As many of my readers know, the BlockTrades team has been devoting a lot of effort in the past year to creating a framework to ease the process of creating decentralized apps with Hive.
We recently completed some scripts to ease setting up a HAF server, thereby removing the last roadblock to HAF server deployment, so I thought it would be a good time to create an overview for Hive app developers about what HAF is, what problems it solves, and how to deploy HAF-based apps.
What is the Hive Application Framework (HAF)?
HAF is an application framework for creating highly scalable decentralized apps that operate on the Hive blockchain-based network. With HAF, data from the blockchain network are pushed into a SQL database (PostgreSQL) for easy consumption by HAF apps. This means that HAF-based apps can easily be designed and maintained by database programmers with no previous experience with blockchain-based programming.
Below is a diagram that shows how HAF apps consume and create state data stored on a HAF server. As new blocks are created in the blockchain, the transactions contained in these blocks are stored into the HAF database by a plugin within hived (the blockchain node software) called sql_serializer. HAF apps get notified of this new block data by the hive_fork_manager and process this data independently at their own speed.
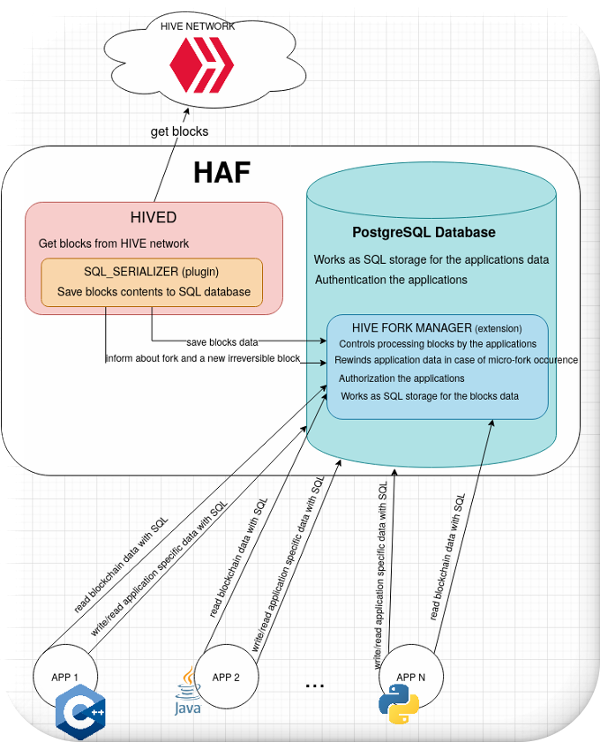
Hive Fork Manager postgres extension
The Hive Fork Manager is the primary way that HAF apps interface with blockchain data. It consists of several SQL stored procedures defined in a Postgres extension which are called by HAF apps to receive notifications of new block data.
One of the most powerful features offered by HAF as a service to apps is that it enables apps to easily maintain consistent internal state when transactions are reverted by a blockchain fork. To take advantage of this feature, HAF apps will normally register all the auxiliary tables that they create inside the HAF database to manage their own internal state. Once an application’s tables have been registered with the fork manager via stored procedure calls, the fork manager will automatically revert any state data in the event that blockchain data gets reverted by a fork in the blockchain network.
To understand the benefit of this, let’s consider a social media app that tracks how many times a user posts and all the upvotes on their posts. The raw blockchain data that the app processes just consists of transactions such as posts and votes which have been signed by users. The social media app maintains state data such as post counts and upvotes for each post inside SQL tables.
In the case of a blockchain fork, the transactions for a post and all its votes could be reverted (either temporarily or even permanently). When this happens, the app has to undo all its internal state changes that occurred because of those reverted transactions. In other words, a normal blockchain app has to build an “undo” action for every internal state change it makes when it processes a new blockchain transaction, then apply all those undo actions in reverse order when a fork occurs.
