
Moinsen,
in meinen folgenden Posts dreht sich alles um das Thema IPFS. Wir werden uns gemeinsam mit der Theorie und dem Aufsetzen eines IPFS-Nodes auseinandersetzen (dieser Post), um dann in den folgenden Parts mehr über die einzelnen Funktionen und das richtige Nutzen von IPFS zu erfahren.
Es ist notwendig, die Eingabeaufforderung/das Terminal zu nutzen, jedoch setze ich keine besonderen IT-Kenntnisse vorraus. IPFS ist nicht nur für Sys-Admins 😉
Alle IPFS-Befehle sind betriebssystemunabhängig; ich zeige den Betrieb von IPFS als Beispiel auf einem Windowscomputer.
Nichtsdestotrotz gibt es natürlich auch graphische Lösungen, welche aber aktuell (Feb 2018) meiner Meinung nach nicht ordentlich funktionieren. Trotzdem werde ich auch darauf hinweisen.
Zum Abschluss des Vorwortes möchte ich dazu ermutigen, unter diesem Post gerne Feedback, Fragen und Stoff zum Diskutieren dazulassen. Ich wünsche viel Vergnügen und vor allem viel neues Wissen über das InterPlanetary File System.
Das interplanetare Dateisystem
... oder auch InterPlanetary File System, kurz IPFS, ist zum einen ein Protokoll, zum anderen ein dezentrales Netzwerk zum Dateiaustausch zwischen Computern.
Computer können verschiedene Wege nutzen, um Dateien über das Internet zu senden und zu empfangen, bspw. FTP oder HTTP. Besonders letzteres ist für unseren täglichen Gebrauch essenziell. Du liest diesen Satz dank HTTP. Doch das Hypertext Transfer Protocol ist ineffizient. Laut den IPFS-Entwicklern besteht eine normale Website durchschnittlich nur 100 Tage. Danach wird sie entweder gelöscht oder so bearbeitet, dass sie nicht mehr dem Originalen gleicht. Gleichzeitig ist eine andere Komponente äußerst wichtig: DNS-Server sorgen dafür, dass unser Computer immer weiß, welche Domain (bspw. steemit.com) welcher IP zugeordnet ist (bspw. 34.239.36.39). Sollten diese ausfallen, ist es nicht mehr möglich, Steemit aufzurufen, da der Computer die IP-Adresse nicht kennt.
Keine Sorge, praktisch müsste schon echt viel schiefgehen, damit Steemit nicht mehr erreichbar ist, jedoch ist es keine Unmöglichkeit.
Die Lösung nennt sich IPFS. Dieses Netzwerk setzt komplett auf das sogenannte dezentrale Peer-to-peer System. Auf Deutsch bedeutet dies, dass nicht jeder Rechner immer auf den selben Server zugreift (siehe die IP von vorhin), sondern sich die Daten untereinander austauschen (wie z.B. ein Kettenbrief).

Quelle: ipfs.io | Links ein Server, welcher HTTP-Anfragen erhält und ausliefert, rechts IPFS mit Peer-to-peer.
So wird auch bis zu 60% an Datentraffic (und indirekt auch an Strom) gespart.
Von Nodes, Gateways und Daemons
Eine zentrale Rolle im IPFS übernehmen die sog. Nodes. Diese bilden das Grundgerüst, verbinden sich untereinander und tauschen Daten aus. Ohne diese würde das IPFS gar nicht existieren. Ein Node kann von jedem betrieben werden; darum wird sich auch diese Tutorialstrecke zum Großteil drehen.
Indem du ein Node betreibst, hilfst du dem IPFS-Netzwerk zu bestehen.
Und wenn du dich jetzt vielleicht fragst, wer denn bitteschön überhaupt IPFS nutzt, schau dir mal D.Tube oder auch DSound an. Ohne IPFS wäre deren Infrastruktur hoffnungslos überfordert. Durch das Verbreiten der Videos über Nodes werden die Server von D.Tube, DSound u.ä. entlastet und können zuverlässig laufen.
