在之前的帖子中和大家一起学习了如何使用Python获取指定区块在block_log中的位置信息,今天我们来实际测试一下利用上述信息修复被损坏的block_log,并测试不同情况的replay(重播)。

(图源 :pixabay)
为了进行测试,我们首先关闭hived,并复制block_log以及block_log.index到新用户目录下,这样就算不小心搞坏,也不会影响我hived的正常运行。
尽管是在本地操作,但是因为block_log已经达到了500G以上,所以耗费了大概一个小时左右的时间,还真的需要点耐心呢。
复制后,两个文件长度信息如下:
-rw-rw-r-- 1 test1234 test1234 536100860926 Feb 5 14:55 block_log
-rw-rw-r-- 1 test1234 test1234 492444336 Feb 5 14:55 block_log.index
测试直接启动hived
我们尝试直接启动hived,发现hived是无法正常启动的,因为缺少shared_memory.bin数据。
Reveal spoiler

其中最有价值的提示信息:
check_data_consisten ] Replaying is not finished. Synchronization is not allowed. { "block_log-head": 61555542, "state-head": 0 }
我们也可以根据block_log.index长度计算出当前区块号:
Reveal spoiler

测试replay (重播)
因为block_log以及block_log.index当前都是完好的,并且区块高度相同。当前情况下我们是可以通过--replay-blockchain来对区块链进行replay操作,重建state database。
指令如下:
hived_v1.25.0 --replay-blockchain
执行后正常开始replay:
Reveal spoiler

测试block_log损毁情况
首先人为模拟破坏block_log,删除其尾部的六个字节:
truncate -s 536100860920 block_log
然后重新执行repaly操作:
hived_v1.25.0 --replay-blockchain
我们会发现这个replay操作是无法进行的
Reveal spoiler
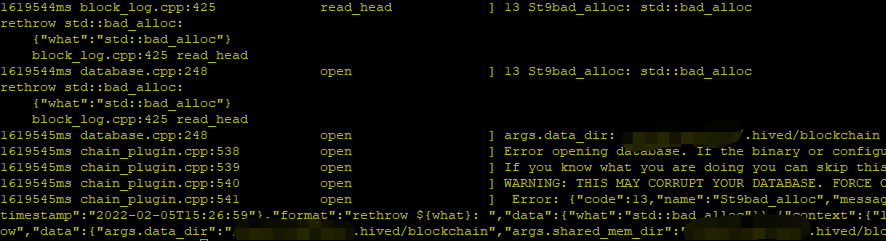
这和我们日常遇到的大多数block_log损毁一样,当尾部被破坏时(应该是写入没写完整时hived被强制停掉等情况所导致),无法进行replay操作。
测试区块高度不一致的情况
测试block_pos < index_pos
通过之前文章中提供的脚本,我们计算出最后一块的位置:536100838940,然后将其截掉:
truncate -s 536100838940 block_log
(通过最后一块的位置,以及block_log未损坏时的长度,可以计算出最后一块在block_log中的存储长度)。
经过这个操作之后,我们可以认为block_log以及block_log.index都是完好的,只是block_log.index比block_log块高高了一块。
我们再来试试replay,(在进行操作之前,首先备份一下block_log.index)。
hived_v1.25.0 --replay-blockchain
以下为执行结果,注意其中的block_pos < index_pos,然后从头开始漫长的Reconstructing Block Log Index using memory-mapped IO:
Reveal spoiler

测试block_pos > index_pos
将block_log.index截掉16个字节后再次尝试replay:
hived_v1.25.0 --replay-blockchain
以下为测试结果,注意其中的Index is incomplete,又是漫长的从头开始Reconstructing Block Log Index using memory-mapped IO:
Reveal spoiler

测试没有block_log.index
彻底删除block_log.index后,再次尝试replay:
hived_v1.25.0 --replay-blockchain
以下为测试结果,注意其中的Index is empty,之后又是漫长的Reconstructing Block Log Index using memory-mapped IO:

也就是说区块高度不一致,或者block_log.index不存在的情况都要进行Reconstructing Block Log Index using memory-mapped IO。
如果block_log.index不存在彻底不存在,其实重建index是没问题的,而高度不一致的情况重建index会白白浪费大量的时间。所以高度不一致的情况,应该首先考虑修复,然后再replay。
修复&replay
修复block_log以及block_log.index其实很简单,就是通过block_log.index最后一块,计算出最后一块在block_log中的位置,并且截短block_log以及block_log.index对应内容。
如果一块不行,就多截短几块,对于block_log.index而言,截掉对应块数*8个字节就好。
修复block_log并使block_log.index与其块高一致,就可以尝试replay了:
hived_v1.25.0 --replay-blockchain
这时我们会看到replay正常进行,没有进行重建index,无疑节省了大量时间:
Reveal spoiler

结论
我们可以通过计算block_log.index中后边某块在block_log中的位置并配合truncate工具来修复block_log;同时可以使用truncate移除指定块数*8字节来使block_log与block_log.index块高相同。
这样就实现了彻底修复的目的,而不必因为块高不同导致强行重建index(Reconstructing Block Log Index using memory-mapped IO),进而节省了大量的时间。

(图源 :pixabay)
好了,今天就学习到这里了。
Your content has been voted as a part of Encouragement program. Keep up the good work!
Use Ecency daily to boost your growth on platform!
Support Ecency
Vote for new Proposal
Delegate HP and earn more
O哥优秀,也许有个好师傅不一定有个好徒弟,学习也不一定让人进步,拜读完,我似乎有了如此感悟🤪。哈哈
爱胸能看懂这些开源😅
脑回路不行
看得头晕乎乎的,除了看不懂之外就剩下看不懂了。
O哥真厉害👍而且是复制不了的优势!
分好几段,看完了。好费脑,未来世界不懂代码就如不会开车、不会“文字/语言”