csv.Reader(newarticle)

Shoutout to Real Python

In this article you will find:
- Introduction
- What is the CSV module?
- Read files with the OS module
- Writing to a CSV file
- Write and read Dictionaries in a CSV File
Welcome back to another edition of Coding Basics. After having studied in detail and put into practice the handling of files with the open instruction and the os module, we can now take care of more complex problems.
In this case, I present to you a module used to manage a type of file widely used for the creation of datasets, huge collections of data that we can import to obtain important average information, the csv.
This is why in this post we will see the csv module, after which you will be an expert when it comes to managing the data structure of files with this extension
Let's get started!
What is the CSV module?

Shoutout to Python in Plain English
Before we can understand what the CSV module is, we must understand what a CSV file is.
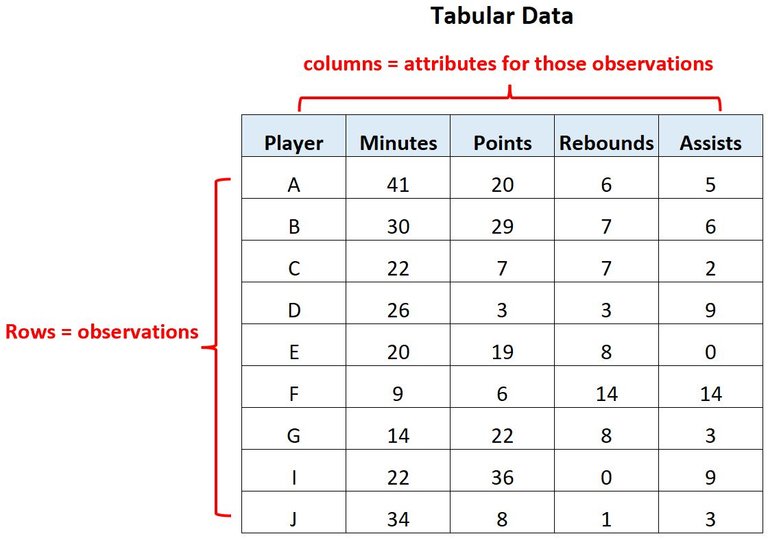
CSV or Comma Separated Values is a type of extension that refers to files that store tabular information, that is, data found in tables, as you can see in the following image:
Shoutout to and Pixabay.com
These tables are distributed in columns (vertical cells) and rows (cells distributed horizontally). Thus, each line of the CSV file will represent a row, where the data will be separated by commas, which will denote the number of columns. Hence its name: Values separated by comma.
What makes csv files so popular is the fact that they allow us to organize and store large amounts of information that we can access easily. Among its most popular uses are databases (Ex: MySQL) and the management of spreadsheets (Yes, like the ones we use in Excel).
It is because of the demand for handling csv files that many programming languages have built-in modules dedicated to these operations. In the case of Python, this module is called csv.
In the same way that open and some of the os functions allow us to handle certain types of files, csv allows us to perform a large number of operations with csv files, such as:
- Read CSV files.
- Write data to CSV files.
Not only this, but we can also add excellent functionalities to our programs, giving us the possibility of:
- Store emails in our csv files.
- Write dictionaries to csv files.
First, let's look at the most basic operation of all: Reading.
Read files with the OS module
Shoutout to GeeksforGeeks
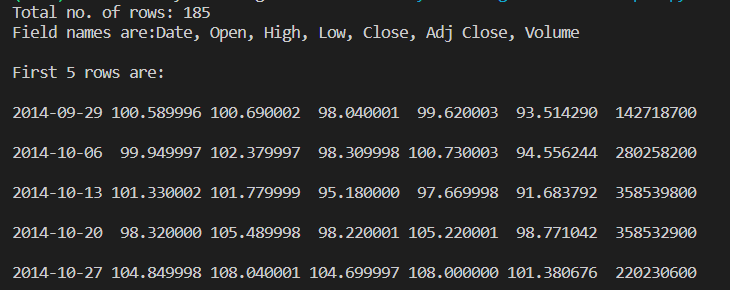
If we look at the following file, called username.csv, we will have the following data (If we open it with notepad):
Username, Identifier, First name, Last name
booker12,9012,Rachel,Booker
grey07,2070,Laura,Grey
johnson81,4081,Craig,Johnson
jenkins46,9346,Mary,Jenkins
smith79,5079,Jamie,Smith
We already know that the commas act as the separating lines between columns, while each line will be a row. Now, if we want to read a csv file, we will take into account csv.reader as the most important instruction
What csv.reader does is create an object of type csv.reader, which is an iterable from which we can obtain information as if it were a list. In this case, each element would be a list with the values of each line.
