Introduction
Over the past few weeks, I stumbled upon a great way to access and analyze Hive blockchain data without needing to run my own node or deal with slow complex API calls. Enter HiveSQL—a powerful tool that lets you query Hive data like a pro!
In this blog, I'll walk you through the basics of setting up HiveSQL and using Python to extract useful data. If you've ever wanted to dive deeper into Hive's data, create custom analytics, or just explore what's happening on the blockchain, you're in the right place.
Prerequisites
Before we get started, you'll need:
✅ Some basic Python knowledge
✅ A HiveSQL account (I'll show you how to get one)
✅ A bit of patience for the setup—trust me, it’s worth it!
What is HiveSQL?
HiveSQL is a publicly available Microsoft SQL Server database that stores Hive blockchain data in a structured and easily accessible way. Instead of running your own Hive node or scraping data from public APIs, you can use SQL queries to quickly retrieve the information you need.
Why use HiveSQL?
✔ Faster queries – No need to download blockchain data manually
✔ Easy access – Works with any tool that can connect to an MS-SQL database
✔ Powerful analysis – Great for running reports, tracking trends, and finding valuable insights
Rather than making countless API calls, you simply send an SQL query to the HiveSQL server and get back exactly the data you need—fast and efficient!
➡ Support the HiveSQL proposal to keep it running for free!
HiveSQL Proposal - Keep It Free To Use For The Community
Setting Up a HiveSQL Account
To access HiveSQL, you’ll need an account. There’s a small one-time registration fee of 1 HBD to prevent spam.
Follow this guide to register:
🔗 HiveSQL Registration Guide
Preparing Your Machine (Windows)
If you're on Windows, you’ll need to install the ODBC driver to connect to HiveSQL.
Install the ODBC Driver
To perform SQL queries using Python, install the official Microsoft ODBC Driver 17 (18) for SQL Server (x64):
🔗 Download Here
➡For Other OS platform check out this link:
HiveSQL for Python developers
What is ODBC?
ODBC (Open Database Connectivity) is a standard way to connect applications (like Python) to databases (like HiveSQL). It acts as a bridge between your code and the database, allowing you to send SQL queries and receive results.
Installing Python Packages
Now that HiveSQL is set up, let’s install the necessary Python packages:
pip install pypyodbc pandas plotly
Here's what each package does:
📌 pypyodbc – Connects to the SQL Server and runs queries
📌 pandas – Handles large datasets efficiently
📌 plotly – Creates beautiful interactive charts
The setup process might seem a bit tedious, but you only have to do it once. Now comes the fun part—querying Hive data and visualizing it! Stay tuned for the next post, where we’ll start pulling real data from the blockchain! 🚀
Querying HiveSQL with Python
Now that we’ve set up HiveSQL, it’s time to write some Python code to pull data and visualize it. First, we need to set up a connection to the database and create a function that runs SQL queries and returns a pandas DataFrame. This will make it super easy to work with the data later.
Setting Up the SQL Connection
Before we start querying, let's set up a function to connect to HiveSQL and execute SQL queries. This function will:
✅ Establish a connection to the database
✅ Run a given SQL query
✅ Return the results as a pandas DataFrame
import logging
import pypyodbc
import pandas as pd
db_username = "<YOUR OWN HIVE SQL USERNAME>"
db_password = "<YOUR OWN HIVE SQL PASSWORD>"
# Connection string using secrets
connection_string = f"""
Driver={{ODBC Driver 17 for SQL Server}};
Server=vip.hivesql.io;
Database=DBHive;
UID={db_username};
PWD={db_password};
TrustServerCertificate=yes;
Encrypt=yes
"""
# Setup logger
log = logging.getLogger()
def execute_query_df(query):
"""
Executes a SQL query and returns a Pandas DataFrame.
Parameters:
- query: str, the SQL query to execute.
Returns:
- pd.DataFrame with query results or an empty DataFrame if there's an error or no results.
