We know that plagiarism is bad, identity theft is bad & we have @cheetah, @spaminator, @steemcleaners etc taking a strong stand against it. They combines NLP (Natural Language Processing) and human intelligence.
Now, what if there is a way to circumvent all this an effective way and still being correct from a "original content" and copy right stand point.
Here the ethics is not weighed, but a scenario is given and an algorithmic approach using NLP and Computer Vision (CV) and deeper analysis of content its similarities. Further, spelling mistakes MUST be considered as a "positive", Too "perfect" grammar has to be considered a trigger.
Now the components are just assembled & the basic tool used is wcopyfind. This has limited the availability for now as instead of using a scalable architecture WINE software is used to run wcopyfind on a Debian Box which slows down the entire process.
While I was upto this, wcopyfind had found headlines by bringing Shakespere to the mix.

(By Steve Evans from Citizen of the World (London Shopping 0017) [CC BY 2.0], via Wikimedia Commons)
- Plagiarism software finds Shakespeare plundered cool words from a little-known book
- The Guardian has a neutral, piece :
Plagiarism software pins down new source for Shakespeare's plays
While I am no one make any comment on the news, my use of wcopyfind did give some confidence.
Steemit based Business model
The elevator pitch:
This is a lean & scalable business model using the fastest, FREE blockchain & circle-voting scenario which is 100% legit & practical.
- Identify one content writer - may not be on steemit
- One or two models
- Create accounts using the original identification of the models and receive model release and agreements in place
- Establish a remuneration model & a commission structure
- Create a content generation
- Plan few simple shoots with the models
- carefully distribute the photos as taken with multiple cameras
- content writer is assigned tasks and paid for words
- The operator posts content across multiple accounts ensuring maximum ROI
- circle vote
- Once the proof of work is identified and a certain followers are accumulated with "social engineering", go for "whale pitches"
- Pitch some whales, get STEEM delegations or setup up voting mechanism with a profit share
- anyone asks for proof of id, the models gives their identification as per the arrangement
- Everyone gets paid.
Now I am not sure whether this is already attempted or not, but sounds like a good plan to make some quick money. If we can diversify and hire models across various ethnic and other orientation, this can be scaled to ensure a substantial revenue.
The diversification can be directly proportional to the steemit traffic to ensure maximum ROI.
a business model canvas eagerly waiting a whale to be filled and made into a proposal

(By Business Model Alchemist (http://www.businessmodelalchemist.com/tools) [CC BY-SA 1.0], via Wikimedia Commons)
An algorithmic approach to identification of the business model
From the NSA leaks and all other recent data leaks, we might have heard about the word "Meta data". This is very important as meta data is often ignored and can be used to identify patterns.
The algorithm has to mimic a human being and look for what human beings do best - mistakes!
"No one is Perfect"
Experienced content writers and also authors follow few patterns:
Rule0
- Similar grammatical structure and choice of words
- Either crisp or long sentences but often with near equal number of words
- Punctuation are always used
- Slang is avoided
- No incomplete sentences eg:- But ....
- Proper capitalization
- Two sentences are always separated by the same amount of SPACE or TAB (Delimiter)
- Experienced bloggers will have smaller sentences with near equal number of words in each sentence
- Experienced bloggers will give importance to Above the FOLD content as opposed to Below the Fold content (eye tracking, mouse tracking, higher click-through, attention span)
We all follow certain words in sequences without our own knowledge.
Bingo. As the New York Times reports:
In the dedication to his manuscript, for example, North urges those who might see themselves as ugly to strive to be inwardly beautiful, to defy nature. He uses a succession of words to make the argument, including “proportion,” “glass,” “feature,” “fair,” “deformed,” “world,” “shadow” and “nature.” In the opening soliloquy of Richard III (“Now is the winter of our discontent …”) the hunchbacked tyrant uses the same words in virtually the same order to come to the opposite conclusion: that since he is outwardly ugly, he will act the villain he appears to be.
Now, from a STEEMit perspective, we can formulate that,
Rule_Set1:
- Spelling mistakes are good
- Incomplete sentences, slang etc are good!
- Minimal or one or two plagiarized posts is good
- Grammatical errors, Extra long sentences and Paragraphs are good
Rule_Set2: Basic Computer Vision and Textual analysis
A Photo can tell stories but metadata can make those stories real
- Look for visually similar images - flickr is a mandatory data source
- look for licensing
- Majority of the free to use images are "Editorial Use" & needs attribution
- Not giving attribution and back-link irrespective of the licensing of the work MUST trigger an alarm.
As a matter of fact I give high weight to any sort of slightest abuse of photographs as I have personally a victim of theft and I know the effort behind each and every photograph even from a serious ameature. Myself have faced near death scenarios, hit by charging bulls, nearly held hostage etc. I have known legends like Victor George & K J Vincent who died while working on their last assignments.
K J Vincent was hit by a train & I had met him only once - for the first and last time.
Rule_Set3: Meta data extraction and comparison
When a single master account is employed, often there will be precious information like camera, model, time stamps & geo-location data hidden inside the IPTC - EXIF tags.
