Some of the following changes are very likely possibilities, others might be in the realm of science fiction with strong lean towards the latter. I'll start with the least interesting but more likely, changing towards daydreaming at the end :o)
Execution time.
In last article I've described some of the optimizations that were made for coming HF26. I also said there is still room for improvements.
Undo sessions.
While running flood test with 1MB blocks I've noticed some peculiar values of execution time. See for yourself (irrelevant parts of block stats cut out): "exec":{"offset":-399927,"pre":21,"work":200490,"post":33088,"all":233599}. Just a remainder that in case of node that produced a block, exec.work contains time of phase 0, while exec.post contains phase 1 and 2. In this particular case there were no pending transactions left (other than those that were put inside block), so only phase 1, but still, phase 0 applies transactions and packs them inside block, phase 1 reapplies freshly produced block: applies the same transactions and on top of that does the automatic state processing. How come exec.post is 6 times shorter than exec.work? I did some more logging and it turned out one key element is responsible for all the difference. Block producer has to apply transactions one by one, opening individual undo sessions and squashing them when transaction is ok. When block is applied, it works under just one undo session - for entire block.
Flood test works with just custom_jsons, so there are no changes to the state - undo sessions were empty. Custom_jsons are also very fast to execute (well, unless they are delegate_rc_operation - not the case of this test), so the influence of the preparation/cleanup code necessary to execute each and every transaction is brought out. When sessions are empty, opening/squashing them consists of only running over all the registered state indexes and adding/removing individual index session objects onto/from stack. My gut feeling tells me the latter is the problem, although I've not confirmed it yet. If that is the case, then we could avoid constant talk to allocator by introducing new functionality of squash_and_reopen and undo_and_reopen - we'd just open one session and keep it open reusing it after squashing and/or undo. If that helps, then there is also reapplication of pending transactions. It also uses individual sessions for each transaction. Finally - a lot trickier to change, but should be doable - transactions coming from API/P2P also use separate sessions.
Accessing singletons.
Some state objects are only in one copy, but they are constantly accessed. One is particularly popular - dynamic_global_property_object. I wonder if asking for it from the index every time is not a bit wasteful. Most likely the effect won't even be noticeable, but who knows, I always wanted to try to just pull it once at the start and then use it through normal pointer. We've recently discovered that new boost version had some nasty things to say about such practice, since it started to erase object from index, if exception is thrown during its modification. That would mean we could not rely on pointer to state object to stay the same all the time. We've worked around that problem, so testing the idea should be safe again.
P2P.
I've mentioned before that there is certain instability in time P2P consumes to process block messages. Blocks take priority when sending fetch requests, but is that also true for answering such requests? I don't know. There are probably just two people that know enough about the code to analyze and potentially address the issue, but they are engaged in not just Hive, so changes here should be put in the realm of fiction.
RAM consumption.
HF24 was the one that brought memory consumption down from ridiculous to meh-but-ok levels Hive nodes need now. There are more changes of the same type that can still be done, but at this point they all together might free up maybe 1GB of memory - not that impressive considering the amount of work required. It would look a lot better though if we did such change after cutting down memory consumption by 2+. Sounds interesting?
Drop inactive data to DB.
Currently the state index that takes the most memory (over 9GB), despite all the trimming, is the one related to comment_object. Then there are all the indexes related to accounts (2.6GB). But how many comments are actively replied to or voted on? How many accounts are involved in transactions at any given time? Maybe it is not that necessary to keep all that data in memory "just in case"? The idea reuses concept of MIRA (Multi-Index Rocksdb Adapter), but in more selective way. MIRA communicated all the changes to RocksDB immediately, so while the node did not consume a lot of memory, it was very slow (one of the reasons it was dropped from code). But we could do it in a bit more clever way, keeping users whose data we need in memory, only writing to database when we are ready to drop it from RAM after enough time have passed for last changes to become irreversible (now faster with OBI! :o) ). For comments we'd need to change method of hashing, otherwise we would not gain anything (now hash covers both author and permlink, so the database index can't selectively load only for active users).
