Dear blockchain friends and Splinterlands fans,
With Spliterlands move to HIVE I was interested to see the immediate impact it had on the activities on the STEEM blockchain. I had no real idea of how big drop it would be, but I was impressed to see that the activities are down over 50%.
Please see the simple graph below. Each dot represents all operations per hour. I guess it goes without saying that Splinterlands move occurred around the time of that huge drop in the chart.
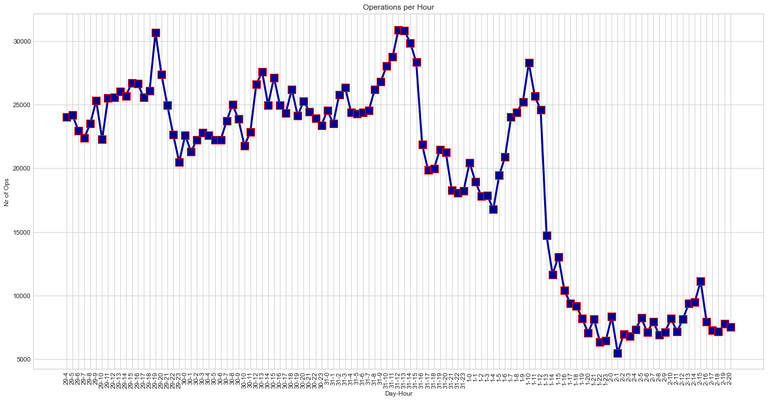
I put together a simple python script to check the number of operations on the STEEM blockchain, before and after Splinterlands move to HIVE. The data is between May 29 04:00 and June 2 20:00, UTC time.
I was using Beem to interact with the blockchain and matplotlib to render the graph.
Find below a copy of the script:
import time
import matplotlib.pyplot as plt
from datetime import datetime
from beem import Steem
from beem.blockchain import Blockchain
from beem.instance import set_shared_steem_instance
steem = Steem(['https://api.steemit.com'])
set_shared_steem_instance(steem)
chain = Blockchain()
def lineplot(x_data, y_data):
plt.style.use('seaborn-whitegrid')
plt.figure(figsize=(20, 10))
ax = plt.axes()
plt.plot(x_data, y_data, 'r-s', color = 'darkblue', linewidth=3, markersize=12, markeredgecolor='red')
ax.set_title("Operations per Hour")
ax.set_xlabel("Day-Hour")
ax.set_ylabel("Nr of Ops")
start_time = time.time()
x_hour = []
y_ops = []
current_block = 43777926
hour_tag = "0"
ops_count = 0
for ops in chain.stream(start=current_block, max_batch_size=50):
if hour_tag == "0":
hour_tag = "{}-{}".format(ops['timestamp'].day, ops['timestamp'].hour)
if "{}-{}".format(ops['timestamp'].day, ops['timestamp'].hour) == hour_tag:
ops_count += 1
else:
print("Processing day-hour: {}".format(hour_tag))
x_hour.append(hour_tag)
y_ops.append(ops_count)
ops_count = 1
hour_tag = "{}-{}".format(ops['timestamp'].day, ops['timestamp'].hour)
print("Execution time: {} seconds".format(round((time.time() - start_time),2)))
lineplot(x_hour, y_ops)
Updated the script with the max_batch_size after optimization hint from @crokkon. Also added a print statement inside the loop to provide some feedback during execution. And added a total execution time.
Thanks for reading!
I wish you all a lovely day/evening/night!
.
Yes, big drop. Steem is truly out of steam. 😜
Thanks for the optimization trick, haven’t used the Blockchain class a lot but will keep it in mind for the future. So that’s something you would use when fetching a big chunk of blocks from the past? Or it doesn’t hurt to run it for live streaming as well?
.
Thanks for that! I will play around with it when I get some time.
That is a pretty good drop.
Indeed, that’s pretty steep. 😀
Fun to see and I’m happy splinterlands is now linked to hive
I was curious about the same information yesterday. And I'm not smart enough to figure out how to get it. So it's extremely awesome that you posted this! Thanks for the great information 🤗🤗
You are welcome John! 👍
Interesting content and very clear graphics. But I confess that I was more surprised by how you made the script in python. Already this week I went into the study of data analysis and api consumption with python. And since I'm in this community I will investigate to practice with Havi's api. I'm learning constantly and by chance these are the study topics of this week. If you have any advice well received and grateful I will be. Today I already visited Hive Developer Portal.
Thank you!
If you are using python you should definitely check out Beem.
See below the link to the documentation.
https://beem.readthedocs.io/en/latest/
hi, is everything ok with @dustsweeper?
@danielsaori
Thanks for the ping. Dusty is back up and running again.
When you run this script how long does it take to finish?
I honestly don't know the exact time, I left it running for quite some time. I also didn't run it in one go. I started out with a too-small time window so I ended up running 3-4 batches in total to get all the data.
I made some updates to the script, see above.
The optimization trick from @crokkon made a huge difference. I didn't re-run the whole thing, but I compared the speed, running with max_batch_size set to 50 or as initially, without it. It's a speed boost somewhere from 10-20 times.
Thank you I saw that improvement. But still it takes a long time hahaha I didn't know :)
Sehr spannend :) Very interessting. is this good for us?
If we are talking about the hive blockchain I think it's great that Splinterlands moved. It was one of the most popular dapps on steam, so it's big news.
Great :)
Congratulations @danielsaori! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
You can view your badges on your board And compare to others on the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @hivebuzz:
Support the HiveBuzz project. Vote for our proposal!
@danielsaori did @dustsweeper halt again?