If you are a data junkie you should be on the Blockchain...
The Blockchain is one of the richest sources data around. People are putting financial transactions on it, playing games, blogging, selling digital art ...
We haven't even scratched the surface of how the data can be used (for good and bad), but the best thing about it is its accessible to all.
There is no better place to be if you are a budding Data Scientist or Researcher than surfing the many Blockchains.
Forget about the Titanic or Iris data sets!
Come to Hive and see what data is available!
... even write your Theses with real data from the Hive Blockchain!

... oh and did I mention you might get paid for it if you give something back to the Blockchain!
Tutorial Series on Blockchain Data
This is the first in a short series of posts to shine some light for the community and any budding Crypto Analysts to the rich data resource that is the Hive Blockchain.
The series will use the R Programming Language. If you want to code along, I will share all the code I use but it's aimed at more advanced users and introduces ideas and concepts for getting and visualising data, but really this is only the tip of the iceberg, the starting point.

As a long time practitioner of R I will also introduce some packages and tools along the way with a bit of history. All of the code will be available on Github.
...My language of Choice for Analysis...
![]()
R is a statistical programming language that has been used for many years by Data Scientists mainly for prototyping and research.
In contrast production applications have historically usually favoured languages like Java or Python.
I first came across R in 2006, and used it to produce some simulations for my Masters Thesis, it had a learning curve, wasnt always intuitive but once you got it you began to realise how powerful it could be if you spoke statistics. There was a package for everything and the community that had grown up around it ensured that if you wanted some bleeding edge statistical model it probably had an implementation in R.
The downsides were that it was buggy, inconsistent implementations, duplication, poor quality coding (not necessarily done by data scientists) and it was really slow for some calculations and didnt deal with big data very well.
It then went through a phase where many of these limitations were overcome and companies like Revolution Analytics (now part of Microsoft) began providing Enterprise flavours of R, which was far more robust and scalable.
One commercial organisation has emerged (R Studio) who have really nurtured and grown symbiotically with the R language and Userbase to provide Frameworks, Development and Open Source and Free Software to the Community. Their philosophy seems to me to be that of a rising tide lifts all boats and has to have worked for them, they are led by a Chief Scientist called Hadley Wickham who has pioneered some data science techniques and visualisation techniques that are now ubiquitous.
The story of the R language is a really is an interesting story.
Language of Choice for Data Science
In 2021, Data Scientists may favour a language like Python for development, features like Jupyter Notebooks have probably been one of the biggest innovations for Data Science and reproducible research in Python, but it's probably the speed and scalability of Python along with its more general use in Software Development that has pushed it ahead recently.
Hive

We have many options on Hive for interacting with Blockchain Data in different coding languages, in particular Javascript, Python and Ruby which give you the tools you need to interact with the Blockchain and build Dapps and access Blockchain data.
In addition we have data services like Hive-SQL which warehouses the Hive Blockchain Data and makes it available to the community to use in a relational database structure.
Back in the old days, there was a Blockchain called Steem which I wrote an R library and Tutorial series for and at the time I was hoping to get my R package on CRAN which is the Central Repository for Publishing R Packages. I went through the process (there is quite an extensive audit and requirement process to get published) but I have dug out the old code and updated it to work for Hive.
And with a bit more work I hope to get this package hiveRdata published to Cran so that it can be used for demos and "test" data as a replacement for standard datasets like Titanic and Iris.
Why Hive Data
Data is the new oil, or maybe the new asbestos depending on your job title.

- It is undoubtedly a valuable, scarce and sensitive resource.
The thing about public blockchains is that what goes on the blockchain stays on the blockchain.
Anyone can see it.
Even if its encrypted you might be able to infer things form transactions. Or one day in the future the encryption may become obsolete may not longer be secure. But ignoring all that if you are just looking for some data to explore, the Blockchain is gold.
- Hive is richer than most (becuase people actually use it!).
- A lot of the data is also text based so its really rich for Data Science and particular NLP related tasks.
- The Hive Blockchain has data products in development since 2016 which means services like HiveSQL and the packages like Beempy make the data really accessible for Analysis.
A Gentle Introduction to Blockchain Data - Trending Posts
To get started I am going to query the top 100 trending posts and visualise the results.