"""
connection = None
try:
# Setup connection
connection = pypyodbc.connect(connection_string)
cursor = connection.cursor()
# Execute the query
cursor.execute(query)
# Fetch column names dynamically from the cursor description
columns = [column[0] for column in cursor.description] if cursor.description else []
# Fetch results
result = cursor.fetchall()
return pd.DataFrame(result, columns=columns) if result else pd.DataFrame(columns=columns)
except pypyodbc.Error as e:
log.error(f"Database error: {e}")
return pd.DataFrame() # Return an empty DataFrame on error
finally:
if connection:
connection.close()
Now that we have our connection set up, let’s start running queries and visualizing the data! 🎉
Running a Query and Plotting a Graph
If you’re not familiar with SQL, don’t worry! You can always search online for SQL query examples, or just ask ChatGPT to help you. 😆
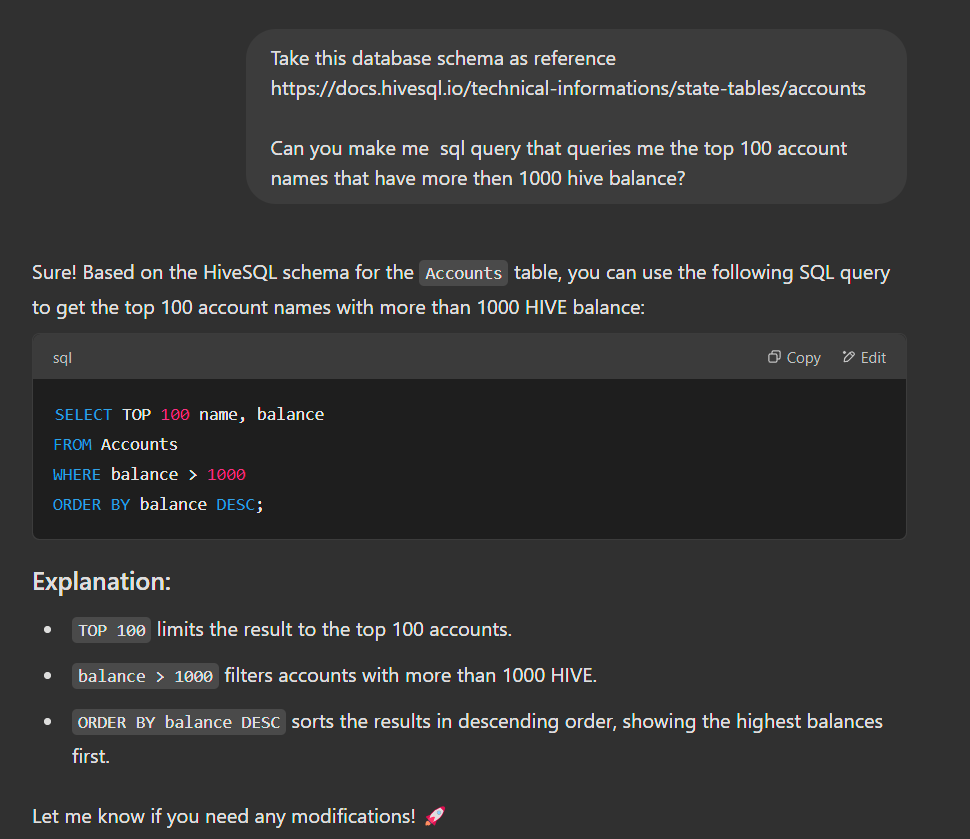
Let’s start with a simple query that pulls the top 100 accounts with the highest balances and plots them in a bar chart.
Moving It Into Python Code
Now let’s run this query and visualize the results using Plotly.
import plotly.express as px
if __name__ == "__main__":
df = execute_query_df("""
SELECT TOP 100 name, balance
FROM Accounts
WHERE balance > 1000
ORDER BY balance DESC;
""")
fig = px.bar(df, x='name', y='balance', title="Top 100 Hive Accounts by Balance")
fig.show()
And There You Have It—Your First HiveSQL Chart! 🚀
With just a few lines of code, we've queried HiveSQL and generated a bar chart of the top accounts by balance.
