byłoby to więc idealne rozwiązanie.
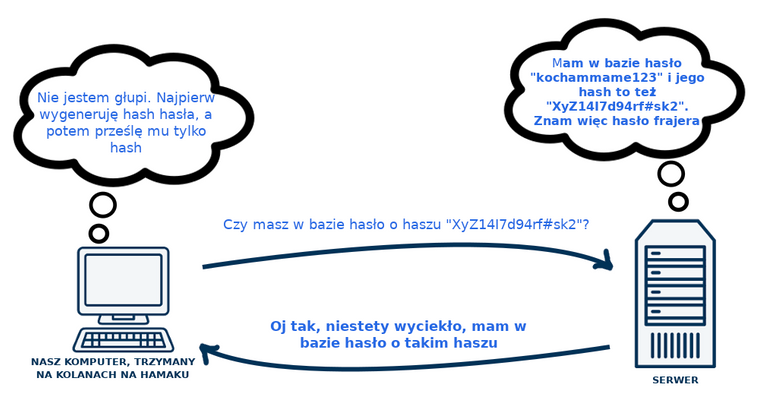
k-anonymity, czyli tłumacząc na polski "k-anonimowość" jest rozwiązaniem tego problemu. Jest to koncept przedstawiony w 1998 roku przez dwie badaczki Latanya (Latanię?) Sweeney i Pierangelę Samarati. Koncept ten powstał jako próba rozwiązania problemu wykorzystywania danych powiązanych z pewnymi ludźmi, w taki sposób, by można było na tych danych operować, przeprowadzać badania statystyczne, ale by nie można było zidentyfikować do kogo te dane są przypisane^. Innymi słowy, jak te dane zanonymizować. Natomiast przecież dane łatwo się anonymizuje, powiecie, po co nam do tego jakieś dodatkowe pojęcia takie jak "k-anonimowość"? Wystarczy z tabelki w excelu usunąć kolumny "Imię", "Nazwisko". Niestety nie zawsze. Powiedzmy, że mamy szpital, który trzyma dane na temat pacjentów i chce przekazać je badaczom. Na przykład dane dotyczące pracowników rządowych którzy byli pacjentami szpitala. Przekazuje te dane, jednak dbając o prywatność usuwa kolumny zawierające imie, nazwisko, PESEL, dokładny adres i inne tego typu. Pozostają kolumny z kodem pocztowym, płcią i datą urodzenia, dane dotyczące recept, lekarzy do jakich dana osoba zawitała i tak dalej i tak dalej. Dane zanonimizowane i gotowe do przeprowadzania badań statystycznych, na przykład sprawdzenia, czy pracownicy rządowi zamieszkali pod danym kodem pocztowym częściej chorują na grypę, czy może na... choroby weneryczne.
 Ówczesny gubernator Massachusetts. Chciałem napisać, że pewnie gdy Sweeney udowodniła mu, że dane nie są anonimowe, to zrobiło mu się łyso, ale jak widać, włosy nieźle się go trzymają ;)
Ówczesny gubernator Massachusetts. Chciałem napisać, że pewnie gdy Sweeney udowodniła mu, że dane nie są anonimowe, to zrobiło mu się łyso, ale jak widać, włosy nieźle się go trzymają ;)
Podobne przekazanie danych międy szpitalem a badaczami miało miejsce w roku 1997. Zauważyła to właśnie wspomniana Latanya Sweeney, jedna z autorek k-anonimowości. Gubernator Massachusetts zapewniał o tym, że zadbano o prywatność osób których dane były przekazywane. Latanya słusznie zauważyła jednak, że zwykła anonimizacja nie była wystarczająca. Za 20 dolarów kupiła publicznie dostępne dane na temat polityków biorących udział w głosowaniach i skorelowała znalezione tam dane gubernatora - jego kod pocztowy, datę urodzenia i płeć, z danymi udostępnionymi przez szpital. Tylko jeden rekord ze zbioru szpitalnych danych pasował do danych gubernatora. Tym samym Latanya mogła poznać treść recept gubernatora, który o anonimowości zapewniał^. Wystarczył jego kod pocztowy, płeć i data urodzenia.