You can install the hiveRdata package from my github. If you do please star it!
To get the trending posts run the following command
library(hiveRdata)
trending <- getTrending()
The getTrending() function is just a wrapper for the Hive Appbase API to access data from a public node.
- It returns the top 100 posts.
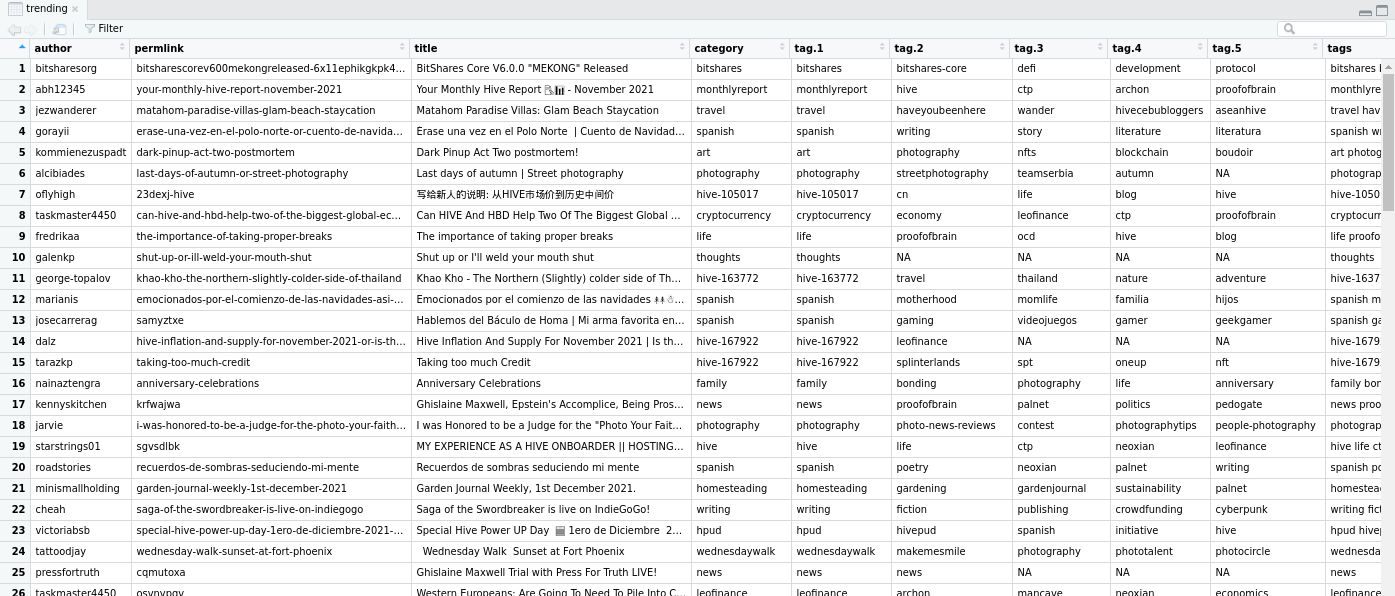
I use the R Studio IDE and you can see the top 100 trending posts in tabular format.
Visualise the Top 100 Posts
How can we visualise this?
Using a Visualissation package called ggplot2 the following command plots a histogram of the votes.
library(gglot2)
ggplot(trending, aes(x=votes))+geom_histogram()
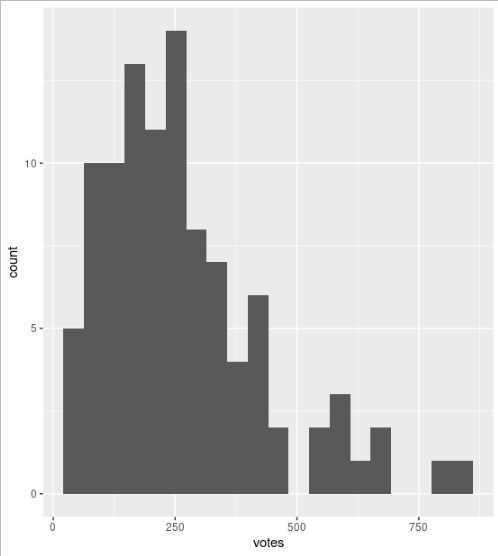
Thats it. 2 lines of code in R to visualise the top 100 trending posts.