The hive fork manager eliminates the need for such undo code: it keeps a record of each change in state caused by transactions in a block and automatically performs the undo actions when blocks get reverted by a fork. In practice, this should cut in half the amount of code that is required to write a blockchain-based dapp and it also eliminates the chance for errors that can result if manually-written undo actions don’t get properly updated as the app’s functionality gets updated over time.
Note that this does imply that HAF apps should maintain all their state data inside a database and avoid maintaining any state data in memory. But this restriction also offers another important advantage: a HAF app can easily recover from system crashes and power outages since all its state data is kept in non-volatile storage. It is expected that HAF servers will typically store any performance-critical data on high-speed storage such as NVME drives, so this restriction should pose no problems for overall app performance.
Creating HAF apps that perform undo-able actions
Some HAF apps may need to perform actions that can’t be undone. For example, a game might make a blockchain-based payout to a winner in the game. Once the payout transaction is broadcast, the game may not be able retract such a payment if a blockchain fork occurs.
There’s two straightforward ways that a HAF app can manage the processing of undo-able actions: 1) a HAF app can be configured so that it only receives block data that can’t be reverted or 2) the HAF app can receive current block data like a regular HAF app, but it can have a scheduling system where all actions like payouts that can’t be undone are placed into a holding area, and only performed after the block which triggered the actions become irreversible.
Option 1 is the easiest method to program, of course, and this will probably be the most suitable method for designing financial apps, but option 2 may be useful for apps like games that require faster real-time response to user actions.
Anatomy of a HAF app
Most HAF apps will be divided into a backend component that contains the business logic and a frontend component that manages user interaction.
The backend processes blockchain data, modifies the app’s internal state data, and provides an app-specific API to the frontend for reading that state data. The backend is the component that talks to the hive fork manager and to the HAF database in general.
Backends will typically be coded as a combination of SQL stored procedures plus any language that supports a SQL binding. We have created example HAF apps written in pure SQL, SQL plus Python, and SQL plus C++. Here is a very simple pure SQL example including a frontend UI. Some small SQL/python example backends are located inside the HAF repo itself.
The frontend (typically a web application, but can also be a desktop GUI app) formats and displays app state data to the user and allows the user to construct and sign transactions related to the app. For example, the frontend for the aforementioned social media app would allow a user to create and sign blockchain transactions to create and vote on posts.
The frontend communicates with the backend component to get state data, and it broadcasts user transactions to a blockchain node to get the transactions included into the blockchain. Once the transactions get included into the blockchain, the backend can then update its internal state based on the new transactions.
First step BEFORE creating your first HAF app
Before you begin creating your own HAF app, I strongly recommend setting up a HAF server with some of the existing HAF apps, then reviewing the example apps to see some of the options you have in creating your own HAF app.
Recommended hardware for a general purpose HAF server
At Hive’s current block height of 60M+ blocks, a general purpose HAF database capable of running all HAF apps takes up about 2.7TB of storage before accounting for storage consumed by app-specific data. So, at a bare minimum, you will want at least 4TB of storage for a general purpose HAF server.
Note that it will soon be possible to setup app-specific HAF servers that have much smaller storage requirements, but when first learning about HAF you will need a general purpose HAF server to experiment with the example apps.
You will also want this storage to be fast to allow for faster initial filling of your HAF database, so with currently available hardware, my recommendation is to use 2 or 3 striped 2TB NVME drives configured as a 4TB or 6TB drive.
Setting up a HAF server
HAF servers get their blockchain data from a hived node. For maximum performance, it is best if the hived node is running on the same computer as your HAF server.
The easiest way to setup a HAF server is to start with a clean Ubuntu 20 system and follow the steps below (more options are possible, I’m just showing the simple one). For these steps, I’m assuming you are logged into an account that has sudoer privileges and default privileges to write to your “bad and fast” drive.
