Dochodzi północ, piątkowy wieczór. Goście już się rozeszli, normalni domownicy śpią. Ja też już mógłbym. Na jutro wszystko dopięte na prawie ostatni guzik. Ale chcę się z Wami czymś podzielić.
Jutro niby zwykła sobota, ale 20 minut będzie wyjątkowe. Po raz pierwszy światło dzienne ujrzy projekt, nad którym z @mwcislo i Szymonem siedzimy od kilku miesięcy.
Światło dzienne, bo dziś w nocy moi drodzy przyjaciele na Hive dowiadujecie się o nim przedpremierowo. Siedzimy nad projektem od kilku miesięcy... bo nie mamy na niego czasu. Jeden z nas siedzi na walizkach, drugi rowerem przemierza Festung Krakau, trzeci próbuje robić karierę i z zapałem konesera rozkoszuje się twórczością Walaszka. To że projekt jest tu gdzie jest, jest najwyraźniej łutem szczęścia.
Z przyjemnością więc Wam o nim opowiem. Zapraszam na blogo-prezentację!

Druga Rzeczpospolita była bardzo barwnym okresem. Intensywnym, pełnym zmian, skandali, afer,napięć, dobrej zabawy i wystawnego życia (*dwa ostatnie dotyczą tylko wybranych). Wśród wielu różnych tematów, które budzą w nas dalej emocje, Rzplita zamuje jedno z ważniejszych miejsc. Dlatego gdy przy którejś rozmowie udało nam się trafić na temat, który możemy przekuć w ciekawy projekt, nawet nie zdziwiło mnie że chodzi o II RP.
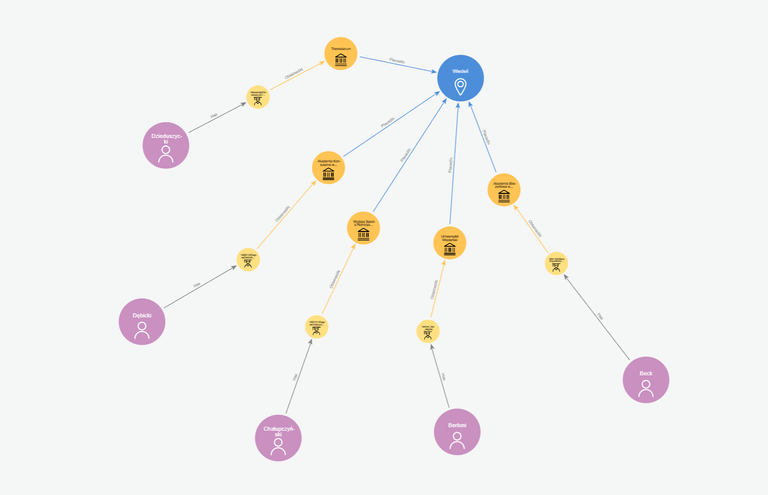
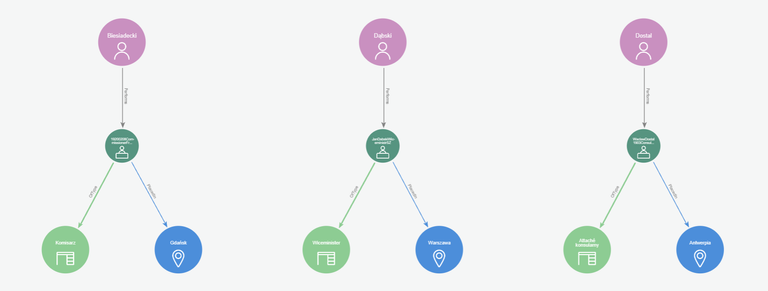
Cel: opracować biogramy polskich dyplomatów, i zweryfikować czy zmiany polityczne (np. zamach majowy) wpływały na obsadę polskich stanowisk dyplomatycznych).
Kilka tygodni olewania tematu, kilka krótkich pchnięć pracy do przodu, i tak oto jutro (w sobotę 11.05) prezentujemy wstępnie nasz projekt na konferencji naukowej, dotyczącej dyplomacji. Nie prezentujemy wyników - od tego jesteśmy za daleko. Jednak już to co do tej pory udało się zrealizować, powinno samo w sobie stanowić ciekawy temat, i wnosić coś nowego w prowadzenie badań nad historią dyplomacji.
Cały projekt zaczął się od marudzenia i wyśmiewania. Jeden z wielu dobrych pomysłów na ciekawy projekt badawczy miał się początkowo realizować w sposób "standardowy", czyli robiąc ręczny przegląd ponad stu biogramów, i robiąc notatki na każdy z tematów. Słysząc o takim podejściu, trochę wyśmiałem "naukę", i rzuciłem hasłem że do tego to trzeba byłoby wykorzystać grafy, a nie ręczne notatki.
