In my last dev post I promised to review some of the data I've been looking at with regard to increasing hive-related web and api server traffic. First I'll cover traffic to hive.blog, then move on to api.hive.blog.
Increase of web page requests to https://hive.blog
Below is a graph of network traffic to https://hive.blog. The important graph to look at is the top one that starts at around 10 million bits per second and ends around 26 million bits per second. This is the amount of incoming traffic requests to fetch web pages on the site.
Note this graph doesn't show traffic from API calls to api.hive.blog requests (I'll show that in a separate graph), this graph is only showing increased traffic to the hive.blog web site.
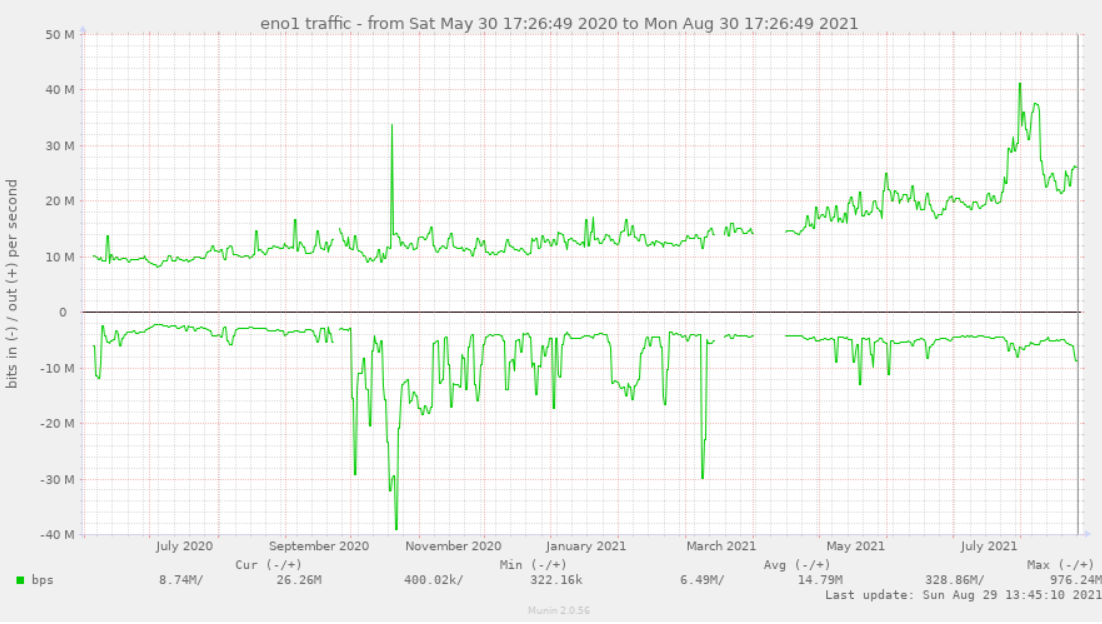
We can see that hive.blog has had a slow but steady traffic increase starting from when we first starting collecting this data (late May in 2020). By late April of 2021, we had about a 30% increase (13Mbps incoming from a starting point of 10Mbps) over an 11 month period. Next we see that growth has dramatically accelerated to where we've hit 26Mbps as of the end of August (about 2x gain over 4 months).
What's that spike to 30-40M?
You might be wondering what that spike in early August was. I was also curious about that, and I discovered that it was google's search bot indexing all our web pages (yes, it went on for a couple of weeks). I'm no expert when it comes to SEO, but I suspect that is a good sign for future organic searches from google's search engine.
After googlebot finished indexing the site, you can see the graph has returned to its previous trend line.
Cloudflare data
According to our Cloudflare control panel, in the past 30 days, hive.blog has had 2.46 million visitors, 231.56 million requests, and served up 19TB of data. During July, by comparison, it served up 16TB of data (I don't have the other numbers to compare against).
Increased traffic to api.hive.blog
Api.hive.blog is one of several Hive API servers that provides data to Hive-based apps (including hive.blog). Below are some spreadsheets showing how api traffic has increased recently.