The only downside of this approach is slightly slower execution of transactions that force the node to pull data from database to memory when inactive user becomes active.
Multi-index.
Let's get more radical. All the state objects reside in boost multi-indexes. While the structure provides various types of indexes, hived only uses one, the red-black tree. Each node of such tree consists of three pointers and a flag, taking 32 bytes for each index type (times number of indexed objects). For example, comment_object itself takes 32 bytes, but it has 2 indexes, which add 32 bytes each, for 96 bytes per comment. If you are surprised that comment only takes that little, it is because the content is in HAF/Hivemind, not in node memory, and the data needed for calculating rewards is in separate temporary comment_cashout_object. What's left is only the data that we need permanently to be able to tell the comment exists and how it is related to other comments. Ok, so 32 bytes for index node does not look to be that much, but it can be brought down to 16 bytes (12 if we are extra aggressive about it, under assumption we'd never have more than 2 billion objects of the same type in memory; note that we already have assumption about not having more than 4 billion, since object id is 32bit). Since all state objects are stored in multi-index structures, saving on the overhead of such structure should add up to serious numbers.
To turn 8 byte pointers into 4 byte indexes, we'd need to use pool allocator (I know this concept as "block allocator" by the way). Let's say we are going to use blocks of 4k objects. Then the lower 12 bits of object index is a chunk index within block and the upper bits represent index of the block. We can use that trick not just for index tree nodes, but for state objects as well. It can even let us drop now mandatory by_id indexes (since the allocator will be enough to find object by its block+chunk id), although it won't be applicable to the most important types of objects, since as proposed above, we want to remove them from memory, therefore object index and its allocation index might diverge.
Now there is one more mystery. When we add up all the memory officially taken by state objects, we can account for maybe 2/3 at best. Where is the rest? It is the issue that needs investigating, but in case it is related to overhead of boost interprocess allocator (the one that is used to store all the objects in shared_memory_file) or memory fragmentation, use of pool allocators might mitigate most of it (that would be the best outcome, because we'd gain a lot more from optimizations that we want to do anyway).
Storage consumption.
It might not look that important at first, since it is just relatively cheap disk storage. However nodes keep eating more and more, even more now with HAF in place, that calls for exceptionally fast NVMe storage. Some steps to address the problem were already done for HF26 in form of compressed block log, but in the long run it is just buying some time. HAF is in a way still in its infancy and there are signs that its storage can be radically optimized (although don't ask me for any details as I only know general concept of HAF, never worked on its code). Hivemind is ridiculously bad, and it starts in its APIs - the best approach is to just phase it out in favor of something new.
Node operators, especially witnesses, usually don't just run one node. Each node consumes at least the space required by block_log (350GB or something close after compression). Even if we managed to aggressively reduce memory consumption, the space requirements would still remain off-putting for regular users that wouldn't otherwise mind to run their own node.
Any change in this field requires preparations in form of isolating block log code from rest of hived code. Once it is put behind well defined interface, we can start testing and implementing various ideas catering to different node operators. It would allow selecting the features you need just like it can be done with plugins.
1. Pruning with fallback.
The node would keep select range of the most recent blocks either in memory or on local disk (depending on the settings), frequently pruning them as they become old. If some peer asks for block that was pruned, the node would fall back to redirect the call to some known unpruned node. Fallback could probably be also implemented in load balancer.
Pruned nodes would be most suitable for people that did not operate any nodes so far, or for those who operate many nodes in single location. The downside is that if you ever need to replay, you'd need to acquire block log from somewhere or sync from scratch, which is going to take a lot longer than just pure replay.
By the way, the idea of pruning with fallback can also be partially applied to Hivemind or HAF.
2. Archiving.
Similar to above, however instead of removing pruned blocks, it would occasionally store a whole chunk of blocks on slower/cheaper storage. Block log would be split into many smaller files, easier to store and transfer. If fallback was also added, the archiving could target even the sequential tape storage, which would make the node ready for next hundred years of Hive existence while keeping the benefit of having access to your own block_log in case of replay.
