Repository
https://github.com/Juless89/steem-dashboard
Website
Still in beta, the data can be incomplete and the website may be laggy as blocks are being processed!
New Project
What is the project about?
SteemChain in an open source application to analyse transactions and operations from the STEEM blockchain. Store these into a MySQL database and visualise with charts and tables via the web. Looking to bring data analytics to STEEM like websites as blockchain.com do for Bitcoin.
Technology Stack
- Django Framework - The web framework used
- Django REST Framework - The REST framework used
- Bootstrap - HTML/CSS Framework
- Charts.js - Javascript charts library
- MySQL - Database
Roadmap
back-end
- Create a parent class for each operation to inherit from, expand to all operation types and allow for flexibility between different operation types.
- Create dynamic MySQL queries to allow for additional data to be stored for certain specific operation types
- Store account history values like: total transfers, amounts transferred etc
- Add additional analytics for each operation type
front-end
- Overview of all operation types and changes for specific time periods
- Replace Charts.js with a javascript library that allows for zoom charts
- Account dashboard
additional
- Write api docs
v1.0.0
For this initial release the purpose was to build a foundation to expand from. This release can be split into three different segments.
Webpage
The webpage is build from a bootstrap theme on a django framework and for now is using Charts.js for creating the charts. Cookies are set to store which parameters were last used by the user. This allows for switching between different operation types while retaining the same resolution and period. jQuery is used to pull data from the server via an api.
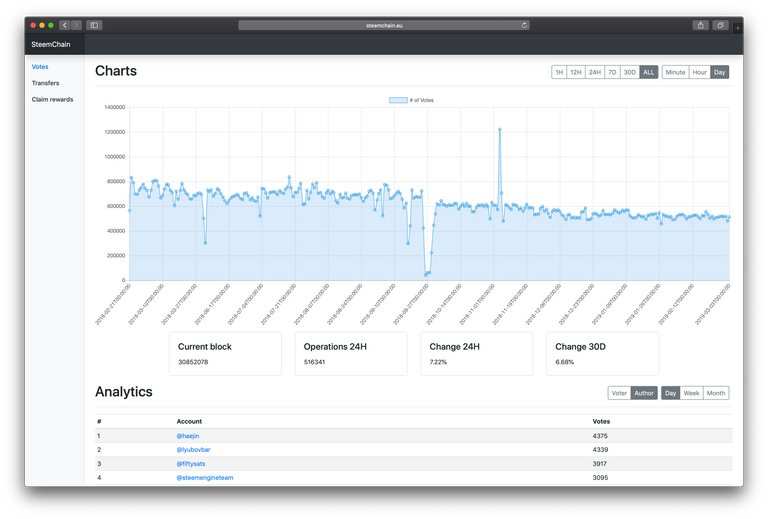
REST api
The api allows for a second way to access all data. Developers can use the api to access the data directly for their own applications. The api is build on the Django REST api framework. All data displayed on the website is pulled via an API.
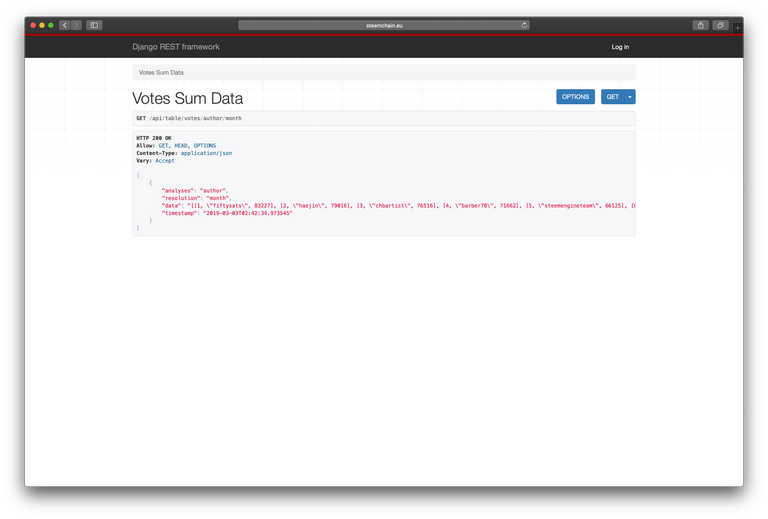
Back-end
A custom made multi threaded block chain scraper was built for this project to retrieve blocks in order, sort and store the data into a database. Synchronised worker threads retrieve new blocks as long as difference in blocks retrieved between them is not greater than 5. All blocks are put into a queue waiting for sorting.
The sorter removes the blocks from the queue and stores them in a sorted buffer if they are not the current block number until their number is reached by the processing thread. The processing thread extracts all transactions and operations from the block, as well as the timestamp and block number. Operations get send to individual thread that are set up to do all processing related to that specific operation type.
This allows for a lot of freedom in different analytics with regard to different operation types without slowing down other threads. Depending on the mode (scraping/head) data is stored immediately into the database or hold up in buffers to insert less frequently to offload the mysql instance when processing many blocks.
During scraping there is a lot of load on the CPU. In head more the load to stay in sync with the chain is minimal, which allows for analytics to be run instead.
How to contribute?
The project is on GitHub so you can fork the project and submit a pull request, you can also contact met on Discord @juliank.
Looks like a good start.
The application runs on
DEBUG=Trueon production. It may be good to set debug flag as False.Would be good to have examples of API endpoints. DRF has an auto documentation generator with coreapi. You can get a nice documentation in seconds. I have used it a couple of times. Have a look when you find time.
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Chat with us on Discord.
[utopian-moderator]
Thanks @emrebeyler for your constructive advice as always. Will look into it.
Thank you for your review, @emrebeyler! Keep up the good work!
Hey, thanks for your work!
I will definitely explore your tutorials!
Hi @steempytutorials!
Your post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation!
Your post is eligible for our upvote, thanks to our collaboration with @utopian-io!
Feel free to join our @steem-ua Discord server
Hey, @steempytutorials!
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via SteemPlus or Steeditor).
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!
Congratulations @steempytutorials! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
Click here to view your Board
If you no longer want to receive notifications, reply to this comment with the word
STOPVote for @Steemitboard as a witness and get one more award and increased upvotes!