Co poszło nie tak, co można by zrobić inaczej? Z danych można by usunąć też kod pocztowy, płeć i wiek danej osoby, kompletna anonimizacja. Tylko co nam wtedy po takich danych? Badaczom nie przydadzą się one już wtedy na wiele. Jak więc zanonimozować dane, ale zachować ich przydatność dla badaczy? Można upewnić się, że w bazie jest więcej niż jedna osoba z takim samym kodem pocztowym, płcią i datą urodzenia. Jeśli takich osób będzie 2, to dane są 2-anonimowe. Jeśli będzie ich k, to będą k-anonimowe. Odpowiednio wysokie k gwarantuje nam, że zidentyfikowanie konkretnej osoby nie będzie łatwe. Różne są metody na osiągnięcie k-anonimowości, jedną z nich jest na przykład generalizowanie - zamiast podawać dokładny wiek czy datę urodzenia, możemy ludzi podzielić na zbiory. "Od 18 do 25 lat", "od 25 do 35" i tak dalej. Wtedy Jan Kowalski mający lat 19 i Jan Kowalski mający lat 24 będą w bazie widoczni tak samo, nie będzie już tak łatwo ustalić który jest który.
Dobra, to jak to się ma do strony haveibeenpwned.com która pozwala nam sprawdzić czy nasze hasło znajduje się w bazie haseł które wyciekły? Skończyłem opisywać ten system na przesyłaniu do serwera hasha naszego hasła i sprawdzaniu po stronie serwera, czy taki sam hash istnieje. Co nie byłoby dobre, bo znając hash serwer może sprawdzić które hasło z jego bazy daje taki sam hash. Ale! Możemy serwerowi przesyłać tylko początkowe kilka znaków naszego hasha. Serwer wtedy sprawdza jakie ma hashe zaczynające się na te kilka znaków i wszystkie je nam przesyła. Wtedy dopiero my sobie weryfikujemy, czy nasz pełen hash jest na tej liście kilku, kilkunastu, kilkuset hashy które dostaliśmy. Jeśli jest - nasze hasło jest w bazie haseł. Voila! Nie musimy pobierać całej ogromnej bazy haseł z różnych wycieków i przeszukiwać jej na naszym komputerze.
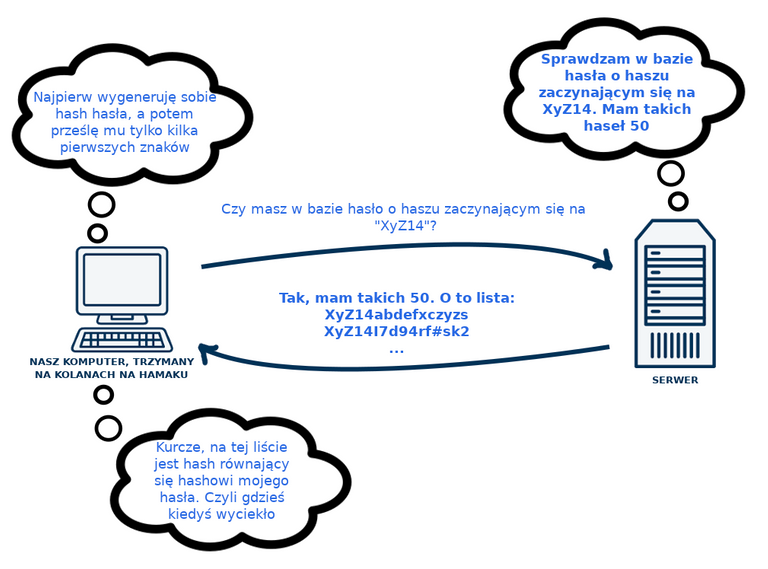
Oczywiście nie musimy ufać, że strona działa tak jak opisałem, jeśli jesteśmy trochę bardziej techniczni, możemy ręcznie wygenerować sobie hash naszego hasła i przesłać jego kilka pierwszych znaków, a następnie przeszukać listę zwrotną pod kątem pełnego hashu, jak zaprezentowano na tym wideo opisującym jak wspomniana strona działa:
Jaki z tego wniosek? Niedocenianie metadanych jest groźne. Czy przeszkadzałoby Wam gdyby Wasz operator nagrywał Wasze rozmowy lub ktoś je podsłuchiwał? Pewnie tak. Co natomiast z billingami i historią stacji przekaźnikowych BTS z którymi Wasz telefon się łączył? To już tak bardzo nie martwi. Można powiedzieć, że billingi i stacje przekaźnikowe z którymi nasz telefon się łączył to metadane, a nie dane właściwe, te na których tajności nam zależy. To teraz wyobrażcie sobie hipotetyczny skrajny przypadek - sprawdzamy billing jakiegoś obywatela, widzimy, że rozmawiał z numerem pod którym znajduje się telefon zaufania dla samobójców, a stacja BTS z którą się łączył pokrywa głównie teren w okolicy rzeki, w szczególności wysoki most na tej rzece. To tylko metadane, ale delikatnie sugerują nam, że ten człowiek chciał skoczyć z mostu. Delikatnie...