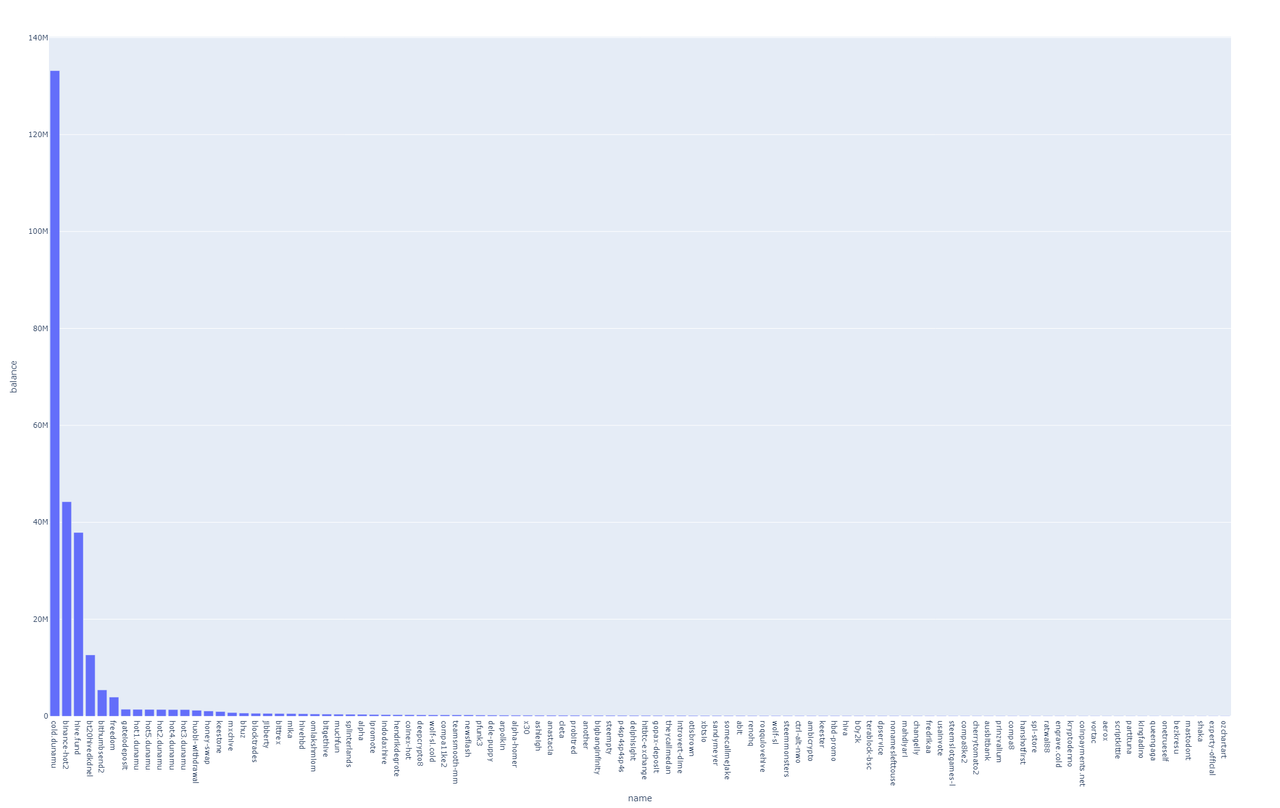
Why Use Plotly?
✔ Interactive charts – Hover over bars to see exact values
✔ Easy customization – Change colors, labels, and chart types
✔ Great for data analysis – Perfect for exploring Hive data
The possibilities are endless when it comes to what data you can query and visualize. Plotly allows you to tweak almost everything—axis labels, colors, chart types, and even animations!
Full Code
Here’s the full script in case you want to copy and paste it:
Click to expand full code
import logging
import pypyodbc
import pandas as pd
import plotly.express as px
db_username = "<YOUR OWN HIVE SQL USERNAME>"
db_password = "<YOUR OWN HIVE SQL PASSWORD>"
# Connection string using secrets
connection_string = f"""
Driver={{ODBC Driver 17 for SQL Server}};
Server=vip.hivesql.io;
Database=DBHive;
UID={db_username};
PWD={db_password};
TrustServerCertificate=yes;
Encrypt=yes
"""
# Setup logger
log = logging.getLogger()
def execute_query_df(query):
"""
Executes a SQL query and returns a Pandas DataFrame.
Parameters:
- query: str, the SQL query to execute.
Returns:
- pd.DataFrame with query results or an empty DataFrame if there's an error or no results.
"""
connection = None
try:
# Setup connection
connection = pypyodbc.connect(connection_string)
cursor = connection.cursor()
# Execute Query
cursor.execute(query)
# Fetch column names dynamically from the cursor description
columns = [column[0] for column in cursor.description] if cursor.description else []
# Fetch results
result = cursor.fetchall()
return pd.DataFrame(result, columns=columns) if result else pd.DataFrame(columns=columns)
except pypyodbc.Error as e:
log.error(f"Database error: {e}")
return pd.DataFrame() # Return empty DataFrame on error
finally:
if connection:
connection.close()
if __name__ == "__main__":
df = execute_query_df("""
SELECT TOP 100 name, balance
FROM Accounts
WHERE balance > 1000
ORDER BY balance DESC;
""")
fig = px.bar(df, x='name', y='balance', title="Top 100 Hive Accounts by Balance")
fig.show()
Final Thoughts
I know this is just the basics, and many Hive users in the community might already be familiar with these methods (or even have better ones!). But if you're new to HiveSQL, I hope this guide helps you get started!