- Extract EXIF
- Use time stamps to compare against target accounts
- Triangulate position if geographical information is available
Rule_set4:
This is very minimal for now.
- Analyse memos - not done
- Posting time stamps, intervals
- Apps used
Putting it all together
We will not be looking for only internet, google books, PubMed or other scientific journals alone. We have to start without ourself and look for good content and use it to to train the neural network.
- Apply Rule0 and group the good authors
- This helps to whitelist/greylist/blacklist users and avoid wasting CPU power.
- This takes out all the good writers / good Samaritans out of the cross checks (sort of)
- Good authors are given certain weightages & used as the benchmark to compare against
- This has disadvantage that the very first author employing a paid content writer will mostly be marked legit
- But the reasoning is, if @cheetah, @spaminator, @blacklist-a & @steemcleaners have failed, no point in attempting again.
Scenario 1: A new legitimate user joins steem
This will invoke a trigger as he will pass checks for "too good" as per Rule0 & will undergo plagiarism checks. (Make few spelling mistakes or spaces or unwanted comma and the algorithm fails!) Soon the algorithm will internally assign a "good Samaritan Medallion" and put the case for rest. This is not the best approach as such and needs to be tweaked. But, other systems will be able to track deception.
Scenario 2: A second user managed by a good user joins
This is when the alarm rings! The Rule0 kicks in, Rule_Set1 fails & a comparison of typical plagiarism content is done. A mutual comparison and check against "Good Samaritan" list is made. By this time Rule_Set2 may either come back with a good score or a bad score.
In either case, of Rule_Set2 is good or bad, the sets of "Good Samaritans" and new users and compared further. If the score shows significant similarities between users or triggers a normal plagiarism check, voting patterns are analyzed based on the group of voters, time of votes after the post and a (unique) set is extracted from multiple posts.
In a nutshell, if the intersection of all the voters exists & an intersection of these users against the "Good Samaritan" set exists, we have a match. [basic set theory]
In simpler terms, if the same people are voting the posts and there is a similarity of content, it means there is some sort of collaboration. It doesn't prove anything though.
so what are we saying ?
Well,
- Its impossible to detect types of plagiarism where people are adapting content from non-digitized sources
- Its very difficult and impossible to deny the possibility of using an army of paid users and models to generate original content
- The scenario is perfectly legal as no one has a concern about copy right violations or any rights.
Do we have a deal ?
So the question is, if this business model is possible and working, do I get investors ? See, I even have the business model canvas downloaded and ready !!!!!
Questions left unanswered
- Are there proven instances of this happening ?
- What will be the stand of @steemcleaners & the community ?
- Is this morally & ethically correct ?
Before the down-votes come
The algorithm, the bot, API, NLP all are words of fiction. None of them exists. Any resemblance to movies under any licensing arrangements is PURELY coincidental but any resemblance to works under public domain and derivatives allowed creative commons share alike-commercial is not. Any resemblance with DEAD are coincidental if there is anyone with legal heir ship and ready to take legal action if not its intentional. No person living has nothing to do with it as all this is just a simulation. No bots, software, computers, unicorns or ICOs were hurt in the process of writing this article. No white papers were read, torn apart or burned during the process too.
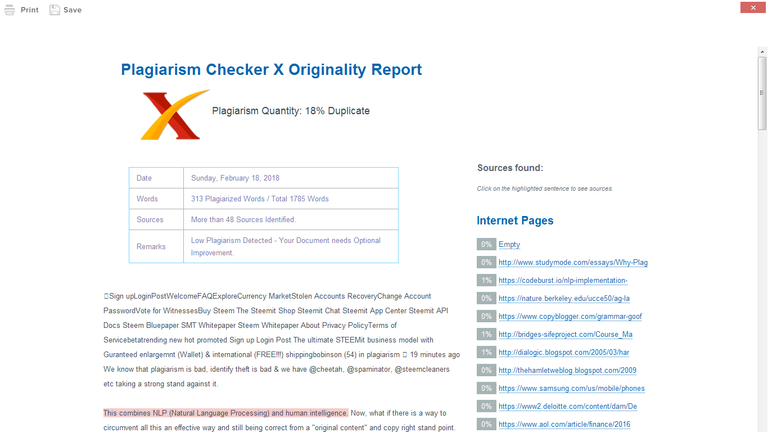
(I didn't even press any buttons of anti-plagiarism software - I hired a pro by offering an upvote to do that for me!)
Like someone said, "Don't be fooled by randomness or the lack of it. All that matters is up-votes."
Vote for me as STEEM witness
- You can do so by clicking the link above & enter your private key when asked for.
- Alternatively, visit https://steemit.com/~witnesses
THIS IS A TRIAL RUN AND BETA TEST
Congratulations! Your post has been selected as quality content that deserves more attention.
I upvoted your contribution because to my mind your post is at least 27 SBD worth and should receive 59 votes. It's now up to the lovely Steemit community to make this come true. By the way, your post is listed on rank 10 of all truffles found today! You can find the top daily truffle picks here.