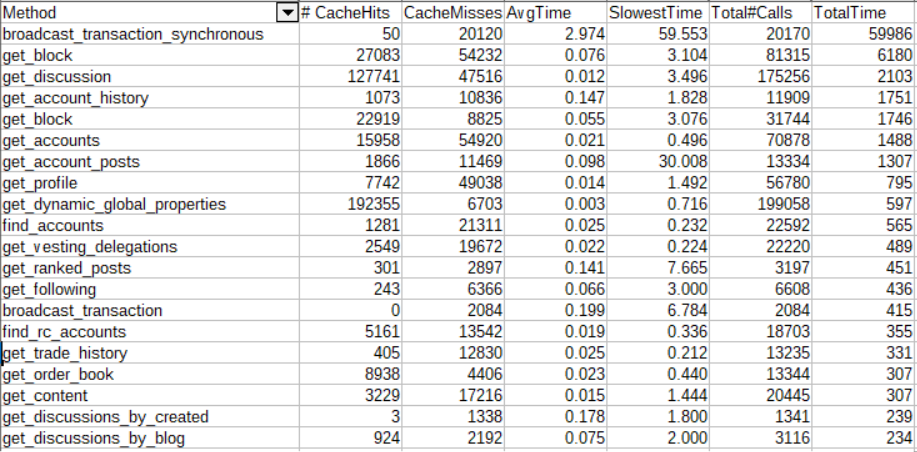
On July 28th (around the time api servers started getting strained by splinterlands sudden growth), one hour of API traffic (ranked by overall time consumed by each type of API call) looked like this:
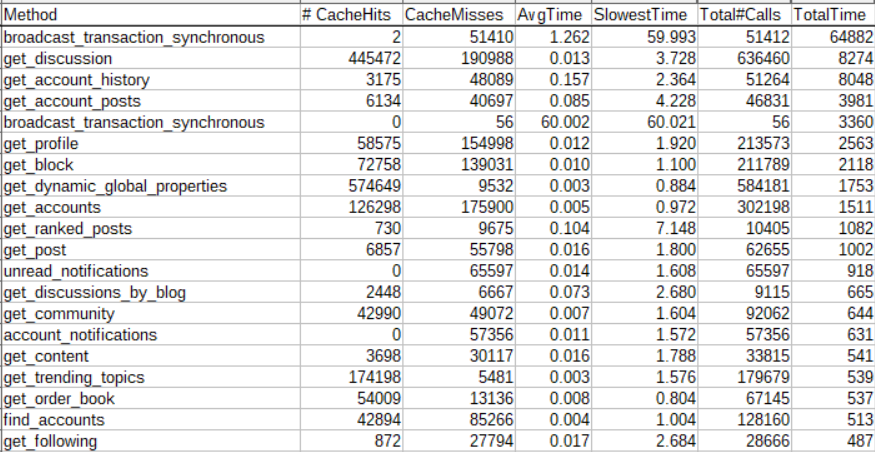
As of yesterday, one hour of traffic around the same time looks like this:
Synchronous broadcast traffic still increasing
The first thing to note is that despite most Hive apps changing to use the more efficient broadcast_transaction api call, we still are seeing an increasing number of "bad" broadcast_transaction_synchronous calls (increased from 20K/hr to 51K/hr in the past 30 days) . Presumably this is largely from bots playing Splinterlands.
Fortunately, this increase isn't posing much of a problem now, as those calls are all being directed to a separate hived server now, preventing those slower calls from choking out all the other API calls. And we can see that this separation is also beneficial for the synchronous calls as well, so much so that even though traffic has more than doubled, the average time to process a synchronous call has decreased from 2.97s to 1.26s.
But this is worthy of note for other API server nodes: if you haven't yet setup a dedicated hived node to handle your synchronous traffic, your node could be in for trouble in the near future. Note that the easiest way to do this is just run an extra lightweight consensus node (no need for an account history node to process transactions).
Social media-specific traffic also increasing dramatically
When you visit a post on hive.blog, it makes a call to get_discussion to get the post contents and comments. In the past 30 days, calls to get_discussion have increased from 175K/hr to 636K/hr (~3.6x increase). Another common social media API call is get_ranked_posts which is used for things like showing the list of trending posts. We can see that calls to this increased from 3917/hr to 10405/hr (~2.6x increase).
Many API calls are faster, despite the increased traffic
Despite the increased traffic to the node, we can also see that many of the API calls are faster than they were. For example, get_following has an average time of 0.017s vs a previous time of 0.066s (~3.9x faster). This is just another benefit of separating out the synchronous calls that were previously choking performance of the other API calls.