3. Reusing HAF.
At the moment HAF probably does not contain all the data necessary to implement block API, it wasn't designed for that after all, but it shouldn't be too hard to supplement. The block data is pushed to HAF anyway, so if you are operating HAF node, there should be no need to have separate block_log.
4. Sharing.
When you have many nodes in single location (witness and API nodes perhaps?), and you want all of them to be able to provide any block, they could use the same file(s) on shared network location. The problem is that all those nodes would also want to write to that shared block_log. That's why they wouldn't be writing directly but through a service. Only the first node would actually write, for all other nodes the service would only verify that what they wanted to write is the same (and frankly, if they disagree on old irreversible blocks, they are running different chains already).
There can probably be more ideas on how to provide information stored in block_log, but above should suffice for now :o)
Volatile sidechain.
Still about storage consumption, but the idea is radical enough to have its own paragraph (it is the most of all in the fiction space).
The great benefit of having a blockchain is that whatever you do, will stay available forever. The great downside of having a blockchain is that whatever you do will keep consuming storage forever. And there are things you wouldn't actually mind if they were lost, as they don't bring value beyond limited timeframe and in the same time are not necessary to restore state during replay.
Let's start with something easy. You are playing in The Speed-chess Battle Tournament. You pay in some fee, then you play against other players, and finally the rewards are given out. All the monetary transfers are recorded on the blockchain, and so are the moves of all the players (so everyone can verify that there was no foul play). But once some time has passed, all that matters is the fees paid and rewards earned. What if we could store the moves of players in a separate chain, designed to only keep the records for a month? But not a private one kept by app operator - we still want all the benefits of having wide range of nodes validating and transmitting transactions related to that chain, we just want it to be cheaper. Since the records are dropped after a month, the cost of RC related to history_bytes (dominant cost of many operations) should be a lot lower. And make it more responsive while at it (half-second blocks?).
Wouldn't it put more work on the shoulders of witnesses to manage two chains at once? Not necessarily. The amount of incoming transactions would be the same, process of validation would be almost the same, just some transactions would be marked as volatile to indicate that they should be placed outside of main chain. Since by definition such transactions should be generally stateless for consensus code, it could turn out that they might be easier to apply than regular transactions (because they might not even need undo sessions). Each witness, instead of producing one block within 3 seconds, would be producing that one block plus couple consecutive sidechain blocks. Sidechain could be handled by separate thread, so there would be no problem of one blocking production of the other.
Of course there are challenges. First of all, not all operations make sense to be stored in volatile chain. F.e. those related to assets or voting cannot be stored there. In case of custom_jsons there really is no way for consensus code to tell which of them could be allowed to be volatile (at least until we gain ability to define and enforce schemas for custom_jsons, which calls for 2nd layer governance, which in turn calls for SMTs), so apps that use them would have to be prepared that their operations might be marked wrong and react accordingly. In practice it would be responsibility of app's client code to send properly marked transactions according to the specific demands of application server. Even then some operations might still be marked wrong. F.e. Hivemind should ignore volatile follow, however orders to clear notifications, that should disappear on their own after a month anyway, could be volatile (and interpreted as such even if placed in main chain). I think the biggest problem there is a lot of opportunities to introduce bugs in the apps. The general rule is simple though: if the operation changes state, it cannot be volatile (and if marked as one, it should be ignored), unless the state itself is volatile (like in case of notifications).
Another challenge is the relation between main chain and sidechain. Now that we have only one chain of blocks, it is the witnesses that decide on final order of transactions. Sidechain would be similar within itself. Since main chain cannot rely on data from sidechain, it would not have any connection to it. So only the sidechain should link to main chain, at least once in a while. The fragments of main chain and sidechain that are after last connection should be considered concurrent by the apps (and therefore not having definite order). If there was just one sideblock between regular blocks, considering all the optimizations already done, it would be no challenge to just link from sideblock to the last regular block, however if sidechain was to be considerably faster, it would need to link to at least one block in the past (because during time of production of first sideblock from the batch, "the last regular block" to link to, at least in order of timestamps, could still be in production).