I tak właśnie powstał zręb technologiczny. Znam neo4j (grafową bazę danych), i to na niej przygotowałem pierwszy prototyp bazy. Potrzebne notatki wrzuciliśmy na dysk (w tym przypadku OneDrive) i tak się zaczęło.
Szybko okazało się że potrzebujemy czegoś więcej. Danych było sporo, a ręczne zarządzanie nimi nie miało sensu, dlatego uznaliśmy że skorzystamy z okazji, i spróbujemy zbudować trochę oprogramowania które nas wspomoże. Python brzmiał jak to czego potrzebujemy - a ponieważ pracowałem kiedyś z tym językiem, jednak nie za dużo, chętnie do niego wróciłem.
Ponieważ nasz zespół trochę się rozwinął, i było już nas trzech, do tego baza, kod, sporo zadań, uznaliśmy że trochę to uporządkujemy: postawiliśmy projekt w Jirze, gdzie pilnujemy zadań i śledzimy co jest jeszcze potrzebne. Kod jest obecnie przechowywany na repozytorium BitBucket.
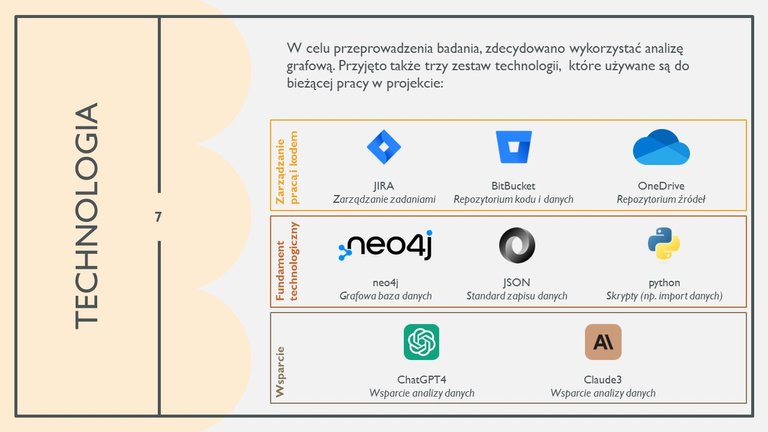
Jak widać w dolnym bloku, korzystamy także z tak modnej generatywnej inteligencji. Możecie się zastanawiać, po co w takim projekcie GenAI? Po pierwsze, to GenAI pomogło mi postawić kod w python. Napisałbym to sam, ale... zajęłoby to o wiele więcej czasu i nerwów. Etap poznawania jak się programuje mam dawno za sobą. Teraz czas na efektywność.
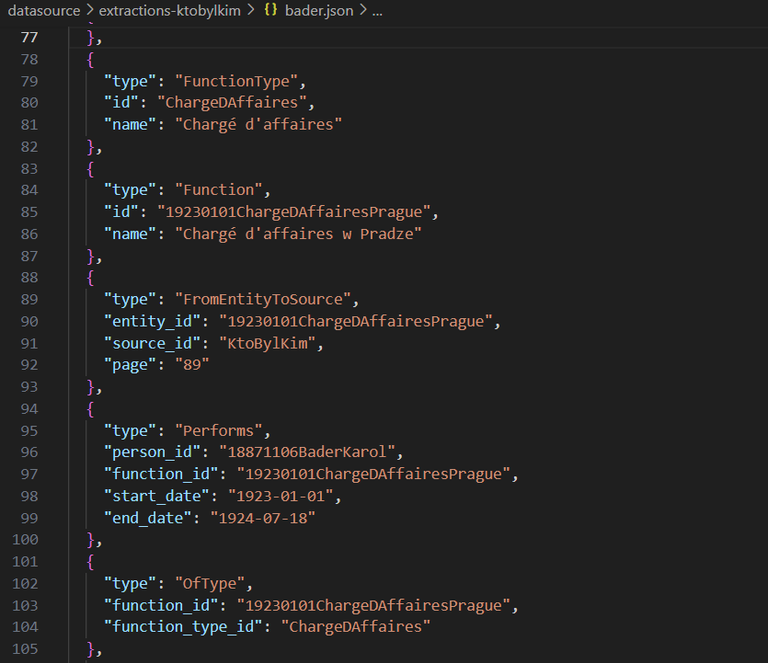
Drugim, i ważniejszym tematem, jest samo przeprowadzanie analizy. Czytanie dziesiątek biogramów żeby wyciągnąć interesujące nas dane byłoby zabójcze. Wyszkoliłem więc GPT aby potrafił dobrze robić jedną konkretną rzecz, czyli mapować biogramy dyplomatów na opracowany przez nas schemat danych. Robi to dobrze, co nie znaczy że idealnie. Dlatego zamiast wykorzystywać dane które zwraca... proszę go o przeanalizowanie tego co wyprodukował i przygotowanie instrukcji dla samego siebie. Instrukcje też nie są idealne, ale po nawet jednorazowym powtórzeniu cyklu poprawkowego, dane są praktycznie gotowe. Czasem do analizy wykorzystuję też inne modele w ramach testów (np. Claude3 Opus i Haiku od Anthropic).

