This post describes the Jussi Traffic Analyzer software that we created to measure the performance of our production Hivemind node and some of the results we’ve recently obtained from it.
The intended audience is mostly Hive apps developers and API node operators, but if you're like me and sometimes you like to read something very techy even though it's hard to understand (I used to do this with Scientific America articles when I was kid), feel free to enjoy as well.
It’s important to note that this tool analyzes Jussi log files, so it’s not really useful for measuring third party API nodes (unless the node operator is willing to provide you with their logs, which is probably doubtful).
The tool generates two reports over any specified period of the log files:
analysis.csvwhich contains statistics on the different API callsslow_calls.txtwhich contains actual calls that exceeded a specified time to complete (for example > 2 seconds)
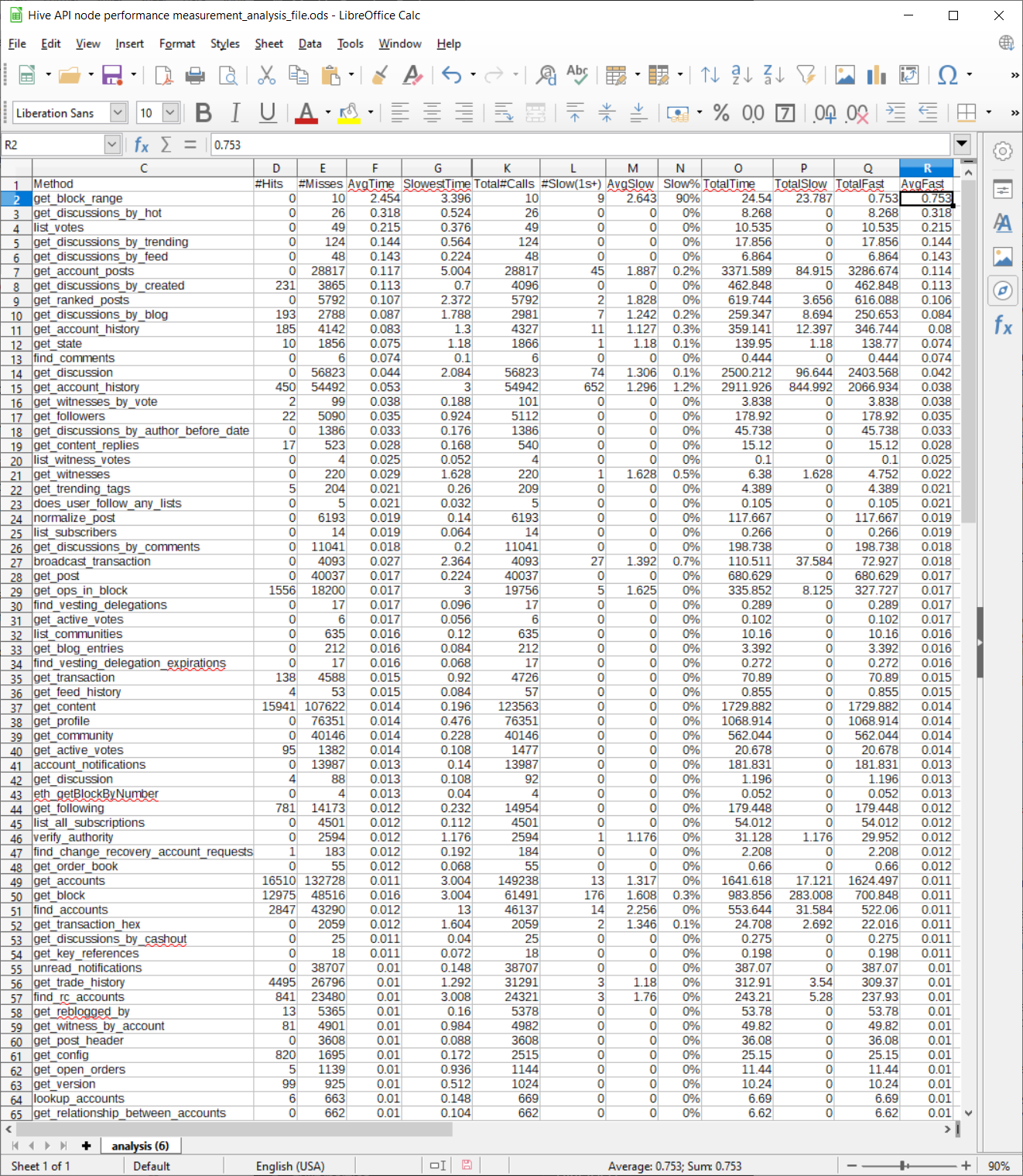
Overview of API call statistics file (analysis.csv)
The data in slow_calls.txt is self-explantory, so I’ll spend most of the time in this post discussing the format of the analysis.csv file.
