
Below is a list of Hive-related programming issues worked on by BlockTrades team during last week or so:
Hived work (blockchain node software)
Cli-wallet signing enhancement and bug fix
We’ve enhanced the command-line interface wallet to allow it to sign transactions using account authority. We’re currently testing this.
We fixed an erroneous error message from cli wallet that could occur when calling list_my_accounts: https://gitlab.syncad.com/hive/hive/-/issues/173
Performance metrics for continuous integration system
We’re also adding performance metrics to our automated build-and-test (CI) system: https://gitlab.syncad.com/hive/tests_api/-/tree/request-execution-time
These changes are also being made for hivemind tests:
https://gitlab.syncad.com/hive/tests_api/-/tree/request-execution-time
This work is still in progress.
Fixed final issues associated with account history and last irreversible block
We also completed a few fixes related to account history and the last irreversible block and added some new tests:
https://gitlab.syncad.com/hive/hive/-/merge_requests/275
Continuing work on blockhain converter tool
We’re also continuing work on the blockchain converter that generates a testnet blockchain configuration form an existing blocklog. Most recently, we added multithreading support to speed it up. You can follow the work on this task here: https://gitlab.syncad.com/hive/hive/-/commits/tm-blockchain-converter/
Hivemind (2nd layer applications + social media middleware)
Dramatically reduced memory consumption
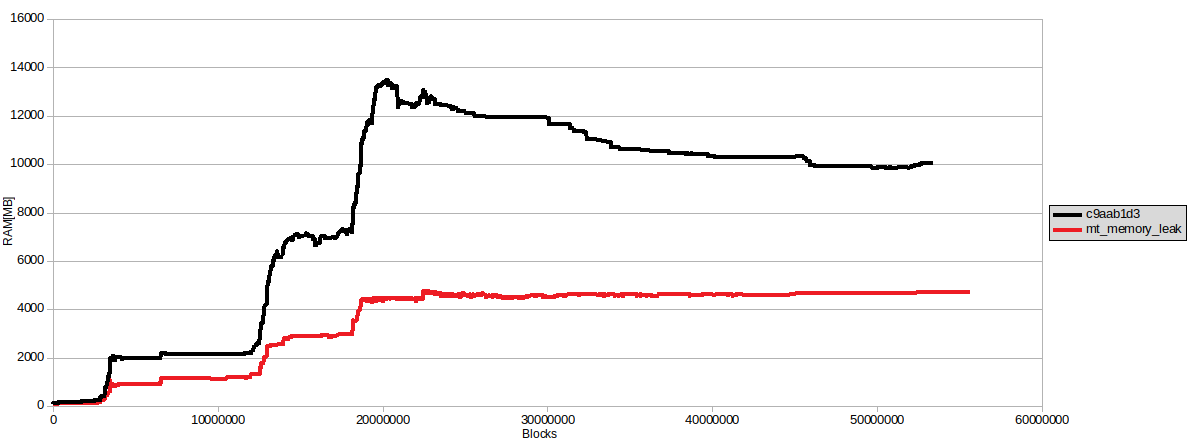
We’ve made some progress on hivemind’s memory consumption issue. While it appears the leak issue is gone (probably fixed when we pinned versions of library dependencies used by hivemind), we still saw some higher-than-desirable memory usage during massive sync. We made several changes (queues used by consumer/provider were too long, used prepared queries where possible, explicitly cleared some python containers) to reduce this number and were able to reduce hivemind’s peak memory usage from over 13GB to just over 4GB. Changes are here: https://gitlab.syncad.com/hive/hivemind/-/commits/mt-memory-leak/
Here’s a graph of memory usage before and after the above changes:
Optimized update_post_rshares down from 11.4hrs to ~15m
We’re also continuing work on optimizing the update_post_rshares function that is executed after massive sync. Originally this function took 11.4 hours and we’ve reduced it to around 15 minutes by adding an index. Initially this index was pretty large (around 25GB), but we’ve also made other optimizations to reduce database writes wrelated to posts that paid out during massigive sync, and this has not only reduced IO usage, it also reduced the size required by this index. It’s also worth noting that this index can be dropped after update_post_rshares has completed.
Made hivemind shutdown time configurable when it loses contact with hived
Hivemind had an annoying habit of shutting down completely if it lost contact with the hived node that it was using to get blockchain data (it retried 25 times, then shutdown). This was problematic because this meant that temporary network disruptions could leave hivemind dead in the water. We’ve added a new option, --max-retries (or –max-allowed-retries, to be determined) which will default to a value of -1 (infinitely retry).
We’re also moving hivemind tests out of the tests-api repo to hivemind repo as part of some general restructuring of the test system.
Hive Application Framework (HAF)
Our primary developer for the forkresolver code in HAF is back as of yesterday and has resumed work on this project. Our next step is to begin developing some sample applications for HAF. I hope to be able to officially release HAF in about a month. Once we have HAF as a foundation, we can begin building our 2nd layer smart contract system on top of it.
What’s next?