Fundamenty postawione, więc mogliśmy się w końcu zabrać do pracy. Dotychczas udało nam się opracować... 29 biogramów. Dotychczas - bo od postawienia rozwiązania (w szczególności dostosowanego modelu GPT) poświęciłem na projekt około 8-10 godzin.
Mapowanie zaczęliśmy od najbardziej szczupłego słownika biograficznego, i mamy obecnie osoby na litery od A do F. Do końca alfabetu jeszcze sporo... A to nie jest jedyne źródło, z którego chcemy skorzystać (chociaż stanowi minimum wystarczające do pierwszych poważnych wniosków). Jeszcze trochę pracy więc przed nami. Co jednak możemy powiedzieć do tej pory?
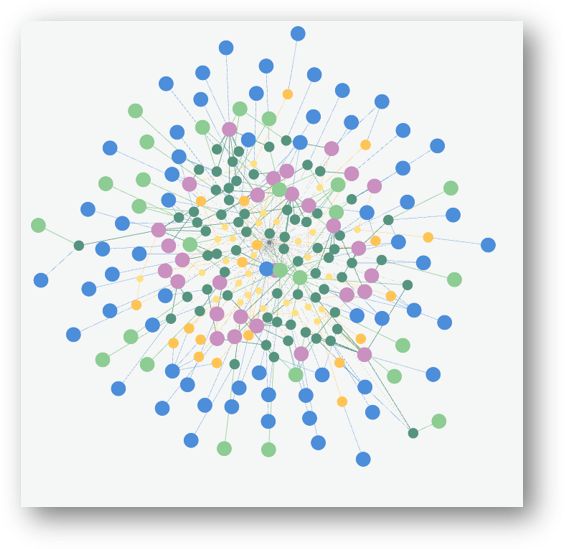
Do przedstawienia biogramów 29 osób potrzebowaliśmy 235 węzłów i 410 relacji. Zebrane razem, tworzą abstrakcyjną, nowoczesną sztukę - portret zbiorowy.

Poprzednio
I kolejny raz, jest to post, którego nie jestem w stanie odruchowo zaklasyfikować. Jeżeli ten post Ci się spodobał, możesz sprawdzić też któryś z moich poprzednich wpisów:
#7 Lean Scouting - czyli szczupłe działanie w gęstym lesie (część pierwsza)
Mówię do czarnego pudełka a ono mi odpowiada - 25/02/'24
W tym sezonie
Poniżej załączam listę tematów, za które chcę się zabrać. Jeżeli któryś Ci się spodobał, daj znać w komentarzu!
- wnioski wychowawcze po moim Camino: po co być obcym (część druga), oraz dlaczego malowniczość jest tak ważna (mam już notatki głosowe, choć okazało się że źle ustawiłem nagrywanie i większość jest niemożliwa do odsłuchania - więc pracuję nad odtworzeniem moich myśli :)
Tematy do których zbieram sie od dłuższego czasu, i na razie jeszcze poczekają:
- Święta Mitologia - rozwinięcie kilku poprzednich postów o cnotach i okazjach do bycia lepszym na przykładach herosów greckich. Etyka Nikomachejska jest już na półce, czeka na swoją kolej
- kontynuacja słowniczka duchowego inżyniera (czeka: barycentrum, propagacja, cybernetyka)
- teologiczna interpretacja czasoprzestrzeni i energomaterii
- szkice rozdziałów książki na bazie mojej wędrówki (tj.: zmuszenie się żebym zaczął w końcu pisać to co powinienem)
- geometria absolutu - czyli jak narysować nieskończoność (do geometrii przejdziemy pewnie po rozbudowaniu Słowniczka, pewne pojęcia mogą się przydać)
Ciekawe. Trochę mi ta graficzna baza danych Obsidiana przypomina.
Nie znałem, więc sprawdziłem - podobne rozwiązanie graficzne, działa na podobnej mechanice linkowania rzeczy ze sobą, jednak neo4j to typowa baza danych - co skonfigurujesz, to dostaniesz. Obsidian natomiast jest o wiele bardziej rozbudowany i ma o wiele więcej funkcji. Chociaż nie zdziwiłbym się jakby jedno miało działać używając drugiego w tle :)
Hello mligeza!
It's nice to let you know that your article will take 11th place.
Your post is among 15 Best articles voted 7 days ago by the @hive-lu | King Lucoin Curator by szejq
You receive 🎖 0.1 unique LUBEST tokens as a reward. You can support Lu world and your curator, then he and you will receive 10x more of the winning token. There is a buyout offer waiting for him on the stock exchange. All you need to do is reblog Daily Report 295 with your winnings.
Buy Lu on the Hive-Engine exchange | World of Lu created by szejq
STOPor to resume write a wordSTART