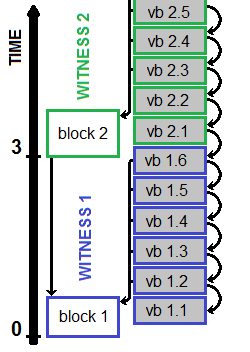
Relation of block 2 and vb2.1+vb2.2 is unknown (despite volatile blocks having later timestamps) - they should be treated as concurrent.
Can a witness miss regular block but not volatile blocks? Can he miss some but not all volatile blocks? When next witness can assume volatile blocks were missed?
Solidify.
Imagine you have a Hive based version of Signal. Normally you talk to your wife about grocery list, arrange a meeting with buddies, pass links to funny cats during work or haggle over price of drugs with your dealer (not judging, I don't know the content of your conversation, it is all encrypted). Such conversations disappearing after a month won't cause problems. However someone might have promised you something and you want to be able to go back to that message. Solidify! You pass transaction to regular chain that says: "volatile block X, transaction Y, looked like this (full content)". As long as it is still within a month (and also the block X is in the definite past - look above problems with ordering) the node can accept such transaction confirming that it took place. Of course solidification means you will be paying history_bytes RC cost for someone's transaction (since its full content is contained in your own). Notice that when replaying or syncing from deep past, node won't have the ability to validate such transaction. It would need to assume it was ok if it is contained within correctly signed block. Which brings me to another idea:
Volatile signatures.
Let's store signatures as volatile and forget about them after a month. When replaying, unless with --validate-during-replay, node ignores signatures. When syncing from deep past the node validates everything, however it doesn't really need to. The past block was signed by proper witness, next blocks are based on that block, looking couple blocks into the relative future it is clear that enough witnesses confirmed it to make it irreversible. But what if witnesses conspired to rewrite the past? Not having to fake user signatures, they would be able to do that. True, however they'd need to toss out a whole month worth of most recent transactions, since for last month you'd still have all the data like today. User signatures on last month transactions protect those from being faked and TaPoS on them protects past from being rewritten.
We wouldn't be able to remove signatures from the main chain retroactively, since block ids are based on block headers that contain merkle root, which in turn depends on merkle digests of contained transactions. Those are calculated from the whole signed transactions, signatures included. But for future blocks making signatures volatile (and not include them in the digests) could reduce amount of data permanently stored in main chain.
Volatile comments and votes.
Not all of course, but "Cheers. Great post!" or "Congratulations, your post received 2.71% upvote from manual-curator bot" might be nice when you see them, but they don't have a lasting effect, they bring cost but not a lot of value. Same with dust or ineffective post-cashout votes. They act as "likes", a notification that someone spent time reading your content. They don't really need to be there after a month. While third party apps using custom_jsons don't have the ability to enforce their rules on operation volatility, the hived itself obviously can. Keep in mind general rule - if it changes state, it cannot be volatile. The following rules would have to apply:
- volatile comments can only be edited, deleted, replied to or voted on with volatile operations
- you can volatile reply to non-volatile comment, you can also volatile vote on non-volatile comment (it won't have any effect though)
- volatile comments are not subject to author nor curation rewards, therefore it should also not be possible to set options for them
- volatile comments can't be used in proposals
- it is up to services like Hivemind to decide if edits of volatile comments should become inaccessible with main comment after a month, or such edit would prolong the life of main comment; similar thing applies to replies to such comments; from perspective of consensus code each volatile transaction has to die at definitive time after it was included in block (so f.e. you won't be able to solidify someone's comment after a month even if there were later replies to that comment that are younger than month)
- when replaying blockchain, once node reaches most recent month when it has volatile blocks, extra care needs to be taken, f.e. instead of asserting on missing target - volatile comment that was replied to - node needs to assume it was there, but is now outside its time window
There are most likely more rules that needs to be enforced, but that's just the general idea.
Which of the above ideas would you prefer to see implemented?
If you're going to rely on "social consensus" to define the validity of old blocks you can just create a new block ID scheme, and publish a checkpoint based on that, or even have one literal large BLOB+hash containing the entirety of millions of old blocks, and dispense with all other verification and data needed only for verification. It doesn't matter that old blocks didn't work that way, once you've decided to accept this snapshot going forward.