Dowód z wiedzą zerową, czyli w końcu o tych bombach
Kolejnym tematem związanym z anonimizacją danych, przy zachowaniu jej użyteczności, jest dowód z wiedzą zerową, czyli zero-knowledge proof, pojęcie powstałe w roku 1989 za sprawą pracy naukowej "The Knowledge Complexity of Interactive Proof-Systems"^ . Dowód z wiedzą zerową oznacza, że jesteśmy w stanie komuś udowodnić, że coś wiemy, bez ujawniania dokładnych informacji na temat tego co wiemy. Bardzo łatwo udowodnić koledze, że wiem iż stolicą Argentyny jest Buenos Aires poprzez powiedzenie mu "Kolego mój drogi, stolicą Argentyny jest Buenos Aires". Trudniej jest udowodnić, że wiem jaka jest stolica Argentyny, bez mówienia mu, jak ona się nazywa! Po co to robić, spytacie? Czasem jesteśmy zmuszeni, by jakieś dane na swój temat udostępnić, mimo, że nie koniecznie tego chcemy. Biorąc kredyt musimy udostępnić swoją historię transakcji finansowych, czy nie lepiej byłoby udowodnić, że jesteśmy wypłacalni, bez pokazywania dokładnej historii transakcji? Jeśli jesteśmy potężnym krajem i zgodziliśmy się zniszczyć określoną część naszego arsenału atomowego, to musimy sobie wzajemnie z innymi mocarstwami udowodnić, że zniszczenia broni dokonaliśmy, że nie zniszczyliśmy jakiejś atrapy bomby. Nie chcemy jednak wyjawiać sekretów na temat tego jak działa i wygląda nasza broń atomowa.
Jak może działać dowód z wiedzą zerową? Wyobraźmy sobie, że mamy kolegę który jest daltonistą. Macie dwie piłki, czerwoną i zieloną. Chcecie udowodnić koledze, że te piłki są różnego koloru, bez wyjawiania mu jakiego koloru są. Kolega może te piłki wziąć w ręce, jedną w lewą a drugą w prawą, następnie schować je za plecami i zamienić je miejscami, lub nie. Pokazuje nam piłki ponownie, i pyta nas, czy zmienił piłki miejscami gdy miał je za plecami? My kolory widzimy, więc jesteśmy w stanie powiedzieć, że zamienił - lub nie. Kolega myśli jednak, że może mieliśmy szczęście i strzelaliśmy a tak naprawdę piłki są identycznego koloru, i nie byliśmy w stanie rozpoznać czy zamienił je za plecami czy nie. Mieliśmy 50% szans. Więc robi ponownie to samo, chowa piłki za plecami i zamienia miejscami lub nie, po czym pyta nas, czy piłki zostały zamienione. My odpowiadamy. Powtarza się to kilka razy, dzięki czemu szanse na to, że mieliśmy szczęście, stają się mikroskopijne. Kolega jest przekonany, że piłki mają różny kolor, bo byliśmy w stanie odgadnąć kiedy je miejscami zamienił, a kiedy nie, ale nie wie tak naprawdę jaki kolor piłki mają.
To przykład interaktywnego dowodu z wiedzą zerową, bo musieliśmy z naszym kolegą daltonistą podjąć interaktywną zabawę. Taka metoda ma pewną wadę - przekonaliśmy tylko naszego kolegę. Gdy spotkamy innego daltonistę (takiego który nie rozpoznaje barwy czerwonej i zielonej, gdyż są różne rodzaje daltonizmu), to musimy go przekonywać od nowa. Istnieją jednak też metody nieinteraktywne. Jedną z nieinteraktywnych metod jest zk-snarks, wykorzystywana w kryptowalucie Zcash do anonimizacji transakcji w blockchainie. Z kolei zespół zajmujący się tematyką blockchain w banku ING opracował ulepszoną wersją tak zwanego zero knowledge range proof^ pozwalającego udowodnić na przykład, że wypłata wnioskującego o kredyt mieści się w zakresie który pozwala mu o kredyt wnioskować, bez zdradzania tego ile dokładnie wnioskujący zarabia (o ile zakres jest odpowiednio duży).
Wadą dowodu z wiedzą zerową jest to, że nigdy nie zapewni nam 100% pewności. Chociażby przykład z daltonistą pokazuje, że pewności nie ma. Zawsze istnieje malutka szansa na to, że udało nam się przypadkowo odgadnąć czy piłki były zamienione za plecami czy nie. Jednak przy odpowiednio dużej ilości powtórzeń, ta szansa jest oczywiście na tyle mała, że często nie należy się nią przejmować. W przypadku wspomnianego zk-snarks z kolei, wadą jest iż algorytm ten jest "ciężki". Wymaga dużo mocy obliczeniowej.

