To fulfill some member's curiosity ;-) , i will here explain in details how i created the basic following picture from my last post of the draft comic that i'm currently creating in order to explore the recent AI graphic tools released on the net.
Like a kind of tutorial, i will describe all the steps i performed to get the following case :

The pictures fits into a page describing a journey trough a desertic area.
I was looking for some desertic landscape with an old road picture. (Later on, I looked also for pictures showing truck, animals or small devastated building in order to enhance the story's universe).
Producing init images.
I usually start by creating init images. I mean small pictures i can use to feed other AI program like ICGAN, VQGAN or CLIP Diffusion (links provided at the end of the post). For this purpose i usually start using Mini Dall-e algorythm because it is only driven by a textual prompt that will trigger picture creation.
For our case, i wrote the following prompt : " A lost desert road, a painting trending on Artstation". After a couple of tries, i collected the following ones :"

Derivation with IC-GAN
I focused my attention on the picture with a red square and submit it to IC-GAN.

In IC-GAN, you don't have any textual prompt, you just submit this picture as init image. Here without any sub-class specification. ICGAN created indeed a first derivation as folllows :

And i decided to re-use it to get more similar picture because it was closer to the desertic atmosphere i was looking for. I created a dozens pictures from wich i picked up three children picture as depicted by the arrows in the screenshot hereunder :
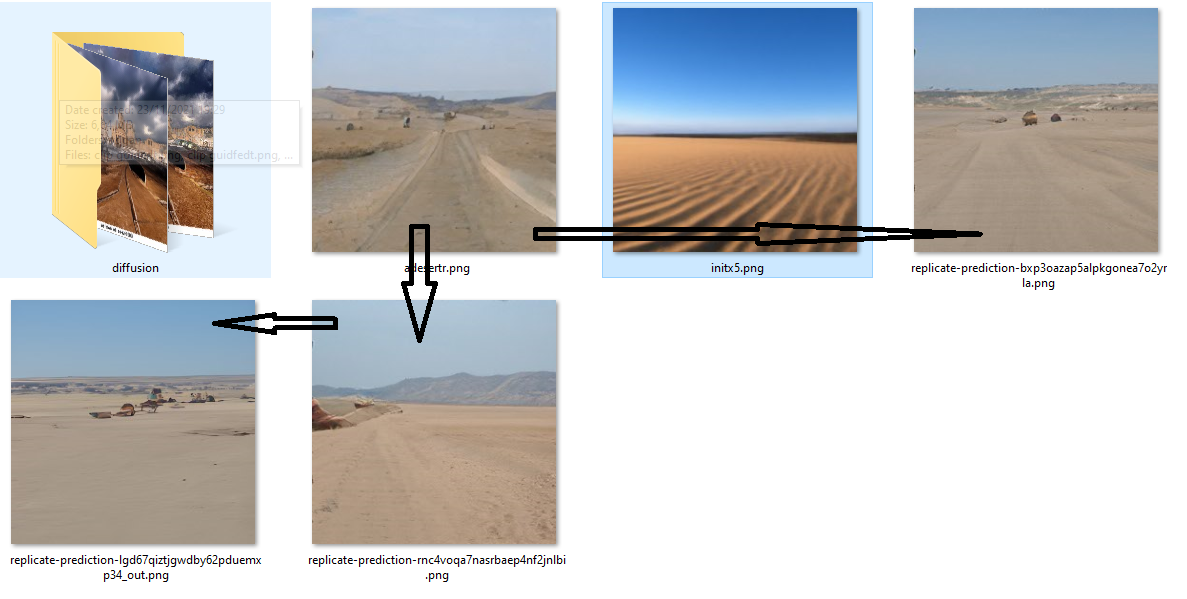
We are still working with very small 256x246px size, by zooming you see that they are still blurry, with a soft photographic painting style, so they need more fine-tuning. The most interesting is the coherence they have togheter, useful for storyline building.
Giving more details and drawing style by using CLIP+Diffusion.
Back to our initial case, i submitted the last picture of the set here above, to a CLIP guided diffusion process. And from this diffusion run, I kept the following picture :

