Open data turns public information into shared infrastructure.
But shared infrastructure needs a home.
And for an open data layer to work, that place has to be neutral and scalable.
No company should control it.
No platform should decide who is allowed to participate.
That is why blockchain matters.
A blockchain is permissionless: no one needs approval to publish or access data.
It is transparent: everyone can inspect the same public record.
And it is verifiable: authorship, timestamps, and updates can be checked independently.
No single authority controls the system.
No platform decides which builders are allowed to participate.
No company can quietly cut off access to the shared foundation others depend on.
That gives every participant — apps, communities, businesses, developers, and AI agents — the confidence to build on the open data layer without fear that the ground beneath them will suddenly be taken away.
But not every blockchain is suited for this role.
An open data layer is not just a ledger for occasional financial transactions.
It needs to support frequent publishing, constant updates, many users, and large volumes of structured information.
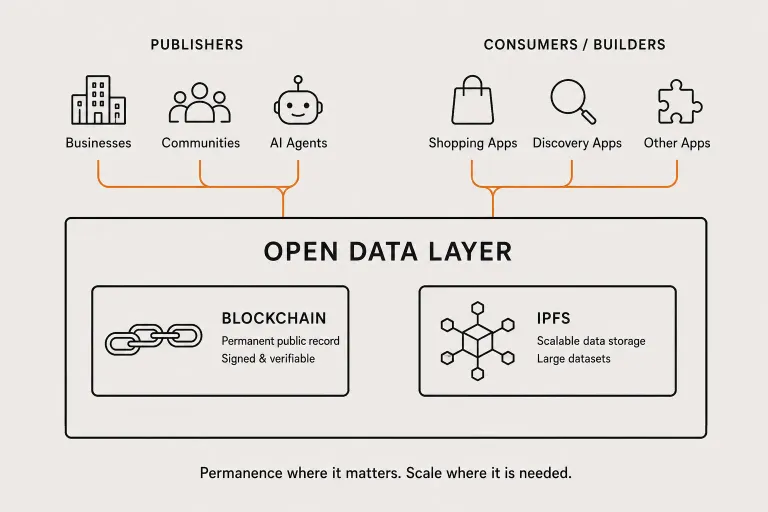
This is where Hive becomes especially relevant.
Hive was designed as an open social blockchain.
From the beginning, it had to support activity at social scale: posts, comments, votes, follows, profile updates, and financial transactions.
These are frequent interactions happening across many users.
With three-second block times and generous block capacity — up to 2MB per block — Hive provides a practical foundation for this kind of activity.
Its resource credit system also keeps most transactions effectively free for users with sufficient Hive Power, while still limiting abuse of the network.
And beyond social content, Hive supports direct publishing of structured JSON data to the blockchain.
That makes it a strong candidate for hosting an open data layer.
But how much open data can Hive actually carry?
Let’s take a simple example: product records.
A typical product record can be represented as a structured JSON object of roughly 8KB.
Under this assumption, a user could publish about five such JSON records per block.
Hive produces one block every three seconds.
That gives us 28,800 blocks per day.
At five product records per block:
28,800 × 5 = 144,000 product records per day
That is impressive.
A single account could theoretically publish around 144,000 product records per day.
Multiple accounts could publish even more.
For most online businesses posting product updates, menu changes, and schedule edits, that is already more than enough.
But it is still finite.
And more importantly, it is not free in practice.
Hive uses resource credits, which means publishing capacity depends on available network resources and account stake, or Hive Power.
As activity increases, resource usage becomes more expensive.
So while the blockchain is excellent for permanent, signed, verifiable records, it is not the right place to push unlimited bulk data.
Now imagine publishing information about 100 million products.
Even with Hive’s generous capacity, blockchain space is still finite.
At 144,000 product records per day, publishing that volume would take about 694 days from a single account.
Almost two years of continuous publishing.
This is where IPFS can offer a solution.
IPFS, or the InterPlanetary File System, is a distributed file storage network.
Instead of storing data in one company’s database or on one centralized server, IPFS allows files to be shared across a distributed network and identified by their content.
When a user publishes a file to IPFS, the network generates a unique content hash for that file.
This hash works like a fingerprint.
If the file changes, the hash will no longer match.
That means the hash does not merely point to a location.
It identifies the exact content itself.
For an open data layer, this is important.
A user can publish a large dataset — for example, a massive product catalog — to IPFS.
Then the user can publish the IPFS hash to the blockchain and sign it with their keys.
The blockchain record becomes the permanent public reference.
It shows who published the dataset, when it was published, and which exact IPFS file was being referenced.
Anyone can later retrieve the file from IPFS and verify that it matches the hash recorded on-chain.
From there, applications can decide whether to index and use the structured data based on their trust in the publisher.
IPFS provides the scale.
The blockchain provides the permanent public reference.
But this comes with an important trade-off.
IPFS is distributed, but it is not inherently permanent in the same way a blockchain record is.
For a file to remain reliably available, it must be pinned.
That means someone — the publisher, a service provider, a community, or a project — must continue hosting or preserving that file.
This does not make IPFS a replacement for the blockchain.
It makes IPFS a companion layer.
So the architecture becomes hybrid.
Different kinds of data have different needs.
The blockchain is used where permanence matters most.
IPFS is used where volume, speed, and cost matter more.
Together, they make the open data layer practical.
Not everything needs to be stored permanently on-chain.
That is the balance.
Permanence where it matters.
Scale where it is needed.
Still early!
What's hard for humans is easy for AI agents 😎