Each row in the analysis file represents a specific type of API call (the first columns, there's actually 3 columns, although I only show one in the screenshot to keep it readable, identify what this API call is).
One thing to keep in mind, however, is that a single type of API call can result in quite different SQL queries inside hivemind, depending on the parameters passed to the call, so there’s still a lot of data being “averaged” together in this report. For example, the time required to make a call to get_ranked_posts can vary a lot depending on whether you’re asking for ranked by trending, hot, etc. Nonetheless, I think this data can still be quite useful for obtaining some intuitive feeling for the times required by various calls.
Here’s a screenshot of a sample analysis file (I’ll make the raw data file available in the mattermost Hive dev channel later today). This data was taken today from our production node over a two hour period, running with our latest hivemind optimizations. Note that this screenshot doesn’t show all the columns in the raw data file, I’ve selected ones of particular interest to discuss in this post.
- Hits is the number of jussi cache hits. Cache hits are generally low, because parameter values vary a lot and also because many of the responses to API calls change quickly (votes, in particular, can change the results for many API calls). So this data is mostly useful for optimization work when you're able to change the API itself.
- AvgTime is the average time of all the API calls of this type.
- SlowestTime is the slowest time recorded during the analysis period for this API call.
- Total#Calls is the total number of calls to this API node of this type of API call during the analysis period.
- Slow(1s+) is the total number of calls to this API node of this type of API call during the analysis period that take 1 second or more to complete.
- AvgSlow is the average time of such slow calls (so it will always be greater than 1s).
- Slow% is the percentage of the total calls of this type that take more than 1 second to complete.
- TotalTime is the total time consumed by adding up all the calls made for this API call. For example, if there were 100 calls and each one takes .1 s, then this value would be 10s.
Some notes about using these metrics
I use TotalTime to measure the overall loading impact of a particular type of API call on the server, although there are some exceptions to this rule, such as broadcast_transaction_synchronous, which has to wait for a block to complete so that the transaction can be included in a block, but doesn’t consume CPU while waiting. This is the single most important metric for determining how well a node can scale to handle more traffic.
I use SlowestTime, Slow, Slow% to investigate potential quality of service problems that might affect user experience (users don’t generally like to wait long to see results).
AverageFast is useful for knowing what you can normally expect from an API call when you exclude “outlier” calls that access “unusual” data (for example it would exclude timing data from a post with many thousands of comments). So this is a very useful metric for apps developers.
Notes on the sample data
After generating the two reports with the Jussi Traffic Analyzer, I import the analysis file into LibreOffice Calc or a similar spreadsheet program to analyze the data, then use AutoFilter so that I can sort on different columns.
In the screenshot shown, I’ve sorted by AvgFast time, and we can see that the API call that takes the longest time on average in all cases and in the “fast” case is get_block_range. This API call is served by hived, not hivemind, and you can see that it takes considerably more time than the average API call (the average “fast” time is .753s and the average time overall is 2.4s!).