1. cd to a directory on your “big and fast” drive where you want to store your HAF database
2. git clone https://gitlab.syncad.com/hive/haf.git
2. cd haf
3. git checkout develop
4. ./scripts/setup_haf_instance.sh (note you may wish to use the –help option first to see useful options to optimally configure your HAF server on your particular computer)
The setup script above will install postgres 12 if it is not already installed, configures a HAF database in a tablespace on the big/fast drive, creates all database roles needed to administer your HAF database, and sets up and launches a hived node process that will begin feeding data to your HAF database.
Faster setup with an existing block_log file
It can take quite a while to sync a hived node via the p2p network from scratch, so if you’re already familiar with setting up a hived node, you will probably want to create a hived datadir with a config.ini file that includes configuration of the sql_serializer plugin and a blockchain subdirectory, copy a trusted block_log file into the blockchain directory that contains a recent list of blocks, then run the setup script as follows instead of using step 4 above:
alternate step 4. ./scripts/setup_haf_instance.sh –hived-data-dir=/my_fast_storage/.hived –hived-option=--force-replay
A replay of an existing block_log takes about 10 hours on one of our fast computers (fast here means a fast multi-core CPU and fast disk storage).
Next the hived node will enter p2p sync and grab any new blocks that were created since your block_log was created. Unless your block_log is old, this should only take a few minutes.
Once your hived node has finished p2p sync and reached the head block of the chain, it will create additional indexes for the HAF database tables to allow apps to efficiently search the database. This process takes about 3 hours on a fast system at the current block height of 60M blocks.
After these indexes are created, it will fetch and process blocks that were generated while the indexes were created until it reaches the head block. Once it reaches the head block, hived will display “LIVE SYNC” messages on its console to indicate that it is processing new blocks as soon as they are generated by the Hive network.
After hived enters live sync, any HAF apps that you may have configured on your server will begin to process the accumulated blocks of the blockchain, until they too are caught up to the head block and can enter their own livesync mode. Note: HAF apps don’t begin processing blockchain data before the HAF table indexes are added by the sql_serializer, because app queries would be too slow without these indexes.
Note we’re still planning some tweaks to the scripts that deploy a HAF server (for example, I want to add a command-line option to automatically download trusted block_log files and indexes). I also to improve the scripts so that they can be downloaded without requiring a git clone of HAF as a first step (with the current process, the HAF server ends up with a top-level haf directory that is just used to run the scripts and a “real” haf directory that it builds and runs with).
Setting up a HAF app
New HAF apps can be added to a general purpose HAF server at any time. A new app will begin by processing all the old blocks stored in the server, then enter live sync mode and begin processing new blocks one-by-one.
It is often useful to design your HAF app to be able to operate in a “massive sync” mode where it can process transactions from more than one old block simultaneously to reach live sync state faster.
The balance_tracker application is one example of a HAF app that has a massive-sync mode. To setup the balance tracker app on your HAF server:
- git clone https://gitlab.syncad.com/hive/balance_tracker.git
- Follow installation instructions in repo’s README.md file
Inspecting your HAF database and trying sample SQL queries
Once your hived node enters live sync mode, you should probably login into your haf database (the script uses haf_block_log as the default name for this database) and get familiar with the “hive” schema views that organize the raw blockchain data. You can do this with the psql command-line tool (e.g. psql -d haf_block_log followed by commands such as \dv+ hive.* to see the available views of the data and \dS+ hive.accounts_view to see the structure of a view) or with web-based tools that connect to a postgres server such as pgadmin, adminer, etc. You can also begin to experiment in these tools with SQL queries of the views that your app might use to get blockchain data.
Reading the docs for HAF app design
As mentioned previously, a HAF app interacts with the HAF database via the hive_fork_manager. Details of how to design HAF apps and how HAF apps interact with the hive_fork_manager can be found in: https://gitlab.syncad.com/hive/haf/-/blob/develop/src/hive_fork_manager/Readme.md
Currently this document probably contains too much “internal information” about how the hive_fork_manager itself works. Despite that, I still recommend reading all of it, but apps designers should mainly focus on the parts of this document that discuss actual app design.
