Hace poco estaba leyendo que ellos usarán f1-score como métrica y pensé, ¿qué es lo que era f1-score?, entonces me puse a buscarlo otra vez. Cuando no tengo familiarizado bien-bien el concepto, éste se olvida rápido; pero la mancha mental queda, y deja la sensación de tener «algo de idea de qué es algo». Ahora bien, como f1-score no va solo, hay otras métricas que también sufren de un problema de no dominación del tema. Es por esto, que me puse a buscar sobre accuracy, precision, recall y f1-score. De esta forma, este post será también una referencia personal para mi yo del futuro (sé que me lo vas a agradecer yo del futuro (al menos que ya recuerdes bien-bien todo)).

Antes que nada, quería deciros que estas métricas son bastantes usadas en el área de la ciencia de datos, o simplemente en aplicaciones de Machine Learning; para problemas de clasificación. Y nos permiten conocer un poco de cómo se está realizando la clasificación, tener en cuenta la cantidad de casos errados y la calidad en general. Pero bueno, muchas personas comienzan buscando cómo otros lo hacen y notan que otros utilizan mucho la accuracy como pauta para mejorar sus clasificadores, y aunque no está mal su uso, no es bueno para todos los tipos de problemas.
Pero bien, ¿en qué se diferencian? En parte, me basé en el contenido de este post ajeno a steemit; y todo comienza con la matriz de confusión.
Matriz de confusión
Ésta es una representación de la calidad de un clasificador, pero es algo visual, tienes que mirarla para entenderla. En la presentación de un trabajo dije:
Para una clasificación ideal, los valores más altos de la matriz deben estar posicionados en la diagonal de ésta.
Ahora veamos cómo se constituye, y por qué la afirmación anterior tiene sentido. Reduciendo un problema de clasificación a sólo dos clases, la matriz sería algo como esta que dibujé:
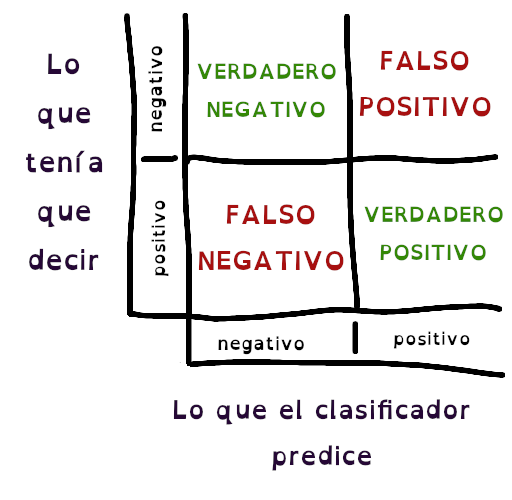
Como dijimos que simplificaríamos la clasificación a dos casos, imaginad que queremos crear un clasificador de imágenes que diferencie entre un Anubis y un Apep. Entonces, el caso positivo será el Apep, queremos identificarlo cuando se nos presenten las dos imágenes. Para esto, nuestro clasificador comienza a clasificar (vaya sorpresa eh), y de las 100 fotos que le proporcionamos, vamos contando teniendo en cuenta la matriz anterior:
- Cuando dijo que era Apep y acertó (verdadero positivo)
- Cuando dijo que era Apep y se equivocó (falso positivo)
- Cuando dijo que NO era Apep y NO lo era (verdadero negativo)
- Cuando dijo que NO era Apep y se equivocó (falso negativo)
Listo, ahora puedes ver que si el clasificador siempre acierta (siendo entonces un clasificador ideal), los valores más altos en el conteo se posicionarían en la diagonal de la matriz, dejando así, el resto en ceros.
Continuando, con los datos en la matriz de confusión se pueden hacer algunos cálculos, y es aquí donde veremos qué pasa con el accuracy, precision, recall y f1-score.