Its abZorbin time!
The neural net text ai stuff reminds me of newlife.ai where every photo you upload has a ai driven list of words it gleans from your post like an image of you on a couch with a lamp will for exmple say "couch" and "lamp" etc
Adding newlife.ai to hive would be so powerful as a hive dapp
Really cool the idea of social consensus
~~~ embed:1558954326478884864 twitter metadata:U3RlZW1hZGlffHxodHRwczovL3R3aXR0ZXIuY29tL1N0ZWVtYWRpXy9zdGF0dXMvMTU1ODk1NDMyNjQ3ODg4NDg2NHw= ~~~
The rewards earned on this comment will go directly to the people( @hivetrending, @steemadi ) sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
For the storage consumption part, I find the archiving method quite interesting or even pruning. We could have even further "lite" nodes, whereas they only sync the latest xM blocks and then verify it for another xM before pruning/archiving their old one. Though we would have to have some nodes keep the entire block log for times when other nodes have to retrieve the data, whether for API calls or just blockchain stability.
If this could be done, I don't see a reason why we wouldn't be able to reduce block_log to something minuscule, like only a few gigabytes.
For storage use https://dstor.cloud on @telosnetwork which has partnership with hive
Whatever happened with that partnership, I feel like there could be more things we could collab on but I don't even think they're using Hive to blog/update us on whatever Telos is doing, I frankly have close to no idea what they do.
Very much enjoyed reading, thanks for taking the time to share all these future possibilities.
It seems to me that decentralization will have a much larger importance than scalability. We can always reduce our usage of the blockchain by keeping it only for things of high social importance, and we can find temporary storage elsewhere and put only the high-level summary of it on the blockchain. If we implement optimizations that sacrifice any aspect of decentralization, for the sake of improved efficiency, it seems like a huge net loss to me. Design improvements that increase both efficiency and decentralization (e.g. by making it less expensive to run a node) seem like what we'd want to pursue, and I think you had a variety of them.
Another point. There is an effect that has been studied, where making optimizations to a resource so as to make it more affordable and available leads to a highly increased usage and squandering of that resource. As we make the blockchain a more and more available resource, perhaps we have to equally protect it from being squandered by all sorts of meaningless bots and similar, which can completely negate the gains of optimization and thus make the blockchain not affordable to the common folk. Let us learn from this past experience which engineers have encountered for centuries. Here is a quote from the book "Energy and the Wealth of Nations: An Introduction to Biophysical Economics":
We are besieged nearly daily by many different "green" plans that promise, usually through some kind of technology or improvement in efficiency, sustainability, or at least progress in that direction. There is a certain logic and appeal of such plans because they offer indefinite "sustainability" with less impact on the Earth or the supplies of its critical resources. Unfortunately, we believe that most such technologies are in fact counterproductive because of some manifestation of Jevons' paradox. Stanley Jevons originally believed that given the ultimate depletion of England's coal it was necessary to make the machines that used it more efficient. [24] But, in fact, he found that in the past such efficiency improvements made the use of steam engines cheaper so that more uses were found for them and technical changes designed to save coal actually ended up causing more coal to be used. More recent examples are that more efficient automobiles have led to more miles driven, more efficient refrigerators to larger refrigerators, more insulation to larger houses, and so on. Even cheap solar energy, should that be obtainable, allow the continued exacerbation of all the global problems given in Figs. 23.4 and 23.5. While we do think that efficiency improvements of many sorts certainly do have their place, they must be implemented within the context of constraints of total use, or they are likely to be counterproductive.I wrote about possible optimizations because I think we have to be proactive in that field. For example recently I've heard about the idea to introduce custom authorizations (like in EOS). Such customization is great and really useful, however it introduces potential source of a lot of long term memory consumption, so we need to reduce current usage in order to make space for new feature. Also, let's say someone comes to Hive and says "I have a service that will bring 10 million new users with it." We should be ready to answer "Not a problem" rather than "That's tough. We need a year to fix our code so we can accommodate that many users."