If we apply this in code:
import csv
file = 'username.csv'
rows = []
with open(file, 'r') as csvfile:
csvreader = csv.reader(csvfile)
for row in csvreader:
rows.append(row)
for row in rows:
print('\n')
for col in row:
print("%s"%col, end=" ")
Here, we can see that a file variable is created with the file name and we create an empty list to extract the values of the lines from the csv file.
If we want to read a csv file, we must open it the same as txt files, where we use open with the file name and 'r' (To indicate what we are going to read) as parameters. Next, we use the csv.reader to create the csv.reader type object from the opened csv file.
Once this is done, we simply apply a for loop to the csvreader object and extract each line from it, adding it to the list.
The nested for loop (A for loop inside another for loop) is used to separate columns and rows. This is because the rows list would look like this:
[['Usernamel', ' Identifier', 'First name', 'Last name'], ['booker12', '9012', 'Rachel', 'Booker'], ['grey07', '2070', 'Laura ', 'Grey'], ['johnson81', '4081', 'Craig', 'Johnson'], ['jenkins46', '9346', 'Mary', 'Jenkins'], ['smith79', '5079 ', 'Jamie', 'Smith'], []]
This is why if we used a simple for loop, it would only give us each list. If we use another for loop, within each of the lists, it will go through element by element and return their values, one by one.
So, when you run:
Username Identifier First name Last name
booker12 9012 Rachel Booker
grey07 2070 Laura Gray
johnson81 4081 Craig Johnson
jenkins46 9346 Mary Jenkins
smith79 5079 Jamie Smith
But, what would happen if we only wanted to print one line?
For this, we will use the next function. What this does is return the next item of an iterable (In this case a list). As a demonstration, if we create a list with values 1,2,3,4,5 and use next for each one, we will have the following result:
list1 = [1,2,3,4,5]
num = next(list1)
print(num)
num = next(list1)
print(num)
num = next(list1)
print(num)
num = next(list1)
print(num)
num = next(list1)
print(num)
>>>
1
2
3
4
5
So, for the first row of our csvreader:
import csv
file = 'username.csv'
firstrow = []
with open(file, 'r') as csvfile:
csvreader = csv.reader(csvfile)
firstrow = next(csvreader)
print(firstrow)
>>> ['Usernamel', 'Identifier', 'First name', 'Last name']
And applying a for loop:
import csv
file = 'username.csv'
first row = []
with open(file, 'r') as csvfile:
csvreader = csv.reader(csvfile)
firstrow = next(csvreader)
print(firstrow)
for field in first row:
print(field, end=' ')
>>> Usernamel Identifier First name Last name
Writing to a CSV file
Shoutout to Mike Driscoll on X
The method used to write to csv files is actually similar to csv.reader. For write operations, csv.writer is used.
What this does is create a csv.writer type object, to which we enter rows through the methods writerow, which writes the text entered as a single line and writerows, which writes large numbers of lines as long as they are written each one like a list.
So, if we take an empty csv file like music.csv, we want to write a table with three columns:
- One for the song.
- One for the artist's name.
- One for the album to which the song belongs.
Then, we will write all the lines belonging to these fields.