Plenty of room to grow
The most interesting thing we can see from looking at this data is that despite API traffic having nearly tripled over the past 30 days, the effective loading on the API server is pretty minimal, and in fact with the reconfiguration of the node to separate out the "bad" synchronous calls, the node is actually performing faster than it did before the traffic increase.
Great stats, thank you for sharing. Indeed all frontends saw spike in crawling from mid July. More pages crawled means we will rank for more keywords and canonical linking across apps will increase that crawling across every app. 🚀
Sure, note that Ecency.com is launched 6 months later after hive.blog, so we are following behind 😊
I am not 100% sure but I think Cloudflare shows stats of every subdomains as well. Including api.hive.blog, images.hive.blog (in our case, rpc.ecency.com, images.ecency.com), etc. If anyone knows for sure would be interesting to know ways to filter out individual subdomains from Cloudflare analytics...
You can't filter per subdomain iirc, but it definitely will show you stats from all subdomains.
Right, so RPC nodes basically have bots and all other apps which use them combined. And imagehoster instance as well, still quite impressive numbers and these will continue to grow 🚀
When content is published each frontend/application adds their name into metadata, that metadata then parsed by all apps accessing that content. Metadata then mapped to canonical link from
@hiveio/hivescriptnodejs package. So all front-ends point canonical link to original application that content was published from.Congratulations @blocktrades! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
Your next target is to reach 4500 comments.
Your next payout target is 1300000 HP.
The unit is Hive Power equivalent because your rewards can be split into HP and HBD
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Check out the last post from @hivebuzz:
All this data is an excellent signal for the future of Hive and I believe that improvements will be needed on the hive.blog to allow users to be able to navigate the platform optimally
It is great to see hiveblog doing fine and so are some other front end pages used a lot. Competition is progress. Hive has a (great) future because of these tools and games of course,
Very nice to see the steady climb since inception of Hive.blog. No super spikes other than that google bot activity, so that bodes well for Hive in the future. The recent slow but steady rise in Hive price is nice as the rises seem to take a pause and make sure things are still going good, then start to rise again. it will be interesting to see what happens as the year continues to progress.
The situation in HIVE seems to be growing, thanks for the data you provide
fantastic! 2.4 million is much more than I thought
Really interesting stats, i would be more happy if the Google seo activity was a blip rather than a Spike in activity. :)
Thank you for the providing the full picture like this. It’s good to see that we have room to scale and people like you and @goodkarma are thinking ahead about where we need to go from a technological stand point. 🙌
I wonder how many users could Hive support after all these improvements. I know a precise number is difficult to determine but something in the neighborhood would be cool
There's no simple number, because it could depend a lot on what tasks are done by users. In particular, we're still currently getting a lot of synchronous broadcast calls, and if we deprecate support for those, that would enable a huge amount of scaling.
Out of curiosity, is there a way to live stress-test to slowly ramp up and see what kinds of volume are possible?
We could definitely run tests like this, but I'd prefer to do it on a testnet rather than the mainnet :-)
Understandable for sure. Does it replicate 1:1?
I once had a poorly received idea to stress-test transactions by using a large group of accounts all sending some HBD/HIVE amongst themselves every 3-odd seconds, would this work?
That would test transaction processing, but that's really fast now that most of the front ends use broadcast_transaction instead of broadcast_transaction_synchronous
Yes I know - I am just wondering just how fast it can be. I am not sure how accurate blocktivity is these days, but I think we could do better. Not sure if it is still valid, but once upon a time it would have been good publicity - especially considering that all the transactions are free (for the user)
Yes, it would be interesting to see how fast it could be, especially since we know we're much faster now as we're using broadcast_transaction calls.
But I still think such a test is best done on a testnet first. Some of the witnesses should be able to arrange for a test like this.
There are real long term tradeoffs associated with blockchain bloat when coins decide to run a bunch of useless transactions on their mainnet just to rank higher on a web page. EOS became incredibly painful to sync up after a while because of all the spam transactions and it wastes disk space as well, making it more expensive to host an EOS node.
Now, we could do a short test just to rank on the "Record" portion of blocktivity.
But before we do that, we should test on a testnet, find and fix any potential bottlenecks, and only then go for a "record breaker". There is one known performance bottleneck associated with the thread locking that I already plan to fix in hived (in the next couple of months), and it might put an upper limit on how many transactions we could currently handle.