Still same small size, but with more details, less blurry. Some track in the sand are appearing.
Here another set for a closer look at some of the refining possibilities :

Clip diffusion allows an init picture and a text prompt, you should see the parenthood from the previous set, but with some more detail and painting effect as i prompted the algorythm with "driving on a desert road with a city at the horizon, painted by Enki Bilal" (pic1). "driving on a desert road, painted by Enki Bilal" (pic2) "a lost desert track, painted by Enki Bilal" (pic3) "A road in the country, by Enki Bilal" (pic 4 - 70 steps, 5 - 35 steps, 6 - 15 steps) "a road going nowhere, painted by Enki Bilal" (pic 7 and 8).
With an init picture, Clip Diffusion keeps the global geometry but goes step by step in creating details by sticking to your textual information. As such it creates a city in the first picture, a kind of truck shape at the end of the road of pic 2, and a quite cool landscape at pic3. Note that pic1 and pic3 have the same parent picture dealing with our main example, and all the others share the same initial parent from the ICGAN session.
This is a very short sample, i have a dozen more pictures created like that quite similar in order to create a library.
Preparation of the scenario
Usually at this stage, i begin to brainstorm the arrangement of the picture into some comic templates in order to identify coherence, possible sequences, and hypothetic additional storyline. Therefore i use a pc software named ComicLife. It allows basic creation of comic page by providing page templates and baloons in a drag and drop way of doing.
Here the main interface screenshot :
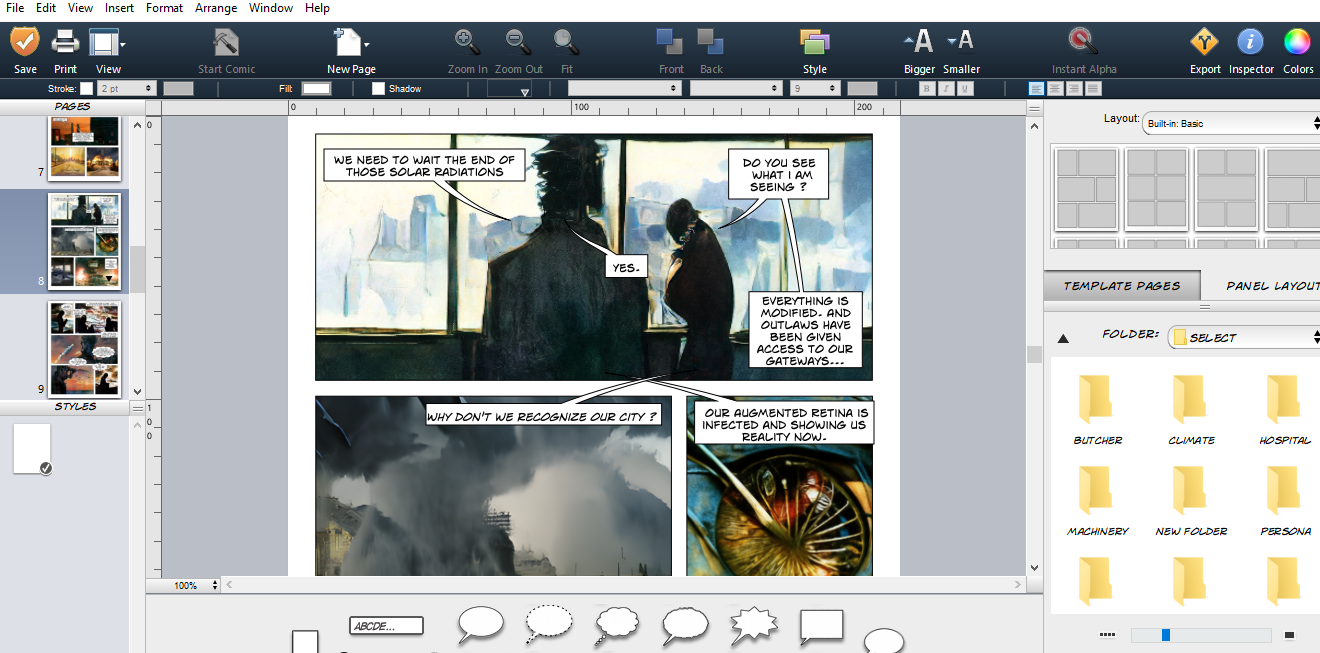
And here a work in progress, collecting and assembling the images.
Giving final style with VQGAN+CLIP
VQGAN allows textual prompt and init images. It creates very oniric pictures with strong painting styles (depending on the model). It can dramatically modify your init picture. That's why i apply some basic textual prompts and stop the process after 100 iterations and save a couple of frames of each creation in order to choose later on the best fitted picture. VQGAN enables larger size of picture production (512by512px) in free google colab. Even when upscaled they remain quite beautiful with some acceptable level of details.
In our case, i use the previous diffusion output as init image :
With a prompt named "A desertic lost road painted by Enki Bilal".
Here below, you see the picture it created after 20, 50, 70 and 90 steps.