If you’re interested in more advanced topics, let me know in the comments! 🚀 Some possible ideas for future blogs:
📌 More advanced SQL queries – Finding active users or trending posts
📌 Better visualizations – combining chart and updating layouts
📌 Deploying a live app – Making an interactive Hive data dashboard
Let me know what you’d like to see next! As always, feedback is welcome, and I hope you enjoyed this post. 😃
Thank you so much for posting such a guide, I really needed this
A quick question: I have a laptop with low memory and a little slow. Can I still run it or is it better to wait until I get a new one?
I think it can be done with pretty low memory.. there is just one way to find out. Lets go 🤣
My IDE (Pycharm) takes most of the mem with bigger programs 1.3GB.
Just noted that my browser with all opened tabs took 2GB 😱
Well your post is noted so I will tag you when I will try it out :)
Oh this is pretty cool! Thank you for posting it!
Thanks, hopes it inspire to start with python 😍
loved reading it. thanks for sharing.
in your next writing, can you share what you have extracted or trends you analyzed? what information did you get from this? do you have any data or can you extract to know
what are trending topics?
Thanks for the interest, currently i have no dataset available on trends.
One could start discover those via queries like, most rewarding post in the past 6 months or most commented post in the past 6 months etc. And of those posts which tags where used.
Defining what is trending will be a tricky part but the data is there todo it.
Also if you want to explore it right away hive.blog has something like this already:
Which tool you used to create the title image? I might try it.
Excellent post! You are making positive impact at hive.
Thanks @azircon,
Currently I'm using DALL-E by By ChatGPT. Really like the output, sometimes its a bit to much bells and whistles that distracts.
I use the bing image generator which also uses DALL-E3, but I find the results less than satisfactory. So I am looking for an alternative.
Mix things up I guess, i like the clean look of the headless chicken 🤣.
I didn’t spend any time on it.
Most went to set up the power bi dashboard. I don’t like it.
Spotfire is so much better, but they have made it prohibitively expensive now!
Thanks for the idea. I Will try peeking for some meaningful data in the hive blockchain. Thanks for this guide !BBH
Hope it suites you well 👋
❤️
Awesome post! I'm a newbie with Python, but I'm slowly trying to learn new stuff and this is going to help me a lot. I've already started giving a look into Hive SQL - inspired by your site and work around the KE ratio - but having some working examples is great! Can't wait to analyze them more carefully :) (in the weekend I often don't have access to my pc, so right now I can only go through the code but not try it!).
Dropping a follow because I'd love to read more posts like this one!
THIS WOULD BE HUGE! How to create an online interface for my scripts is something I'd love to learn 😍
Thanks for dropping by.. Python is a great programming language to learn, it has a lot of possibilities.
We can definitely dive a little bit deeper into deploying a live app.
In the past i made a post about streamlit. This is what i currently use and makes it pretty easy if you know a bit of python 😍.
https://peakd.com/hive-13323/@beaker007/spl-card-distribution-part-2-streamlit-experiment
Thanks so much! I'm definetely going to try it! From your post the process looks quite straightforward, so I hope to be able to use it and run my first web-app :))) gonna try it as soon as I get to my pc!
!PIMP
💪let me know if you have any questions
Very interesting and useful post about hivesql
!hiqvote
!discovery 30
@tipu curate
Upvoted 👌 (Mana: 0/45) Liquid rewards.
This post was shared and voted inside the discord by the curators team of discovery-it
Join our Community and follow our Curation Trail
Discovery-it is also a Witness, vote for us here
Delegate to us for passive income. Check our 80% fee-back Program
@libertycrypto27, the HiQ Smart Bot has recognized your request (1/3) and will start the voting trail.
In addition, @beaker007 gets !WEED from @hiq.redaktion.
For further questions, check out https://hiq-hive.com or join our Discord. And don't forget to vote HiQs fucking Witness! 😻
would like to see trending topics, user base for trading niche, technical analysis, financial health niche, personal finance etc.
Thanks for sharing! - @azircon