Hey, I would be interested in any experience you have on a mid-tier setup such as using NVMe as cache LVs for a stripped rotational disk array. I have used them before but they usually only work for subsets of data that either only keeps hot for a period of time and then very rarely will be accessed or data streams in append mode where usually there is very little re-reading of new data written.
Databases are a mess for the above workloads but if the cache LV is big enough to work with the tables being hot, they keep hot on the cache and hardly need to be read from rotational disk.
With the above scheme, you could easily configure a 1TB NVMe for cache and a couple of either small cheap SSDs or even rotating disks for the high capacity part.
Just curious if you guys explored these options and what was your end conclusions.
Thanks
We haven't tested it here because we're generally trying to test a max performance setup to see where the potential performance bottlenecks are, but a HAF setup like that should be fine.
I see... I will probably have to rely on such for now, but yeah, in a few years' time, NVMes might just have replaced most storage types (IOps/$ wise) under the 100TB range.
Curious if you guys used external storage for the NVMe's (fiber or SAS attached) or something like this? Which is something I wanna grab later in the year.
Yes, we use the very ASUS board you showed (and a couple other similar ones by MSI and Cablecc) that allow you to use one PCI 16x slot in "bifurcated mode" to connect 4 2TB gen4 nvme drives, which we typically configure into a 4x raid0 8TB drive.
We've been using Ryzen 3960X and more recently 5950X systems that support PCI4 drives. We buy pre-tested bare-bones 5950X systems from a systems integrator, then populate them with better drives and a full complement of memory once we get them (integrators tend to overcharge for these latter items).
Nice 👍 thanks! AMD still beats Intel on memory access and IO subsystem (PCIe lanes), and price then. Good to know that it’s not just me on the HPC market.
I will be looking close for when the PCIe 6.0 gets implemented because that will change the protocol. But still too soon as the market is delayed due ASIC shortage. Let’s see.
I am as well on the same path.. going to stay on the AM4 socket and jump to the highest core one, since I already have plenty memory to play with and there’s still some time until the new PCIe 5 get out to market.
Less possible errors mean a lot.
And a good foundation to build on :)
As far I understand it works technically like a buffer?
It provides buffering of a sort, because it removes loading from the hived nodes themselves, but that's only aspect of the design benefits of using HAF.
I know from past posts, everything becomes faster and more efficient :)
One of the most important things HAF does is making forking "invisible" to applications. If you want to make a reliable app that can safely process blocks very soon after they are produced, using HAF is a no-brainer. This applies to most long-running games, for example.
thanks for the explanation!
Like @psyberx right? So we can have a game thats future proof and lasts forever
This is really cool. I have gone through the HAF docs, it's well documented on how to get started with designing an HAF App and how to interact with the Hive Fork Manager.
Thanks for the update @blocktrades and great work.
Thanks, and please feel free to create issues in gitlab when/if you find any places where we can make improvements.
Alright @blocktrades, I would definitely do that when/if I find any issues. As I would greatly love to make impacts towards the development and betterment of HAF.
Im new to this platform and im glad to learn that developers are trying their best effort in creating apps that will benefit its endusers. Good job.
Very interesting! I've programmed web applications before and want to develop Hive-based apps, but this seems overwhelming. I'll start by reading through all of this information and looking at the example code. It would be great if there was a simplified "For Dummies" version of the documentation without the "internal information" you mention in the last paragraph.
It's simpler than it probably sounds here. If you've ever written an event-driven program, the programming model for the backend should be fairly familiar. Your app makes a SQL call to get notified whenever there's a new block of data from the blockchain that needs to be processed and you write SQL queries (and maybe pythton/C++ or some other language as well) that process that data into the databases tables you define for you application.
So far, that's pretty much how you would write any event-driven backend application. The "extra" step is you register your tables with the hive_fork_manager, so that it can automatically perform an "undo" on the state of your tables if some of the data you've processed gets reverted by a blockchain fork.