I am
TrufflePig, an Artificial Intelligence Bot that helps minnows and content curators using Machine Learning. I was created and am being maintained by @smcaterpillar. If you are curious how I select content, you can find an explanation here!Have a nice day and sincerely yours,

TrufflePigPS: Upvoting and resteeming my posts and comments will support paying for server costs and further development, thank you ;-)
Thank you. This is indeed a very interesting project. Wishing you all the very best.
LIMITED TIME OFFER
The first 100 upvoters will be sent my EXCLUSIVE e-book on effective plagiarism tricks!
Hurry while the bitcoin charts are up.
I need it
I dont get the tech points but hope to receive your ebook
I checked your content and since you are writing own content I think you are eligible for teaching advanced plagiarism techniques.
However the soon to be published e-book on "deception, identify theft without identify theft for fun & profit" will be apt for you!
Thanks a lot
now you understood all the gimicks mentioned above right ?
Posts like this should go to the Trending Page :) What a nice compilation.
@sanmi You have been kicked by the bitcoin-donkey!!! Open your Wallet to find the treasure!!!!!!
Also sent me 1 SBD (ONLY) to avail the life long membership to my exclusive discord channel ... thats where all the new tricks are taught. I will also be teaching how to milk the bitcoin-donkey as I liked ur comment.
whats bitcoin donkey?
Only @sanmi knows !!!
Hai @bobinson .Literally I didn't understand the technical things you are talking about..I'm still a noob at it..But as I'm here on steemit it is necessary to know all sorts of these things..and nothing is impossible if one has the desire.
Although my vote value is much less ,I'm one among the first 100 upvoters..So do send me the e-book..who knows, ഒരുപക്ഷേ ഞാൻ ഭാവിയിലെ തിമിംഗലമായിരിക്കും!
No whales lives in Idukki :-)
the business model that you propose sounds familiar... sometimes i see contrasting difference in the level of interaction esp. when i interact with people offline vs. what i see when i read 'their' blogs...
Ethical, may be yes... till the time they are bringing new and original content... content has some value... moral??? thats individual preference...
Hey Bob, what a wonderful post! But one question here, you said spelling mistakes, grammatical mistakes are good? But don't you think if your post has grammatical mistakes it will sometimes change the message/meaning of that particular statement? also my last question would be at what % should a post be declared as plagiarized, because I had been recently caught by cheetah for using a sentence, my post had about 200 words in it & it still was marked as plagiarized! What steps should be taken in this case?
The context is different here. What I meant to say is that, in general people will make mistakes and professional writers and bloggers whose primary job is writing tend to make lesser mistakes.
So to identify a unique scenario of someone employing a paid content writer can be identified quickly by the lack of spelling mistakes. ie one quick metric but not very accurate.
Also this is based on my personal habit of missing out spell checks and never doing grammar checks.
I am not sure of how @cheetah works. For example some software has identified this very post at 18% plagiarized. but the content is in quotes - ie copied content. So the percentage is subjective. This article for example is not plagiarized but it definitely resembles many & the final 2 paragraphs have ripoffs from popular movie disclaimers and "don't be fooled by randomness" is from a book by Nassim Nicholas Taleb
Thank you for this post, you have a lot to share my friend, I'll continue reading your post :)
I really like this post bobinson! keep up the good work!
I'm following you Follow me also
@steemcleaners : follow - follow spam. FYI.
resteeming this using resteemable
Your Post Has Been Featured on @Resteemable!
Feature any Steemit post using resteemit.com!
How It Works:
1. Take Any Steemit URL
2. Erase
https://3. Type
reGet Featured Instantly � Featured Posts are voted every 2.4hrs
Join the Curation Team Here | Vote Resteemable for Witness
Excellent piece of work. Great to have a Witness like you. At the end of each post you should put something saying that you are a witness.
Thanks buddy :) Just added it again ...
btw, the bot I mentioned is for real. Some initial work was done here : https://steemit.com/hello/@thefreebird/init-1
I just became the third follower.
One thing I must add is sometimes people just make their own sub-communities. Some people regularly upvote and resteem the same author. I've done that myself and I have some people who do that for me. There are also auto voting where every post of an author is upvoted by another person. You'll have to consider these aspects.
Keep up the good work!
Yes - I don't see any problem in that. I actually upvote your posts most of the time before reading and then come back and read it. But if you create 2 accounts and start acting as somoneelse and use an article-spinner, then I will not vote your second account. But I will keep reading you as long as you are not using an article-spinner for all your content. But both accounts, using the same article-spinner is foolishness and greed.
I wonder how these things would play out with SMTs and HF20. One of the biggest accusations @haejin got was a large amount of his voters were using most their votes on him and @ranchorelaxo was exclusively voting @haejin
Many claimed that these accounts were bots while the accounts claimed they came to the platform because of @haejin I do have a problem with exclusively voting one or two accounts. but social media tend to create groups and circlejerk scenarios. This is true with berniesanders followers too.
I checked out some free article-spinners. The texts look a lot similar and I don't think any real readers would miss that. It's something that isn't difficult to be objective about. But Haejin Vs Bernie scenarios or Transisto Vs Writer's Block scenarios are more complex.
There were certain accounts, if I hadn't talked much with those individuals, I could have honestly consider them sock puppets of Haejin.