Jest jeszcze jedna potencjalna wada, wynikająca z tego jak dobra jest metoda dowodu z wiedzą zerową - utrata informacji. Jeśli jakaś grupa ludzi posiada pewną tajemnicę i zamiast ją udostępniać będzie jedynie udowadniać, że tę tajemnicę zna, to istnieje ryzyko, że gdy stracimy kontakt z tymi jednostkami/osobami, to tajemnica przepadnie kompletnie. Jeśli zbyt często polegać będziemy na dowodzie na istnienie informacji, a nie informacji samej w sobie, możemy dostęp do tej informacji stracić. Jak do sejfu do którego hasła zapomnieliśmy, bo do środka bardzo długo nie zaglądaliśmy - starczyła nam wiedza, że mamy tam dużo pieniędzy.
Co z tymi bombami atomowymi? W 2016 roku zaproponowano metodę weryfikowania czy zniszczono prawdziwą bombę atomową. Metodę opartą właśnie o dowód z wiedzą zerową. Sam pomiar promieniowania w elementach arsenału przeznaczonego do zniszczenia nie wystarcza, by udowodnić, że mamy do czynienia z bronią atomową, z kolei badanie składu i charakterystyki izotopu może potwierdzić, że mamy do czynienia z bronią, ale wyjawia też cechy tej broni które mocarstwo może nie chcieć ujawniać. Metoda opracowana w roku 2016 zakłada, że kraj który stworzył arsenał przeznaczony do zniszczenia tworzy szablon, swego rodzaju negatyw broni atomowej, który ustawiamy w jednej linii z egzemplarzem broni atomowej. Broń atomowa może być ukryta przed widokiem np. w "czarnej skrzyni". Przez taki zestaw szablonu i egzemplarzu broni atomowej przepuszczamy wiązkę neutronów. Powstałe w ten sposób dane wykrywane przez odpowiedni detektor powinny stworzyć coś w rodzaju "białego obrazu" na którym nic nie widać - gdyż broń atomowa oraz jej negatyw się uzupełniają wzajemnie. Możemy wymienić egzemplarz broni atomowej i podstawiać pod nią każdą inną bombę z danego arsenału. Jeśli te bomby będą prawdziwe (będą pasować do negatywu), to zawsze w rezultacie przepuszczenia w odpowiedni sposób wiązki neutronów przez szablon/negatyw oraz egzemplarz broni, uzyskamy "pustkę". Zniechęca to też do prób oszukiwania, gdyż jeśli egzemplarz broni nie byłby prawdziwy, to z wynikowego "obrazu" można by odczytać jakąś część charakterystyki broni atomowej tego mocarstwa, gdyż jest ona zawarta w negatywie samym w sobie i objawi się w obrazie wynikowym (zamiast pustki).^. Jak zauważył użytkownik serwisu Wykop "anadyomenel", jest jedna wada tej metody - musimy być pewni, że pierwszy egzemplarz testowanej bomby też jest prawdziwy, np. wzięty z zasobów aktualnie wykorzystywanych przez dane mocarstwo, gotowych do użycia. To słaby punkt całej idei, gdyż jeśli pierwsza bomba była atrapą i negatyw został zbudowany w oparciu o atrapę, możemy zostać oszukani.
Wspomniany szablon/negatyw nie jest dosłownym szablonem przedstawiającym negatyw kształtu bomby atomowej. To bardziej metafora, negatyw jest odwrotnością pewnych fizycznych cech ładunku atomowego znajdującego się w bombie, jego właściwości promieniotwórczych. Celowo nie wnikam w szczegóły działania tego mechanizmu, gdyż nie jestem ekspertem w fizyce. Ogólne założenie jednak jest pięknym przykładem zastosowania dowodu z wiedzą zerową w praktyce, nie w formie matematycznego wzoru, ale swego rodzaju fizycznego eksperymentu. Więcej na ten temat możecie przeczytać tutaj.

źródła obrazów: tytułowe, wektory użyte w moich grafikach, wektory c.d., gubernator, zcash logo, sejf, separator
inne źródła i inspiracje, niewymienione w tekście: 1, 2
Ile literek :O
Aż się miło czytało :)
Dzięki. Ceszę się, że czyta się miło :)
Twój post został podbity głosem @sp-group-up Kurator @julietlucy.
This post is supported by $0.12 @tipU upvote funded by @fervi :)
@tipU voting serviceinstant upvotes | For investors.