I understand the concerns about making resources more affordable that could lead to their wasteful overuse for activity that does not bring value. But we are using RC to express "cost" of those resources. As flawed as that system is, making code consume less real life resources does not automatically mean it will be reflected with lesser RC cost.
I can't disagree more with the quote on efficiency being counterproductive. It is only counterproductive to the narrow goal of making people consume less resources. I think the opposite is true. Only cheap resources can be wasted, the damage is especially evident when those resources are subsidized, precisely because in such environment there is no need to invest in efficiency. However when you are making some process more efficient, you free scarce resources to be used elsewhere, providing opportunity to spark more innovation, more productivity, more value for the same cost. And yes, that leads to even more resources being consumed. But that is natural. People will want to consume more and will strive towards goal of being able to afford more consumption - efficiency is one of the means to achieve that goal. Trying to artificially limit people in that field is to go against human nature and is doomed to failure. :o)
Thanks for replying, and I certainly appreciate that you write and think about optimizations to make, they are absolutely needed.
Great to hear.
Perhaps we understood it differently. I don't think the goal is to make people consume less resources. Let's take plastic bags (and all sorts of plastic wrappings) as an example. In previous times, people used re-usable containers for things, the containers lasted a long time and people would bring home beverages and all sorts of other things in those containers, then clean them and re-use them. With greater efficiency, plastic bags became ultra cheap, and that led to people buying them, using once and throwing them away, which has resulted in unimaginable pollution and loss of wildlife. People were not drinking and eating less before, when they used containers. It was just a re-usable more expensive container, whereas later there were ultra cheap throwaway bags.
As you are saying that efficiency gains won't necessarily result in cheaper RC costs, maybe we are good. I just thought it was an important point to mention. I do want millions (and eventually billions) of people to freely use our blockchain, and I don't want it to be clogged up by bots with bad intentions (like the commons typically can be ruined by people who don't care about others), and I don't want abuse to make it more difficult to scale and remain affordable such that we'd have to choose between scalability and decentralization. But if none of this is a problem, then great.
Congratulations @andablackwidow! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 900 upvotes.
Your next payout target is 1000 HP.
The unit is Hive Power equivalent because post and comment rewards can be split into HP and HBD
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Support the HiveBuzz project. Vote for our proposal!
Your content has been voted as a part of Encouragement program. Keep up the good work!
Use Ecency daily to boost your growth on platform!
Support Ecency
Vote for new Proposal
Delegate HP and earn more
I optimize the hive like optimus prime, keep my eyes on the larimer prize
Hive and telos dstor fellows the only way we do this is together HELLO
This is very detailed, nice.
That one's on me !BEER
Congratulations @andablackwidow! Your post has been a top performer on the Hive blockchain and you have been rewarded with the following badge:
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPSupport the HiveBuzz project. Vote for our proposal!
These type they posts make me see that there is a lot of work behind this blockchain.
I admire you.
Thanks for sharing.
nice testing!!!!!!!!!
That's the spirit!
nice, i love all of this
Reducing
block_logsize came at a price, in this case it was Storage/CPU tradeoff, we reduced space needed, at the cost of extra CPU used.Was it worth it? Yes, I think so, it's because for most of the time (while the node is at the head block) CPU usage is negligible, and even if there's a lot of work to be done during reindex, there's not that much work that could be split between the cores to run in parallel so CPU is underutilized.
Re: those 4 ideas for
block_logyou've mention. Answer is: yes. Especially making it independent of storage implementation (whether it's a huge monolith (un)comporessed file, or a 1M blocks file, or one dir every 1M files with each block in separate file, or a sophisticated database structure within HAF). That's actually what we've already discussed years ago, it's just matter of priorities.One important thing to keep in mind is that as the complexity of the implementation increases, we need proper tools with the power to manipulate it.
For example, until recently we could easily check consistency of the file at given block height with md5sum, currently even such simple task is not so easy.
For the pruning, we would have to make sure that there are proper incentives still in place in order not to wake up in the world that there's not enough seed nodes in existance to effectively obtain the full block_log.