20

50

70

90
I could have let it runned during more steps, but it would have given too much psychedelic and repetitive patterns. I was basically satisfied with the picture at 70 steps. At 90 steps i found the object appearing on the road too difficult to integrate in the story.
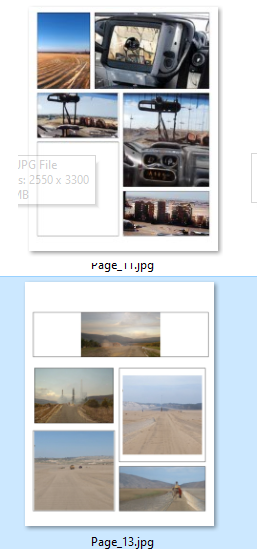
I finally upscale it for the sake of using pictures with affordable size (1280x1280px) to integrate it into the final page.

Upscaled
And finally placed into the page (the fourth box) :

Additional note.
- This is not a proven process, just my stage of experiments.
- I doubt being able to really keep a similar graphic style in a long run distance, but i have ideas to integrate this fact in the storyline.
- New tools and updates are coming these last weeks and may bring improvement on that field.
- Using real pictures as init images is still to explore to bring more pattern diversity.
Thanks for having read so far. If you were curious, i hope this was informative.
Processing Note:
New scripts, algorythms and models have been recently released these last two weeks on this very dynamic scene and i will probably abuse them shortly to continue this project. ( new keywords here are , rudalle, v-diffusion-jax v2 and Arbitrary Neural Style Transfer to name a few .)
The general rules of my creative processes is explained in some previous posts : I use a couple of AI graphic tools like IC-GAN, VQGAN+CLIP, CLIP guided diffusion etc. More info here and here. I use them in pipelines as explained here to produce pictures i can use to build this draft comic book experiment. Beyond my own cultural backgrounds to sketch the scenario i also use some AI nlp tools as inspiration source by discussing with chatbots, or prompting them to create characters templates and other ideas.
If you are curious, I would also recommend consulting the posts shared in the Latent Space Community - a child of - the Alien Art Hive Community.
From my creative process, i also now offer some exclusive collectible visual artworks produced during the "making of" this experiments, which from my perspective, could be art piece on their own. A new piece has just been released. See therefore my NFTshowroom Gallery.
Don't hesitate to drop comments or questions, and all my gratitude to the Alien Art Hive Community for your support and comments so far.
I love this creation, thank for sharing all the step...very interesting and inspiring :)
!discovery 36
!PIZZA
This post was shared and voted inside the discord by the curators team of discovery-it
Join our community! hive-193212
Discovery-it is also a Witness, vote for us here
Delegate to us for passive income. Check our 80% fee-back Program
PIZZA Holders sent $PIZZA tips in this post's comments:
lallo tipped dbddv01 (x1)
@jilt(4/10) tipped @dbddv01 (x1)
You can now send $PIZZA tips in Discord via tip.cc!
Congratulations @dbddv01! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s):
Your next target is to reach 4500 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Very detailed description of your workflow, thank you :)
!PIZZA