Accuracy
Esta métrica es la más usadas por las personas que comienzan en este mundo de soluciones a clasificación, y más o menos se define como la cantidad de veces que acertaste una afirmación, sobre el total de datos de entrada. Si no me crees, lee aquí entonces pues. Mira la siguiente imagen:
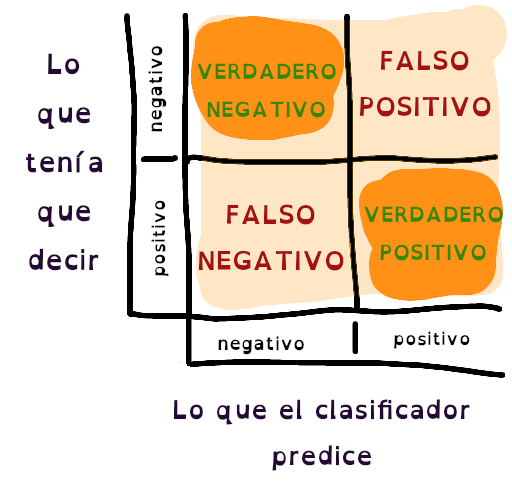
En ésta, se marcaron los casos donde el algoritmo acertó su predicción, sin embargo, y es lo que muchos científicos de datos critican de los que se basan solamente de esta métrica; este valor puede, a veces, parecer alto cuando en verdad la parte relevante no lo es tanto, y es causado por un desbalance en la cantidad de muestras verdaderas y positivas. En este post ponen un ejemplo bastante radical, pero si no quieres entrar a mirarlo, la cosa va así: si tienes 90 casos negativos, y 10 positivos, tu algoritmo (que de hecho, puede hacerse el perezoso) puede tirar todas las predicciones a que «son negativas», y la métrica accuracy quedaría con un valor de 0.9, lo cual es alto 👀. Pero si le vas a preguntar por los 10 que eran casos positivos, el algoritmo te dirá que es negativo y es ahí donde golpeas el talón de Aquiles del accuracy.
Yo podría decir que si tienes un conjunto de datos, para hacer la prueba, balanceado, el resultado es más satisfactorio de lo que pueda aparentar, y así no confundir Apep con Anubis. Pero antes de concluir weás, vamos a ver las otras métricas.
Precision
Esta métrica se define como la cantidad de casos verdaderos positivos sobre la cantidad total de todo lo que dijiste que era positivo. En otras palabras, de todo lo que el algoritmo predijo como positivo, se evalúa cuánto de eso era cierto. Uno de los ejemplos propuesto nuevamente aquí es el de marcar un correo como spam, cuando realmente no lo era. Imagina que un sistema antispam tiene una precision baja y te marca un correo como spam aunque éste no lo es, y terminas no leyendo la invitación a la boda de tu hermana.
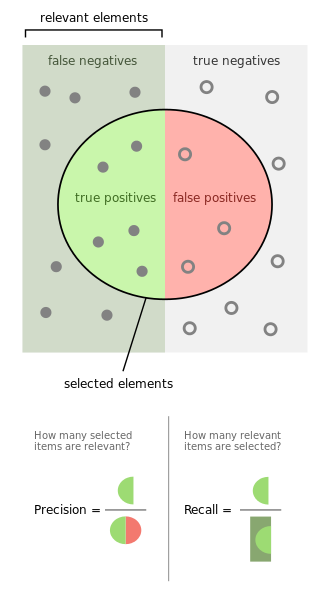
Esta imagen marca los conjuntos de datos seleccionados a la hora de calcular la precision.
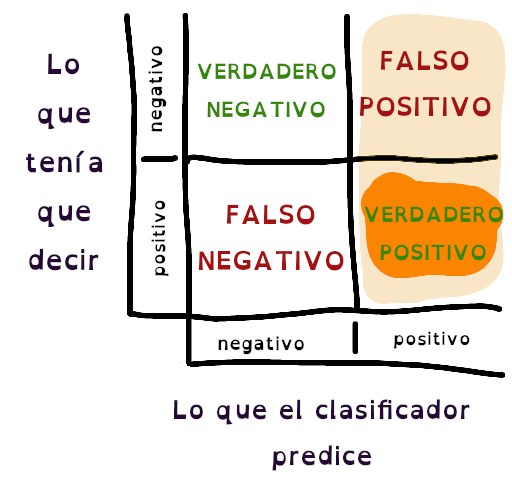
En ese color que parece naranja, se marca lo que de verdad era positivo; y en un color más claro, está marcada la columna de todo lo que el clasificador dijo que era positivo, incluyendo obviamente, los casos de falso positivo.