Große Nodes können als globale Gateways fungieren. Das wohl bekannteste Beispiel ist die IPFS-Website (ipfs.io/ipfs bzw. gateway.ipfs.io/ipfs). Diese Gateways sind für die Nutzer gedacht, die selbst keinen Node betreiben, um einen Zugang zum IPFS zu erhalten. Solche Gateways nutzt du normalerweise, wenn du z.B. ein Video über D.Tube schaust. Dein Computer fragt das Gateway, ob es diese Datei ausliefern kann und bekommt es über normales HTTP zur Verfügung gestellt.
Um eine Datei ohne HTTP-Request zu erhalten, muss auf deinem Computer der sog. Daemon laufen. Dieser sucht zum einen für dich nach Dateien im IPFS-Netzwerk, zum anderen stellt er auch die Dateien, die auf deinem Computer liegen, zur Verfügung.
Alle Dateien müssen im Netzwerk erkennbar bleiben. Dafür nutzt IPFS die Hashes. Hashes sind inhaltsabhängige Indikatoren für eine Datei, die von einem IPFS-Node angeboten wird. "Inhaltsabhängig" bedeutet, dass die Datei, egal welchen Dateinamen sie besitzt, immer den selben Hash hat, sofern der Inhalt gleich ist. Wenn du über ein Gateway den Hash QmTfmNRXLvq5eirEDSt5U3ttmpzKiFfJoYseRyD1qhyF8L aufrufst, wirst du immer das selbe Ergebnis vorfinden. Im Originalen heißt die Datei ibims.txt. Im Endeffekt kannst du aber eine steemistbeschte.txt mit dem selben Inhalt erstellen, der Hash bleibt gleich. Dies beugt auch Plagiaten vor 👍
Das IPFS-1x1 - Wie funktioniert eine Abfrage?
Wie nun aber kommt das Gateway zu meiner ibims.txt? Ich habe dem Gateway nie gesagt: "Huhu, guck mal, da liegt eine tolle Datei auf meinem Rechner mit dieser und jener IP-Adresse". Deshalb möchte ich dir hier fix offenlegen, wie so ein Abruf bei dir lokal abläuft.
- Nachdem du über Kommandozeile oder lokalem Gateway ein Hash angefordert hast, sucht der Daemon zunächst lokal nach dem Hash.
- Hat er diesen nicht gefunden, beginnt er die nächstgelegenen Nodes, mit denen er verbunden ist, via Peer-to-peer anzufragen, ob sie den Hash kennen.
- Sollte dies nicht der Fall sein, fragt der Daemon in einem größerem Umkreis nochmal.
- Das macht er so lange, bis ein Node entweder durch Meta-Daten weiß, welcher Node diesen Hash resolven (lösen=kennen) kann oder diesen selbst gespeichert hat.
- Der Node schickt deinem Node den Inhalt des Hashes.
Weiterhin können auch noch mehrere Teile zu einem Hash gehören, das ist aber ein Thema für später.
Dein Node speichert nun den Inhalt und stellt diesen ebenfalls zur Verfügung. Sollte also ein andere Node deinen Node fragen, ob er die Datei hat, kann dein Node sie ausliefern (genaueres ebenfalls später).
Puh, ganz schön viel Theorie, nicht? Keine Sorge, in den folgenden Parts werden wir alles an Beispielen praktizieren. Damit du aber in Zukunft gleich mitprobieren kannst, will ich dir im letzten Abschnitt erklären, wie du deinen eigenen Node einrichten kannst (und du kannst gleich mitmachen).
DIY-Blog | Heute: IPFS-Node einrichten
- Erstelle dir auf deiner Festplatte einen Ordner deiner Wahl (für die komplette Tutorialreihe nutze ich den Ordner IPFS/go-ipfs auf der J: Partition (nur, damit du die Screenshots auch richtig verstehst). Der Ordner sollte am besten auf der obersten Ebene (also direkt J: o.ä.) liegen, damit wir später einfacher mit der Konsole zum Ordner navigieren können.
- Öffne in deinem Webbrowser ipfs.io/docs/install
- Klicke auf den Downloadbutton.
- Der Webserver sollte dein System automatisch erkennen. Wenn nicht, wähle dein System in der Tabelle unten aus.