@blocktrades! The Hive.Pizza team manually curated this post.
Please vote for pizza.witness!
WOW, THAT'S GRAPE
This is really awesome keep up the good work moving
Wows, great work👍👍👍👍
Is it like a smart contract on ethereum?
No, HAF is quite different from a smart contract on ethereum, although both allow you to create apps on a blockchain. HAF is a general-purpose 2nd layer programming platform that offers much more flexibility than is offered by a smart contract platform.
Here's a key difference between the two platforms as it stands right now: on a smart contract platform, a developer can "publish" their application on the network, and the network nodes will (and must) automatically start supporting that app. By contrast, the operators of a HAF server are allowed to select which HAF apps they want to run on their server. Each of these two models of deployment have advantages and disadvantages.
But HAF as a general-purpose programming platform is actually a great base to build a smart contract platform on top of (and that's what we're planning to do next). Once our smart contract platform is deployed on a HAF server, any of the apps published for that smart contract platform will automatically start running on that HAF server.
So, ultimately, HAF servers will be able to benefit from both deployment models.
Wow, what a new development for #hive communities. I love the HAF idea
So it lets you read and write to the blockchain !
Oh this should create demand for actual hivepower for use with developers... theyll need it like people on ethereum need eth to pay gas fees
We already know this but now the reasons will be explained to everyone else .
C java and Python
The C part can plug into @telosnetwork and its ethereum EVM
Telos eosio smart contracts added in here and wow i am seeing the bigger picture of the eden
Hive Fork Manager
HFM Hive FM
Dawn FM (eosio)
The weeknd ...
Lots of cool art symbolism here
Visualizing this is so important i may expand on this visual and connect telos smart contracts to the PostgreSQRL database to allow more features for hive like evm and dstor to host dapps on hive in telos and eventually hive withesses run inside dstor servers instead of amazon
I'd guess at small scale @hivesql would be enough or am I missing something?
It is very different from HiveSQL. For example, HiveSQL doesn't have a fork manager.
Thanks for the continued effort!
I'm new here, please how do I go about
So this is supposed to make it easier for new developers to create apps for the Hive blockchain. The developments just keep coming
Yes, it will make it easier to create apps, and they will be faster and have fewer bugs.
Woow amazing
Thanks for the update
Congratulations @blocktrades! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next payout target is 1545000 HP.
The unit is Hive Power equivalent because post and comment rewards can be split into HP and HBD
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!
@cryptocharmers Good info for review.
Congratulations @blocktrades! Your post has been a top performer on the Hive blockchain and you have been rewarded with the following badges:
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!
Hi @blocktrades. The server specs to run HAF are pretty high right now. I have a question. So, let's say I want to build a DApp using HAF. Would I need to run my own instance or would there be one available for everyone to use? Cause with the minimum specs being that high, newer devs(Me included) would stick to writing more code than renting out a powerful server.
Just wondering if HAF would have a public instance like the current RPC nodes.
The server spec is for a general purpose HAF node that can store all the blockchain data. In a couple of weeks we'll have support for operations filtering (i.e. to filter for only the operations your app is interested in), which will make it quite cheap to be able to run an app-specific HAF server.
As to public servers, I'm sure there will be some, but you would need to get agreement from the server owner to run your app there. And for development itself, you're going to want to run your own dev server. So you may need to wait till filtering is implemented if a server with 4TB worth of storage is out of reach for you.
Got it. That makes sense. Thanks!
This is great information I want to learn this so much. I am bookmarking this for further review, thanks
SWEEEETTT !!!!!!
If there are problems with the development, then it might be better to turn to specialists? When I needed intervention in the program code, I turned to the guys who could quickly solve my problem. Here you can learn what they are doing and make the right choice for start a fintech company. But if you still have questions, be sure to contact. I will help! Good luck to you!