- How quick and easy is that to Access Hive Blockchain Data and visualise the results?
For the rest of this series I am going to be using some advanced features of R built around Accessing Public Blockchain/ Crypto Data, and Visualising it. If you want an introduction to R you can visit my 9 part Tutorial series which I had written for Steem but and please ask if you have any questions. (links at the bottom)
If the BBC.com was publishing this Picture what would it look like?
Just to show how cutting edge this tool can be, we can style the Graph with the BBC theme.
ggplot(trending, aes(x=votes))+geom_histogram() + bbc_style()+ggtitle("Trending Hive Posts")
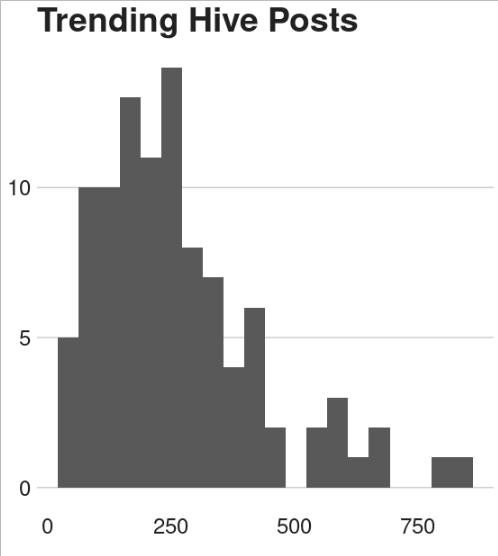
Thats right the BBC actually use R for publishing Content. All their Graphs are produced using R and this package. No more work for Graphic Designers at the BBC :)
Upcoming Posts
I am planning on covering in the next few posts in this series the following topics but I am open to feedback and requests.
The hiveRdata package
A Post focusing on the hiveRdata package and the Rich Data Available directly from the Hive Blockhcain.
Using The Coingecko API for Crypto Market Data.
Another Type of Blockchain Data which we will access with R is data from Coingecko, Price Data and Trading Volumes for all coins listed on Coingecko and of course Hive. We might even do a comparrison of Steem and Hive!
Accessing Coinmetrics Blockchain Data
This post will focusing in on accessing more general Blockchain Activity Data from Coinmetrics.
A Shiny Web App to Analyse Crypto Price Data
The last post in this series I have planned will focus on building a Visual Analytics App for Crypto Price Data. The ease of building these webapps is one of the reasons why R is my go to language today. It brings Data to life and there are endless possibilities and extension packages from R to play with.
Write your Thesis with Real Data
The title of the post alludes to how you can make projects or demonstrations real with real data from the Blockchain. Forget about dull generic work with simple clean unimaginative data. If you are looking for something original use the blockchain.
- In the comments please share some ideas of where you can swap out standard common datasets with real world Blockchain Datasets.
Credits
Winter vector created by macrovector - www.freepik.com
R 101 Series - For people begining with R
- https://hive.blog/@eroche/introduction-to-r
- https://hive.blog/@eroche/finding-your-way-around-r
- https://hive.blog/@eroche/scraping-web-data-with-r
- https://hive.blog/@eroche/data-wrangling-with-r
- https://hive.blog/@eroche/time-series-with-r
I did do an online course about R, but didn't get too deep into it. I have been investigating Hive data with HiveSQL, beem and Python. There's lots we can do with so much data. Have fun!
Just wondering, would you know of or have or be interested or have time to code something that looks up engagements between two accounts, eg if I wanted to pull up all comments and replies between you and me, and the top 20 people an account engages with. I know the latter is definitely possible as abh12345 does it as part of the Monthly Hive reports he runs for people.
I couldn't code to safe my life, so am turning to the clever folks who can ^_^
Is it weird that I like these challenges :)
See does this give you what you need in terms of comments
https://eroche.shinyapps.io/HiveEngagement/
Ill tackle the second part too but it will take a little longer.
Damn it!!! You are slick!!!!
And that search box is really good!!!!