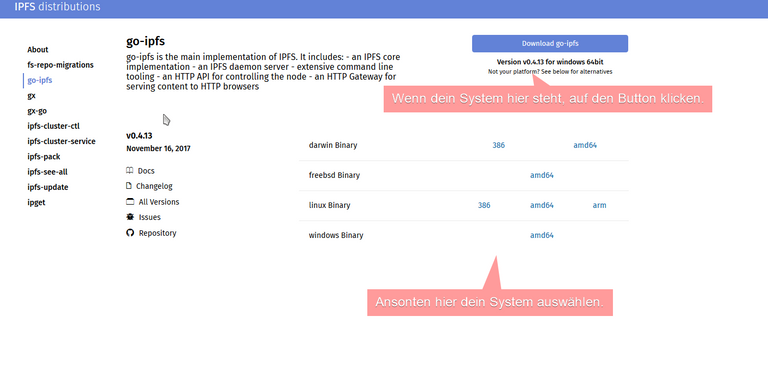
- Downloade dir das Archiv und entpacke es in den IPFS-Ordner aus Schritt 1.
- Öffne nun deine Kommandozeile
- Windows: Windowstaste drücken ->
cmdeingeben - Linux: Strg+Alt+T drücken
- Mac: Command + Leertaste -> Terminal eingeben.
- Zum Ordner navigieren. Dies ist je nach Betriebssystem unterschiedlich. In Windows machst du dies mit dem
cd DER/PFAD/ZU/IPFSBefehl. Wenn du ein anderes OS und Probleme hast, frag einfach in den Kommentaren. - Nun zum Test erstmal nur
ipfseingeben und mit Enter abschicken. Wenn du nun eine Auflistung von Befehlen siehst, bist du schonmal richtig. - Nun mit
ipfs initden Node initialisieren (u.U. ist das vorherige Ausführen der install.sh nötig, bei Windows nicht). - Et voilà. In fast 10 Schritten bist du nun stolzer Besitzer eines Nodes mit der entsprechenden ID.
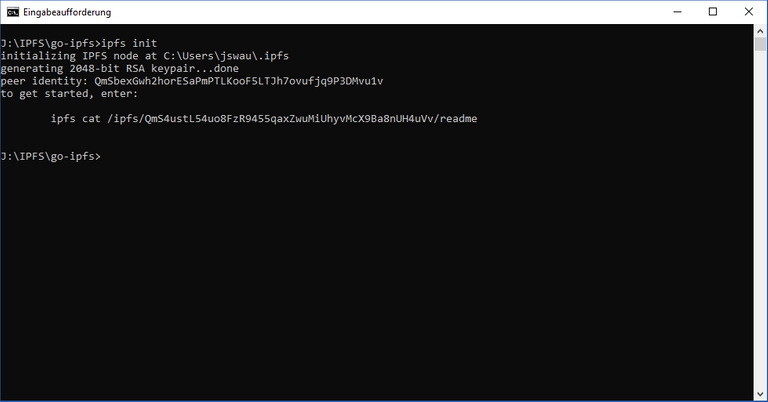
Ich empfehle dir, eine Datei (ganz normale Textdatei) anzulegen, in welcher du wichtige Hashes und Node-IDs abspeicherst. So läufst du nie Gefahr, dass etwas verloren geht.
Um nun den Daemon zu starten und somit das Netzwerk "zu betreten" nutzt du einfach den Befehl ipfs daemon. Der Daemon startet nun und steht dir zur Verfügung. Da wir ihn aber aktuell nicht benötigen, kannst du ihn mit Strg/Control+C vorerst wieder beenden.
Damit in den folgenden Teilen auch alle Demonstrationen so klappen, wie sie sollen, lege ich dir nahe, das IPFS-Companion-Plugin für Chrome und Firefox zu installieren. Dies leitet z.B. alle IPFS-Anfragen von deinem Browser auf deinen lokalen Node um.
Alles klar, damit hast du die Grundlage für die IPFS-Tutorialreihe geschaffen.
Ich versuche, mit den Tutorials Menschen (nicht nur Steemians), auch wenn es "nur" die passive Nutzung ist, an IPFS heranzuführen, da dies in meinen Augen ein guter Weg zum nachhaltigen Web ist. Deshalb ist diese Tutorialreihe unter der CC BY 4.0 veröffentlicht. Du darfst diesen Beitrag gerne weiterverbreiten, auch außerhalb Steems und diesen in gewissen Maßen verändern. Wichtig ist, dass immer mein Name und dieser Post als Quelle angegeben ist.