So, if we write the code:
import csv
file = 'music.csv'
fields = ['Song','Artist','Album']
rows = [['Billie Jean','Michael Jackson','Thriller'],
['Purple Rain','Prince','Purple Rain'],
['Careless Whisper', 'George Michael', 'Wham!, Make It Big'],
['Born in the USA','Bruce Springsteen','Born in the USA']]
with open(file, 'w') as filetowrite:
csvwriter = csv.writer(filetowrite)
csvwriter.writerow(fields)
csvwriter.writerows(rows)
We can see that just like for read operations, we use open to open the file, with the difference that now we put 'w', since we will perform a write operation.
Then, we create the csv.writer file by putting the file as a parameter and finally, to write an individual line (The one with the factors set) we use writerow.
Then, following the format of lists as elements within a list, we write the rows with the song data with writerows. Then if we verify the file:
Song,Artist,Album
Billie Jean, Michael Jackson, Thriller
Purple Rain,Prince,Purple Rain
Careless Whisper,George Michael,"Wham!, Make It Big"
Born in the USA,Bruce Springsteen,Born in the USA
Write and read Dictionaries in a CSV File
Shoutout to GeeksforGeeks
Just as we can write new lines to a file with csv.writer and writerows, we can also write the information in the form of dictionaries, where the name of the column would be the key and the value in that row would be the value of the key.
The way we do this is through csv.DictWriter, a function that creates an object of type csv.DictWriter, where we will take as attributes the file and a list with the labels that we will place on the columns in the header.
If we look at this in the following example:
import csv
dictionary = [{'Song': 'Billie Jean', 'Artist': 'Michael Jackson', 'Album': 'Thriller'},
{'Song': 'Purple Rain', 'Artist': 'Prince', 'Album': 'Purple Rain'},
{'Song': 'Careless Whisper', 'Artist': 'George Michael', 'Album': 'Wham!, Make It Big'},
{'Song': 'Born in the USA', 'Artist': 'Bruce Springsteen', 'Album': 'Born in the USA'}]
fields = ['Song','Artist','Album']
file = 'music.csv'
with open(file, 'w') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames = fields)
writer.writeheader()
writer.writerows(dictionary)
We can see that The data belonging to the rows is now designated as dictionaries, where the field name will be the key. In addition to this, we notice that the name of the fields is placed in a separate variable.
This is because when using csv.DictWriter, our new object must not only take the name of the file, but we must also designate the name of the fields that will go in the header in fieldnames.
Finally, if we want to write the header or the first line containing the column labels, we use writeheader().
And for the rest of the lines, we use writerows as in the conventional csv.writer.
Looking at the music.csv file with our text editor:
Song,Artist,Album
Billie Jean, Michael Jackson, Thriller
Purple Rain,Prince,Purple Rain
Careless Whisper,George Michael,"Wham!, Make It Big"
Born in the USA,Bruce Springsteen,Born in the USA
Now, if we wanted to read this information in the same way it was written: Dictionaries, we only have to use the csv.DictReader function, which only takes the file as a parameter.
With the following example:
with open('music.csv', newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
print(row['Song'], row['Artist'], row['Album'])
We can see that with DictReader the DicitReader type object is created, we only had to enter the file name. Then, with a for loop, we loop through each dictionary.
So to get the values, we just need to enter the name of the respective keys. Finally, we would obtain:
Billie Jean Michael Jackson Thriller
Purple Rain Prince Purple Rain
Careless Whisper George Michael Wham!, Make It Big
Born in the USA Bruce Springsteen Born in the USA
Note: The parameter newline='' is used since the CSV module has its own way of creating new lines automatically, leaving the default parameter '\n' when opening it would only create additional problems.
Finally, we put the knowledge acquired in File Handling to the test to start working with more complex file types. After this post, you already master the management of csv files and you can use them for any program you want. Whether as a database, dataset for artificial intelligence or other tables, you will know how to use it perfectly.
In this way, to have a smooth progression, in the following chapters we will see the handling of other types of files such as PDF files, but not before seeing some examples.

csv.Reader(newarticle)
Shoutout to Real Python
En este artículo encontrarás:
- Introducción
- ¿Qué es el módulo CSV?