By the way, I took a look at blocktivity.info (hadn't been there in a while) and it reports Hive traffic is up 27% this week. Hive is at #7 there now (EOS is at #6).
Nice boost, Around that time you saw an increase was when Google was updating their algo which now pulls headlines from H1 tags on blog sites. Could very well be the reason why we saw a little bit of a bump as I know many have started using those H1 tags etc over the mark up language. Lots of growth but still so much more to go.
Does it still not make sense to run some type of ad system on Hive itself to generate revenue to pay for server costs etc?
Good to know, thanks!
I don't think so, because I think the work involved could easily match the revenue. Once the site gets big enough, it could make economic sense then.
But I really don't think ads should be Hive.blog's future: I hope to break away from such economic concepts entirely. But this is an issue that is up to each frontend operator to decide for themselves.
Thanks for sharing,these is a great start.Very nice to see the steady climb since inception of Hive.blog. No super spikes other than that google bot activity, so that bodes well for Hive in the future.
Epic! And there is probably loads more that can be done to make things even faster too. We're going to have no problem scaling for the forseeable future.
I'm really looking forward to HAFs official release!
!PIZZA
Communities I run: Gridcoin (GRC)(PeakD) / Gridcoin (GRC) (hive.blog)| Fish Keepers (PeakD) / Fish Keepers (hive.blog)
Check out my gaming stream on VIMM.TV | Vote for me as a Hive witness! and Hive-engine witness!
My primary goals for Hive are very simple:
We'll do a few other things along the way, but those two goals act as guidelines for everything else we're doing.
And you're right, we've got some near-term plans to pre-emptively improve scaling further. I don't have any numbers to backup my engineering intuition yet, but I expect the new HAF-based account history app to be able to handle far more traffic than a hived node can. And if I'm right, this will dramatically scale up the number of financial applications that can operate on Hive without requiring any new infrastructure servers.
@blocktrades! I sent you a slice of $PIZZA on behalf of @shmoogleosukami.
Did you know you can earn $VFT through the PIZZA farm? (3/20)
would be nice if hive would have a system in place to make out that traffic money. Like advertisements for "readers" not users.
I know, impossible without a standard all front ends could sign up for. But that would be something WEB3 needs.
fully Decentralized advertisements don't work, i know that too :P But some bid and accept platforms would be nice. Some cut for front ends, rest ends up in burns.
The network burned 500K Hive in the last week alone, just from the Hive->HBD conversion operation. And Splinterlands burned around 170K Hive creating new accounts.
And we're probably on track to do something similar in the coming week. It's big burn rate (total value burned at Hive price of $0.56 USD is $375K USD per week ), far more than I think we could ever expect from advertisements, at least in the near term. And that number is not including effective removal of available Hive supply due to HDB stabilizer.
Admittedly we shouldn't count on that burn rate to last forever, but in one week I think we've burned more than Steemit was earning on its ad revenue for an entire year (and that's revenue BEFORE expenses, which I suspect made them "profit neutral").
OMG,
That news are awesome :D
Way better than i would expect.
Insane if we think about its 0,5%+ of total supply :O
Really Insane!
This looks likes like a very healthy growth pattern, indeed, and as they say, what's good for the goose is good for the gander. This bodes well for everyone involved with the platform and provides an excellent proof-of-concept for future web 3.0 development. Excellent work compiling this information.
Congratulations @blocktrades! Your post has been a top performer on the Hive blockchain and you have been rewarded with the following badge:
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Good job, great stats and thank you for sharing!
The rewards earned on this comment will go directly to the person sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
More free marketing... in 3 words.
Thank you for sharing the graph
Excellent information, good that everything is working perfectly fine, thanks for sharing.
How can we interact in discord?
test
Yep, I think it's only a matter of time.
Hiya, @blocktrades. Nearly an hour ago, you received 1,000 Hive from me :
Received 1000.000 HIVE from yahia-lababidi f2d4e91b-24cd-4e50-98ad-c2b6869d616e
which has not transferred to my Litecoin wallet, yet.
I'm writing because I received an email from you, for the first time, asking for my passport information, my home address, and a photograph all of which I promptly provided.
Hoping to hear back from you, soon. Much appreciated, Yahia
Interesting blocktrades
I should add that, since I made my post, my transfer has gone through. Thank you, @blocktrades, for all the good work that you do. 🙏