Im nächsten Tutorial schauen wir uns an, wie wir Dateien lokal abrufen können und unsere eigenen ins IPFS bringen können.
Vielen Dank an @lovelyphotograph für das Korrekturlesen 👍
Bis dahin!
BB,
JanSe
Funfact: Wusstest du, dass der komplette Mediabestand des Chaos Computer Club schon seit Januar 2016 unter dem Hash QmW84mqTYnCkRTy6VeRJebPWuuk8b27PJ4bWm2bL4nrEWbim IPFS zu finden ist? Soviel zum Thema, dass IPFS kaum genutzt wird 😱

.
Zu erst mal: cooler post, hat viele Fragen die ich hatte geklärt (@sempervideo hat da ja noch einige Fragen offen gelassen).
Ich hab aber dennoch ein paar fragen:
Ok ich hoffe ich habe mich verständlich genug ausgedrückt und erschlage dich nicht mit all meinen Fragen. Es würde mich also freuen wenn ich zu mindest zu ein paar dieser Themen Erleuchtung fände.
Danke im Vorraus
Moinsen,
vielen Dank für den Kommentar. Deine Fragen versuche ich mal zu beantworten.
Ich hoffe, ich konnte deine Fragen beantworten.
BB,
JanSe
ja vielen dank ... hat sehr geholfen und ich freu mich auf die nächsten Teile
Hallo @janse, herzlich willkommen auf Steemit.
Wenn Du Fragen zu Steemit hast, oder Dich mit anderen deutschen „Steemians“ austauschen magst, schau einfach mal auf unserem Discord-Server https://discord.gg/g6ktN45 vorbei.
Unter dem folgenden Link findest Du einige Anleitungen, die Dir den Einstieg in das Steem-Universum deutlich erleichtern werden: Deutschsprachige Tutorials für Steemit-Neulinge: Ein Überblick
Ich stelle mir dann die Frage, wenn die Daten auf "ewig" gespeichert bleiben sollen, warum dann einige Videos auf d.tube nach einigen Tagen nicht mehr abrufbar sind.
Moinsen,
Es gibt aktuell anscheinend einige Probleme mit D.Tube und eigenen Videohashes. Inwieweit das mit D.Tube direkt zusammenhängt, kann ich nicht abschätzen.
Eine Möglichkeit wäre, dass der Node, welcher das Video anbietet, nicht mehr online ist und das Video auf keinem anderem liegt. Somit gäbe es keine Möglichkeit, zu resolven. Das IPFS.IO-Gateway führt von Zeit zu Zeit den sog. Garbage Collector aus, um Speicherplatz freizugeben. Dabei kann auch das Video gelöscht werden. Das ist für Teil 3 geplant.
BB,
JanSe
Hi @janse
Danke für die Anleitung, hat bei mir soweit geklappt.
Allerdings, wenn ich den daemon starten möchte (ich nutze Windows 10), erhalte ich die Meldung;
initializing daemon
Error: file missing [file=MANIFEST-000000]
in cmd.
Google suche konnte mir nicht weiterhelfen, ich hoffe du kannst es.
Was kann ich in dem Fall tun?
Vielen Dank im voraus
Moinsen,
schau mal im IPFS-Repopfad unter datastore nach, ob dort eine MANIFEST-XXX liegt. Der Pfad ist der, welcher beim Initialisieren angezeigt wurde. Je nachdem, mit welchem OS du unterwegs bist, findest du den Pfad bei
~\.ipfs(also in Windows z.B.C:\Benutzer\BENAUTZERNAME\.ipfs).Sollte dort eine Datei sein, die nicht so benannt ist, wie in der Fehlermeldung kannst du (auf eigene Gefahr) probieren, sie umzubennen. Da mir der Fehler bis eben nicht bekannt ist, weiß ich nicht, ob das hilft.
Wenn nicht, einfach den Ordner ./ipfs löschen und neu initialisieren.
BB,
JanSe