- Leer archivos con el módulo OS
- Escribiendo en un archivo CSV
- Escribir y leer Diccionarios en un Archivo CSV
Bienvenidos de nuevo a otra edición de Coding Basics. Tras haber estudiado en detalle y puesto en práctica el manejo de archivos con la instrucción open y el módulo os, ya podemos hacernos cargo de problemas más complejos.
En este caso, te presento un módulo usado para manejar un tipo de archivo muy usado para la creación de datasets, colecciones inmensas de datos que podemos importar para obtener información promedial importante, el csv.
Es por esto que en este post veremos el módulo csv, después del cual serás un experto a la hora de manejar la estructura de datos de archivos con esta extensión
¡Comencemos!
¿Qué es el módulo CSV?
Shoutout to Python in Plain English
Antes de poder comprender que es el módulo CSV, debemos de entender que es un archivo CSV.
CSV o Comma Separated Values es un tipo de extensión que se refiere a archivos que almacenan información tabular, es decir, datos que se encuentran en tablas, como se puede ver en la siguiente imagen:

Shoutout to and Pixabay.com
Estas tablas se distribuyen en columnas (Las celdas verticales) y filas (celdas distribuidas en forma horizontal). Así, cada línea del archivo CSV representará una fila, donde irán los datos separados por comas, que denotarán la cantidad de columnas. De aquí su nombre: Valores separados por coma.
Lo que hace tan populares a los archivos csv es el hecho de que nos permiten organizar y almacenar grandes cantidades de información a la que podemos acceder con facilidad. Entre sus usos más populares tenemos a las bases de datos (Ej: MySQL) y el manejo de spreadsheets (Si, como las que usamos en excel).
Es por la demanda del manejo de archivos csv que muchos lenguajes de programación tienen módulos built-in dedicados a estas operaciones. En el caso de Python, este módulo se llama csv.
De la misma forma que open y algunas de las funciones de os nos permiten manejar ciertos tipos de archivos, csv nos permite realizar gran cantidad de operaciones con archivos csv, como lo son:
- Leer archivos CSV.
- Escribir datos en archivos CSV.
No solo esto, sino que también podemos añadir excelentes funcionalidades a nuestros programas, dándonos la posibilidad de:
- Almacenar emails es nuestros archivos csv.
- Escribir diccionarios en archivos csv.
Primero, veamos la operación más básica de todas: La lectura.
Leer archivos con el módulo OS
Shoutout to GeeksforGeeks
Si observamos el siguiente archivo, llamado username.csv, tendremos los siguientes datos (Si lo abrimos con el bloc de notas):
Usernamel, Identifier,First name,Last name
booker12,9012,Rachel,Booker
grey07,2070,Laura,Grey
johnson81,4081,Craig,Johnson
jenkins46,9346,Mary,Jenkins
smith79,5079,Jamie,Smith
Ya sabemos que las comas actuan como las líneas de separación entre columnas, mientras que cada línea será una fila. Ahora, si queremos leer un archivo csv, tendremos en cuenta como la instrucción más importante a csv.reader
Lo que hace csv.reader es crear un objeto de tipo csv.reader, el cual es un iterable del cual podemos obtener información como si fuera una lista. En este caso, cada elemento sería una lista con los valores de cada línea.
Si aplicamos esto en código:
import csv
file = 'username.csv'
rows = []
with open(file, 'r') as csvfile:
csvreader = csv.reader(csvfile)
for row in csvreader:
rows.append(row)
for row in rows:
print('\n')
for col in row:
print("%s"%col, end=" ")
Aquí, podemos observar que se crea una variable file con el nombre de archivo y creamos una lista vacía para extraer los valores de las líneas del archivo csv.
Si queremos leer un archivo csv, debemos de abrirlo igual que los archivos txt, donde usamos open con el nombre del archivo y 'r' (Para indicar que vamos a leer) como parámetros. Luego, usamos el csv.reader para crear el objeto tipo csv.reader a partir del archivo csv abierto.
Una vez hecho esto, simplemente aplicamos un ciclo for al objeto csvreader y de el extraemos cada línea, añadiéndola a la lista.