Uno de los casos donde se puede usar esta métrica, según el post de arriba, es cuando la cantidad de falsos positivos tiene una repercusión muy importante. Imagina un clasificador que confunde una diagnóstico y terminas amputándole la pierna sana a un paciente.
Recall
Por otro lado, está esta otra métrica con un enfoque diferente. Se compara la cantidad de casos clasificados como verdaderos positivos sobre todo lo que realmente era positivo. Y a diferencia de la anterior (precision), antes comparábamos lo que el algoritmo dice con lo que es cierto, en cambio acá, lo que él dice contra lo que no dijo que era cierto. Quizás con el ejemplo publicado otra vez por estos señores, pueda quedar claro; donde pone qué pasaría si un clasificador deja de decir que hay un caso de fraude. También, volviendo al tema de salud, imagina un algoritmo que no dice que una persona está contagiada de algún virus, y en verdad si lo está. Entonces, para estos casos, donde se busca reducir el número de falsos negativos, el recall es utilizado; así si necesitas elegir todos los Apep, no dejaras uno por fuera.
Esta imagen muestra los conjuntos de datos de la matriz que participan en el cálculo del recall.
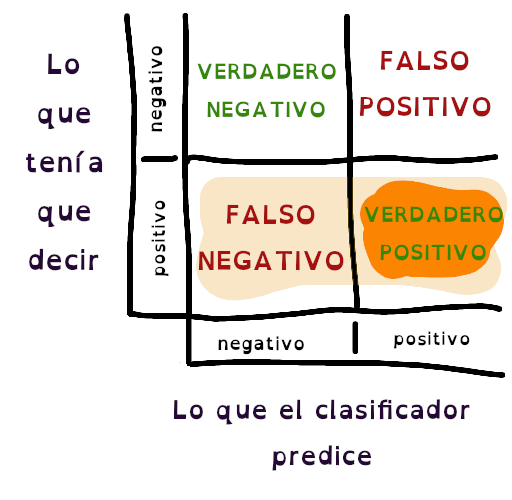
Lo mismo que la anterior, pero direfente. Lo naranja son los casos predichos como positivo, pero en esta ocasión, comparamos frente a los datos que no fueron marcados como positivos.
F1-score
Y el último, el más variopinto. A juzgar por lo que finalmente explican en este post, si necesitas mantenerte lejos de falsos positivos y falsos negativos, f1-score es para ti. Ya con su buen balance entre las dos métricas anteriores (precision y recall), puedes optimizar tus clasificadores sin verse éste afectado porque no supiste crear un conjunto de datos balanceado.
Entonces f1-score sería el doble del producto de precision y recall sobre la suma de estos dos. El otro día encontré una imagen que explica cómo funciona, la cual podría explicar si tenemos en cuenta un espacio en tres dimensiones, donde X y Y son precision y recall, y el eje Z representa f1-score. Cuando los valores de precision y recall eran más cercanos a uno, mutuamente, el valor de f1-score era más alto, como si de un octavo de esfera se tratase.
Y bueno...
Ya para dejaros los mismos posts que igualmente están arriba, de una forma más ordenada:
Prefacio de aprendizaje automático en máquinas
How can I calculate the accuracy?
Precisión y recuperación (Precision and recall)
Accuracy, Precision, Recall or F1?
Esta publicación también amplía sobre F1-score, y de paso deja esta imagen interesante:
Finalmente, quería decir que la elección de cada una de las métricas (o el conjunto de éstas), depende mucho del problema a resolver. No es ir a la ligera y tomar cualquiera, depende tanto de los datos de entrada en tu clasificador, como lo que quieres optimizar con más importancia. Se me escapaba decir que si queréis ver las fórmulas, en Accuracy, Precision, Recall or F1? la ponen muy visible. También, recordad que los rangos de estas métricas van de cero a uno.

Hay otras métricas además de éstas, pero como éstas son las más famosas importantes, pues las elegí; además dije que esto era también una referencia personal. Si te sirve, espero que crees buenos clasificadores.

Envíanos un mensaje en Discord 😍🤗❤
https://discord.gg/vzHFNd6