For the rest of this week, we’ll be focused on testing associated with above tasks. In the week thereafter, we’ll begin planning what tasks will be scheduled for hardfork 26 as well as other tasks that we plan to complete which can be released sooner (as they don’t require protocol changes). Of such non-hardfork tasks include development of common-use HAF applications (e.g a HAF application to generate tables about Hive accounts and custom_json).
Speed up, resource down, nice.
Thank you BT and team!
Great job, as always. I'm especially impressed with optimization results on both memory consumption and sync time.
Do you have an idea for your first app built on top of HAF? If not, consider rewriting Wise as it still seems to be quite useful. As far as I remember you were using it to delegate your votes :)
Best to rewrite app would be its original author.
(See well known curse in Polish: "Obyś w cudzym kodzie grzebał!" ;-) )
I'm pretty sure it won't happen :P And by "rewriting" I mean "write a new app on top of HAF with the same idea in mind" ;)
@engrave @gtg
Well.... you never can be certain for sure what will happen ;) We stopped its development because of lack of funding and also partially lack of time.
Also... in the meantime... I've figure out, that we probably could done better job at trying to contact a target audience - whales.
A lot happened in the meantime, now we are Hive, we have DHF, and ... since the last HF there's a lot of change related to curation. Well, changes small, but their impact is significant. You no longer need to compete with bots or try front running. Human honest curators that are active enough (daily) can just vote whatever they like without losing on curation just because they are late. IMHO, currently it's all about discovery and that's a challenge to improve it.
... and by the way - It's great to see you around! :-)
That is quite good achievement. There should be more dedicated, enthusiast and passionate programmers/developers like you. Softwares in general would be much more optimized.
Congratulations @blocktrades! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
Your next payout target is 1235000 HP.
The unit is Hive Power equivalent because your rewards can be split into HP and HBD
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Wait a min!
isn't HAF something like React framework to build apps using the resources that framework gives?
I know both of they aren't work the same way. However, as a beginner programmer, what I know is frameworks are something bigger than libraries (such as hive-js library). So, I assume we can build Dapps using the given resources of HAF (correct me if I am wrong).
Regardless, I am still wondering how HAF will make smart contract possible to build on Hive blockchain (as 2nd layer)?
HAF is a framework for building apps, but it is quite different from Flux/React, because flux/react is focused on simplifying creation of frontend apps, whereas HAF is focused on building backend apps that can easily process data from the Hive blockchain. In other words, you can build a dApp where the backend is based off HAF and your frontend UI is built on React/Angular/Flutter/etc.
HAF defines a way to easily build and manage SQL tables with processed forms of the blockchain data. The very base level of HAF does the job of injecting raw blockchain data into a SQL database and managing database reversions automatically in the case of a fork.
HAF will come with optional sets of pre-written code to do things like creating tables with Hive account data and APIs to manipulate those tables.
Our 2nd layer smart contract engine needs a way to efficiently get the raw blockchain data into its database and manage state changes in the case of forks. HAF will do all this work for it. And some of those optional pre-written modules for maintaining additional tables (such as a table of Hive accounts) will also be useful to the smart contract engine.
what you say here is true regarding React/Flux frameworks. what I understood before your explanation was/is the same thing. it all related to the back-end. Good job!
Regarding the 2nd layer smart contracts, it seems kinda complicated. However, Me, hive community, and hive developers are looking forward to more details about that.
Appreciate your efforts, and thanks for everything @blocktrades.
The rewards earned on this comment will go directly to the person sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
Always interesting to read your updates
Congratulations, @blocktrades Your Post Got 100% Boost By @hiveupme Curator.
@theguruasia Burnt 6.257 VAULT To Share This (20% Fixed Profit) Upvote.
Delegate @hiveupme Curation Project To Earn 95% Delegation Rewards & 70% Burnt Token Rewards In SWAP.HIVE
Contact Us : CORE / VAULT Token Discord Channel
Learn Burn-To-Vote : Here You Can Find Steps To Burn-To-Vote
I just stopped by to say thank you for all the work you put into blockchain, I'm sure in the future prices will appreciate that effort.
much wow
Faster and cheaper! nice!
HAF is a big thing, right? it feels like that
Yes, IMO, HAF is a very big thing.
Nice cant wait for it :)
What do you do when you have used 3 HIVE to create a community and it fails during user data preparation ? This tells me state error 504.
In any case, I have no return from my tokens and the server persists with a server error. Although I keep trying again.
Who do I contact for reimbursement ?
Que bueno amigos, yo apenas estoy conociendo cada día todo lo referente a las blockchain e compra y venta de criptomonedas. Todos estos temas son de gran interés porque es una invocación en el mercado. Por eso apoyo a todas las mejoras y actualizaciones en todas las plataformas. Se les quiere mucho amigos, felicidades por su trabajo.
When are you coming back online @blocktrades????
What happened?
Why blocktrades don't work?
It's working again they said!
I just checked, it looks like it's working again. Not sure what happened yesterday. Hive-Engine transfers were down for a bit yesterday too, maybe one of their bots went down?
Why blocktrades don't work?