El ciclo for anidado (Un ciclo for dentro de otro ciclo for) se emplea para separar las columnas y filas. Esto debido a que la lista rows se vería así:
[['Usernamel', ' Identifier', 'First name', 'Last name'], ['booker12', '9012', 'Rachel', 'Booker'], ['grey07', '2070', 'Laura', 'Grey'], ['johnson81', '4081', 'Craig', 'Johnson'], ['jenkins46', '9346', 'Mary', 'Jenkins'], ['smith79', '5079', 'Jamie', 'Smith'], []]
Es por esto que si usaramos un simple ciclo for, solo nos daría cada lista. Si usamos otro ciclo for, dentro de cada una de las listas, se recorrerá elemento por elemento y nos devolverá los valores de estos, uno por uno.
Así, al ejecutar:
Usernamel Identifier First name Last name
booker12 9012 Rachel Booker
grey07 2070 Laura Grey
johnson81 4081 Craig Johnson
jenkins46 9346 Mary Jenkins
smith79 5079 Jamie Smith
Pero, ¿Qué pasaría si solo quisieramos imprimir una línea?
Para esto, haremos uso de la función next. Lo que hace esta es retornar el siguiente item de un iterable (En este caso una lista). Como demostración, si creamos una lista con valores 1,2,3,4,5 y usamos next para cada uno, tendremos el siguiente resultado:
list1 = [1,2,3,4,5]
num = next(list1)
print(num)
num = next(list1)
print(num)
num = next(list1)
print(num)
num = next(list1)
print(num)
num = next(list1)
print(num)
>>>
1
2
3
4
5
Así, para la primera fila de nuestro csvreader:
import csv
file = 'username.csv'
firstrow = []
with open(file, 'r') as csvfile:
csvreader = csv.reader(csvfile)
firstrow = next(csvreader)
print(firstrow)
>>> ['Usernamel', ' Identifier', 'First name', 'Last name']
Y aplicándole un ciclo for:
import csv
file = 'username.csv'
firstrow = []
with open(file, 'r') as csvfile:
csvreader = csv.reader(csvfile)
firstrow = next(csvreader)
print(firstrow)
for field in firstrow:
print(field, end=' ')
>>> Usernamel Identifier First name Last name
Escribiendo en un archivo CSV
Shoutout to Mike Driscoll on X
El método usado para escribir en archivos csv es realmente similar al csv.reader. Para operaciones de escritura, se usa csv.writer.
Este lo que hace es crear un objeto tipo csv.writer, al cual ingresamos filas por medio de los métodos writerow, que escribe el texto introducido como una sola línea y writerows, que escribe gran cantidades de líneas siempre y cuando estas se escriba cada una como una lista.
Así, si tomamos un archivo csv vacío como lo es music.csv, queremos escribir una tabla con tres columnas:
- Una para la canción.
- Una para el nombre del artista.
- Una para el album al cual pertenece la canción.
Luego, escribiremos todas las líneas pertenecientes a estos campos.
Así, si escribimos el código:
import csv
file = 'music.csv'
fields = ['Song','Artist','Album']
rows = [['Billie Jean','Michael Jackson','Thriller'],
['Purple Rain','Prince','Purple Rain'],
['Careless Whisper','George Michael','Wham!, Make It Big'],
['Born in the USA','Bruce Springsteen','Born in the USA']]
with open(file, 'w') as filetowrite:
csvwriter = csv.writer(filetowrite)
csvwriter.writerow(fields)
csvwriter.writerows(rows)
Podemos ver que al igual que para operaciones de lectura, usamos open para abrir el archivo, con la diferencia de que ahora colocamos 'w', ya que realizaremos una operación de escritura.
Lueego, creamos el archivo csv.writer colocando el archivo como parámetro y finalmente, para escribir una línea individual (La que tiene los factores establecidos) usamos writerow.