One of the objectives of our work with the hived plugin that will feed data directly to a Postgres database is to speedup this time by having hivemind, rather than hived, serve this API call in the future (and not coincidentally, reduce the loading caused by hivemind sync time, because currently hivemind makes this call to obtain sync data from hived).
Using pghero to supplement analysis of node performance
In addition to the Jussi Traffic Analyzer, I also use pghero, an open-source web-based profiling tool for Postgres databases, to directly analyze the impact of various queries within hivemind’s database.
Pghero is particularly useful in isolating problematic SQL queries when a given hivemind API call is implemented using multiple SQL queries (either serially or by branching between possible query choices, which is quite common).
However, pghero can only report on times spent in database processing, so the Jussi Traffic Analysis tool is still very important for measuring overall performance, including the time spent by the python-based hivemind server process that communicates with hivemind’s database. And it can also measure the performance of hived-based API calls, which pghero cannot, since the processing of hived API calls doesn’t involve Postgres queries.
I understood everything as a non-dev, great job explaining. Where is the previous performance before all the upgrades? Need something to compare to.
I have some old files with previous data at various times in the past, of course, but the reporting format became more sophisticated with time as I learned more about the nature of the data, so it will take a little massaging to make a direct apples-to-apples comparison. Eventually I'm planning a proposal for the work we did, and I'll likely include an overview of that type of data with the proposal, so that people can more easily evaluate the quality of the work.
Congratulations @blocktrades! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPDo not miss the last post from @hivebuzz:
!wine
Cheers, @minnowspower You Successfully Shared 0.100 WINE With @blocktrades.
You Earned 0.100 WINE As Curation Reward.
You Utilized 2/3 Successful Calls.
WINE Current Market Price : 0.000 HIVE
Hi @blocktrades i have a question:
I think I read some time ago that the get_follower/ing calls will be served by hivemind and no more by the follow_api. Is it correct?
The follow api no longer exist? And all its methods are now served by the hivemind api? So also get_follow_count?
Thanks
get_followers/following are definitely served by hivemind, and have been for quite a while I think (as long as Hive existed, I believe, but not 100% sure without checking). But we've moved some other API functionality from hivemind to hived (reputation, notifications, and voting data) as part of Eclipse work to reduce memory usage by hived and improve API speed.
Yeah I know...great work and thank you for your answer!!
From my little experience, I noticed a huge improvement on the api.hive.blog node. Before that node was one of the worst, now it's the best :)
I think api.hive.blog has almost always had the strongest overall performance (because it was internally supporting several hiveminds and hiveds), but it also had the most traffic, so performance perceived by an individual user of the api server would often seem lower than the performance of a lightly loaded api server.
There could also sometimes be latency issues associated with when we served some of the data from outside it's primary data center while doing testing on experimental versions of hivemind.
With our recent changes, the large amount of traffic going there just doesn't load us much at all and we're serving with a single hivemind locally situated in the data center, so even perceived performance (responsiveness/low latency) should be very good.
Yes the performance is very good. Before the most common error i saw on my terminal was RPCError Request Timeout, now it's a lot better
Yes, that error typically indicates some form of excessive loading on the server when you see it (the other possibility can be to ask a question with a difficult answer, but we've speeded up the code to the point where it's hard to ask a question that is difficult enough to stump the server now).
thanks for the explanation, and good work!
Thanks
Though the complexity of this makes my head hurt a little, the transparency of your operations and education of the coders makes my heart feel good.
Thanks again for being a technology enabler and great blockchain citizen!
muy buen trabajo,lo felicito,espero contar con su voto y apoyo,necesito comprar un celular para trabajar aqui,no tengo,el computador se daño ,he publicada gracias a una amiga pero sin fotos,gracia samigo por ver si me ayuda
Thank you very much for motivating our publications, that keeps us activated to continue growing. Successes in your publications and cures, sincere wishes from Venezuela.