Luego, siguiendo el formato de listas como elementos dentro de una lista, escribimos las filas con los datos de las canciones con writerows. Luego, si verificamos el archivo:
Song,Artist,Album
Billie Jean,Michael Jackson,Thriller
Purple Rain,Prince,Purple Rain
Careless Whisper,George Michael,"Wham!, Make It Big"
Born in the USA,Bruce Springsteen,Born in the USA
Escribir y leer Diccionarios en un Archivo CSV
Shoutout to GeeksforGeeks
De igual forma que podemos escribir líneas nuevas en un archivo con csv.writer y writerows, también podemos escribir la información en forma de diccionarios, donde el nombre de la columna sería la clave y el valor en esa fila sería el valor de la clave.
La forma en la que hacemos esto es por medio de csv.DictWriter, una función que crea un objeto de tipo csv.DictWriter, donde tomaremos como atributos el archivo y una lista con las etiquetas que colocaremos a las columnas en el header.
Si observamos esto en el siguiente ejemplo:
import csv
dictionary = [{'Song': 'Billie Jean', 'Artist': 'Michael Jackson', 'Album': 'Thriller'},
{'Song': 'Purple Rain', 'Artist': 'Prince', 'Album': 'Purple Rain'},
{'Song': 'Careless Whisper', 'Artist': 'George Michael', 'Album': 'Wham!, Make It Big'},
{'Song': 'Born in the USA', 'Artist': 'Bruce Springsteen', 'Album': 'Born in the USA'}]
fields = ['Song','Artist','Album']
file = 'music.csv'
with open(file, 'w') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames = fields)
writer.writeheader()
writer.writerows(dictionary)
Podemos ver que Los datos pertenecientes a las filas ahora se encuentran designados como diccionarios, donde el nombre del campo será la clave. Además de esto, notamos que se colocan justamente el nombre de los campos en una variable aparte.
Esto se debe a que al usar csv.DictWriter, nuestro nuevo objeto no solo debe tomar el nombre del archivo, sino que también debemos designar el nombre de los campos que irán en el header en fieldnames.
Finalmente, si queremos escribir el header o la primera línea conteniendo las etiquetas de las columnas, usamos writeheader().
Y para el resto de las lineas, usamos writerows como en el csv.writer convencional.
Observando el archivo de music.csv con nuestro editor de texto:
Song,Artist,Album
Billie Jean,Michael Jackson,Thriller
Purple Rain,Prince,Purple Rain
Careless Whisper,George Michael,"Wham!, Make It Big"
Born in the USA,Bruce Springsteen,Born in the USA
Ahora, si quisieramos leer esta información en la misma forma que fue escrita: Diccionarios, solo tenemos que usar la función csv.DictReader, que solo toma como parámetro al archivo.
Con el siguiente ejemplo:
with open('music.csv', newline='') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
print(row['Song'], row['Artist'], row['Album'])
Podemos ver que con DictReader se crea el objeto tipo DicitReader, solo tuvimos que introducir el nombre del archivo. Luego, con un ciclo for, recorremos cada diccionario.
Entonces, para obtener los valores, solo debemos introducir el nombre de las claves respectivas. Finalmente, obtendríamos:
Billie Jean Michael Jackson Thriller
Purple Rain Prince Purple Rain
Careless Whisper George Michael Wham!, Make It Big
Born in the USA Bruce Springsteen Born in the USA
Nota: Se usa el parámetro newline='' ya que el módulo CSV tiene su propia forma de crear nuevas líneas automáticamente, dejar el parámetro por defecto '\n' al abrirlo solo crearía problemas adicionales.
Finalmente, pusimos a prueba el conocimiento adquirido en File Handling para empezar a trabajar con tipos de archivos más complejos. Tras este post, ya dominas el manejo de archivos csv y los puedes usar para cualquier programa que quieras. Ya sea como base de datos, dataset para inteligencias artificiales u otras tablas, sabrás como usarlo a la perfección.
De esta forma, para tener una progresión suave, en los siguiente capítulos veremos el manejo de otros tipos de archivos como lo son los archivos PDF, no sin antes ver algunos ejemplos.
Thanks for your contribution to the STEMsocial community. Feel free to join us on discord to get to know the rest of us!
Please consider delegating to the @stemsocial account (85% of the curation rewards are returned).
You may also include @stemsocial as a beneficiary of the rewards of this post to get a stronger support.